

从0开始搭建一套可用、可扩展的知识库,不只是技术活,更是认知与业务的协同工程。本文将从需求拆解、内容结构、标签体系到运营机制,系统梳理知识库搭建的关键路径,帮助你构建真正支撑智能客服的“知识引擎”。

我设计的第一个AI产品是智能客服系统,下面介绍一下,怎么选择开源平台、大模型,以及搭建智能客服系统的知识库怎么构建。
一、选择开源平台
我们主要在Coze和Dify这两个平台选择。
Coze:操作简单,交互性好,海外版本还能调佣GPT 4.0,插件系统、记忆库、工作流等功能。但是,知识库仅支持 6000token,对于处理长文本或大量数据的场景而言,可能远远不够,主要面向标准化 Bot 开发,复杂任务扩展性较弱,仅支持云端部署,无法满足本地部署需求。
Dify:国内大部分模型都能接入,可集成多种API接口,支持多种部署情况。但是操作有一些复杂,需要具备一定的开发知识,用户体验欠佳。
由于我们的数据涉及一部分敏感,所以需要本地化部署,并且有专门的技术人员负责此事,所以我们选择了Dify。
二、选择模型
模型主要分析了文心一言、千问、deepseek、混元四个。
- 文心一言:多模态能力突出,支持文本、图片、音频、视频。但是在逻辑推理和跨领域知识融合时,缺乏连贯性。
- 千问:应用场景广泛,具备多轮对话、文案创作、逻辑推理等能力,可用于客服系统、会议纪要实时转录等场景。但是高难度推理任务效率低。
- deepseek:推理能力较强,在数学和编程等需要长逻辑链条的任务中具有优势,能处理复杂逻辑问题。支持多语言,兼容性好、集成性好。但是存在安全风险和隐私风险。
- 混元:具有强大的创作能力,支持文生视频、图生视频等多种视频生成能力。但是对于特定领域的专业性和深度不够。
因为我们要做一款客服系统,需要多轮对话,一定的推理能力,所以最后选择了千问。
三、业务需求分析
1、拆解核心业务场景
通过历史咨询记录分析,识别高频咨询场景(占比 65%)、复杂业务场景(28%)和应急场景(7%),确定优先解决的问题领域。
2、明确业务指标
设定转电话客服率≤70%、常见问题覆盖率≥80%、首次响应时间≤15 秒等可量化目标。
3、梳理主要问题
按问题划分主要分为登录前和登录后。
登录前主要询问登录时遇到的问题,如:如何登录,收不到验证码怎么办等,还有关于系统功能的咨询,如:系统能做什么,为什么要登录系统等。登录前用户只能询问10个问题。
登录后主要回答办理业务遇到的问题,如:办理A业务需要什么资料,有哪些流程。为什么我不能填写等。
四、编写FAQ
基于客服人员的历史问答,整理300+的问题对。
在编写FAQ时,需要注意的点有:
1、结合使用场景,去梳理问题
2、问题的设计要符合用户的语言习惯,如:下载时,无法使用扫码比扫码功能失败更符合用户提问的习惯。
3、答案要简洁清晰,尽量控制在3-5句话,复杂的可分点列出。
4、定期更新,每天监控智能客服回答情况,及时总结常见问题,丰富FAQ。
5、分层设计,对于命中知识库问题,直接给出答案;对于复杂问题,可提供初步方案,然后引导电话咨询;敏感问题,直接拒绝回答,避免法律风险。
五、将常见问题导入知识库
Dify的问题导入有两种方式:通用和父子分段。
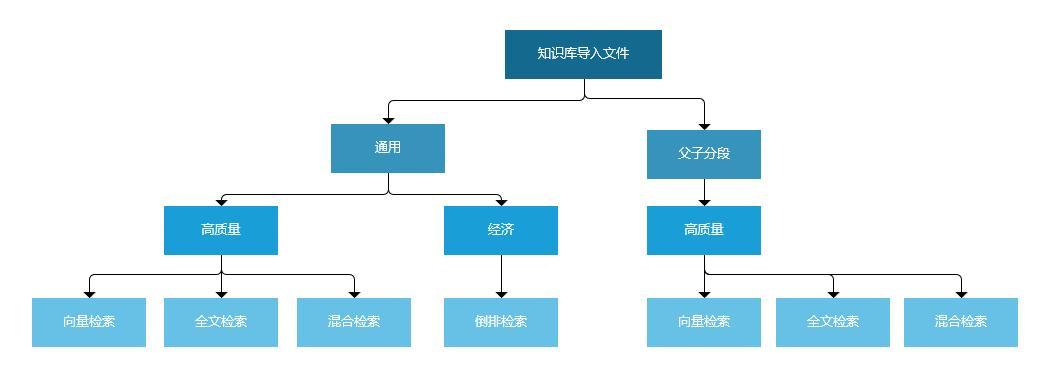
通用模式主要将文档拆分成为独立的扁平片段,以分段本身作为检索单元,可能割裂跨片段逻辑,上下文完成性较差。通常适用于社交媒体内容、用户评论等碎片化内容。
父子模式主要采用数级层级结构,由父快和子块组成,子块作为检索单元,然后将字块关联的父块全文返回。通常适用于技术文档、产品手册、法律条款等。
由于我们客服系统包括用户手册,法律规范,常见问题等文档,所以最后选择父子分段的模式导入。
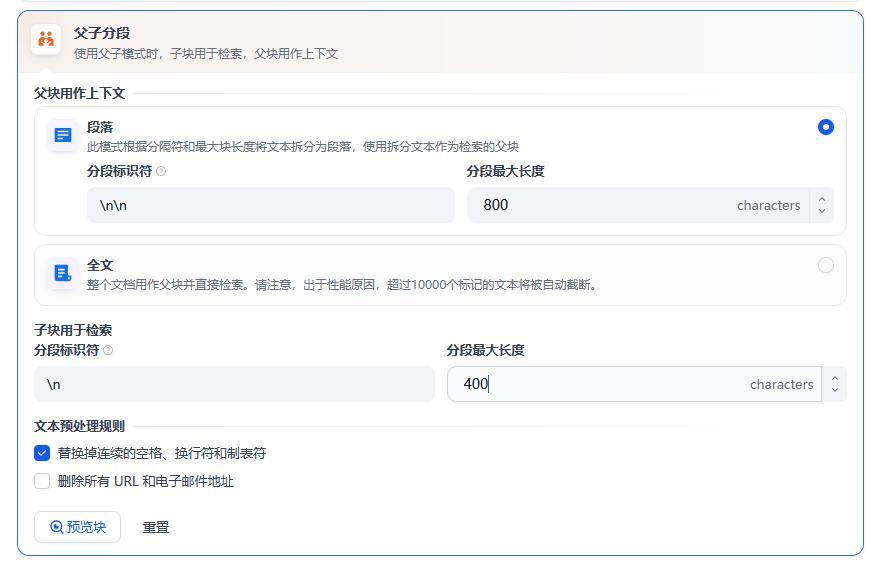
父块作用上下文选择:
- 段落是指,文档篇幅较长且段落相对独立,每个段落有明确主题时,适合选择段落作为父块上下文。
- 全文是指,文档文本量较小,且段落间关联性很强,需要完整检索全文来理解内容时,可将全文作为父块。
因为是智能客服,我选择的是段落。
段落的最大长度设置为800,子块用于检索的分段最大长度设置为400。主要是根据常见问题的字数进行设置的,确保每个问题的 “提问 + 回答” 完整在一个片段内。如果后续发现某个完整的问答或操作步骤被拆分,再适当增大数值。
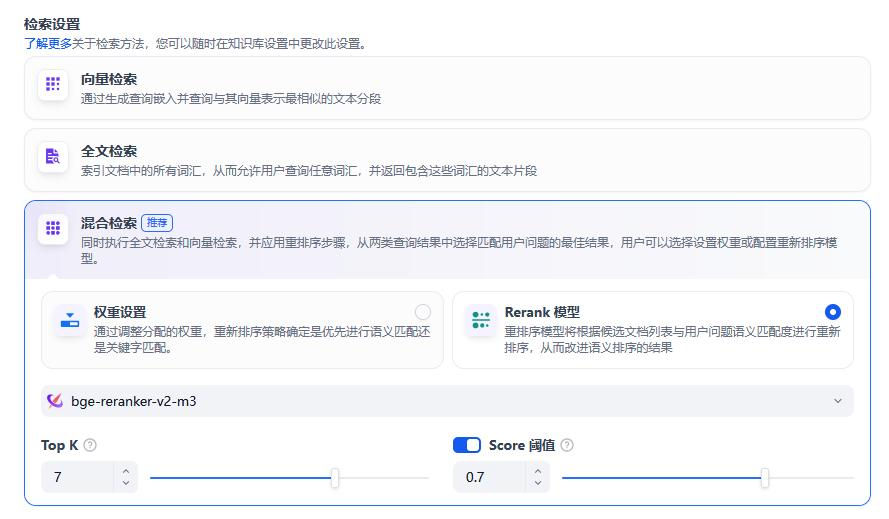
检索设置上,选择混合检索。向量检索对关键词识别精准度较低,如用户输入错别字可能匹配偏差,全文检索会严重影响检索精准度和问答效果。
Remark模型,是初步检索到候选片段后,用专门的模型对这些片段再次打分,重新排序,进一步提升 “最相关片段” 的排名。比较适合我们现阶段。
Top K设置7,因为我们又有常见问题又有操作手册,所以取中间值7。
Score阈值设置成0.7,虽然我们只客服系统,精准度比较低,但是我们涉及政务的回答,还是需要精准回答的,避免法律风险,所以把Score阈值设置成0.7,后续再根据用户反馈,对这个阈值优化调整。
六、词库维护
设置相似词、专有词、提高NLP识别率;维护停止词,设置回答红线,减少幻觉产生。
以上都是基于Dify搭建的智能客服的知识库,之后我会在更新如何去编排流程以及流程中各种参数如何设置。
本文由 @设计Zan 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议














