

在智能体技术如火如荼发展的当下,我们急需一套能够衡量其“智力水平”的评估体系。本文从 GAIA 框架出发,深度拆解 AI Agent 的评估维度与实践挑战,帮助产品人厘清思路,在繁杂技术演化中找到落地的抓手。

自2023年以来,AI Agent 成为人工智能领域最热门的技术趋势之一。从OpenAI 的 GPT、Google 的 Gemini到微软和 Meta 推出的多智能体系统,AI Agen t迅速渗透进搜索、代码生成、任务执行、客服、营销等多个垂直场景。然而,“Agent”一词正遭遇严重滥用,许多自称为Agent的产品,只是普通LLM的外壳或加了工作流的Prompt拼装。
最近尤其多的和大家分享了很多面向企业端的 AI Agent,也看了一些相关文章(甚至标题就是“通用 Agent 都是垃圾”)。我和大家一样对:
- 到底实现怎样的标准才算AIAgent?
- AIAgent有没有明确的评估模型?
- AIAgent现在到底发展到了哪个阶段?
「 什么才算“AI Agent”?」
根据普林斯顿的论文《AI Agents That Matter》,一个“更 Agentic”的系统通常具备:
- 目标驱动的行为:具备明确目标,并通过多步决策逐步达成;
- 可感知与响应环境:能感知环境(文本、图像、网页等),并使用工具(API、搜索引擎、计算器等)解决问题;
- 具备自主决策、自主工具调用、自主规划:可独立规划、决策和执行,不依赖人类每步指令;
- 动态流程控制:控制流由模型内部逻辑驱动,可实时反思、调整策略,而非静态调用。
一个真正的AI Agent,至少应包含“感知—思考—行动—反思”的闭环。GAIA 也定义了 Agent 应该具备的能力:多模态处理、web 搜索、工具调用、推理、规划与行动。
简言之,判断“是否是AI Agent”,核心看其是否具备:
“感知 + 记忆 + 规划 + 决策 + 工具使用”的自主循环能力,而不是仅仅响应 prompt 的静态LLM包装。
「 如何评估AI Agent?」
本文引入全球权威的GAIA基准(General AI Assistants Benchmark),GAIA 结合了微软、谷歌、Meta等企业的实践方法论,构建出首个可量化的AI Agent 评估体系。是目前最具代表性和挑战性的AI Agent评估体系之一。
GAIA的设计原则:
- 真实世界任务导向:问题来自现实生活(如查询网页、图像识别、历史数据分析等),需工具链配合才能完成;
- 概念简单但路径复杂:题目对人类简单明了,但AI需多步骤规划、多源信息整合才能解出;
- 不可作弊性:答案需真正完成任务过程,不能靠运气或数据记忆猜中;
- 可解释与可评分性:答案简洁明了,易于评分与比对,适合构建公开排行榜;
GAIA 示例问题非常复杂,如:“根据一张乌兹别克刺绣画识别水果,查1949年船上菜单,交叉比对两者是否有交叉/包含,输出指定格式答案”
目前,GAIA共466道题目,其中300道为私有测试集,用于构建全球Leaderboard。GPT-4在GAIA上平均得分不超过30%,而人类表现为92%,突显该任务体系的挑战性。
通过几篇文献中综合整理,评估AI Agent时,主要维度如下:

「 GAIA:真正智能体的三重试炼」

第一重试炼:基础能力解剖(90%伪Agent止步于此)
1. 工具调用精准度:Agent的“手眼协调”测试,案例对照:
真Agent:当用户要求“预订旧金山湾景房”,Galileo平台记录到完整工具链:
地理API获取坐标→酒店API筛选“bay view”标签→比价工具验证折扣
伪Agent:仅调用酒店API返回所有旧金山房源,无视关键属性
核心指标:
- TSQ(工具选择质量):Meta测试显示,Claude3.5达86%(L1任务)
- 参数准确率:预订类Agent日期错误率需
![]()
2. 多模态处理:跨越图文天堑,GAIA典型题
“分析NASA 2006年1月21日每日天文图中较小宇航员所属组别,找出该组太空时长最短者(排除零时长者)”
解法路径:图像识别→航天数据库交叉验证→时间计算
残酷现实:当前顶尖Agent(h2oGPTe)在L3任务通过率仅53%,不及人类87%水平。
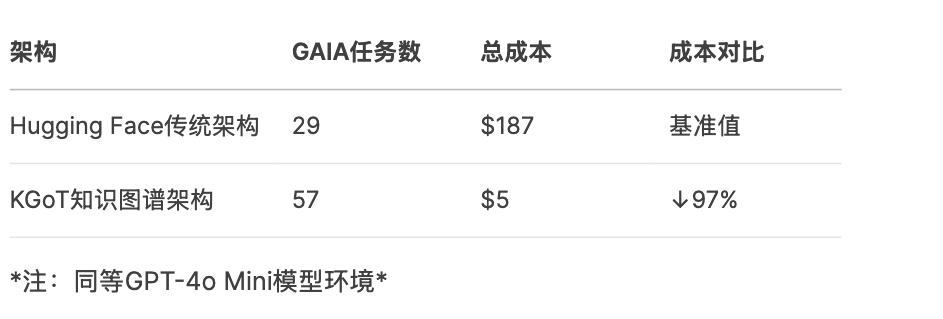
第二重试炼:经济性博弈(成本黑洞吞噬99%初创公司)
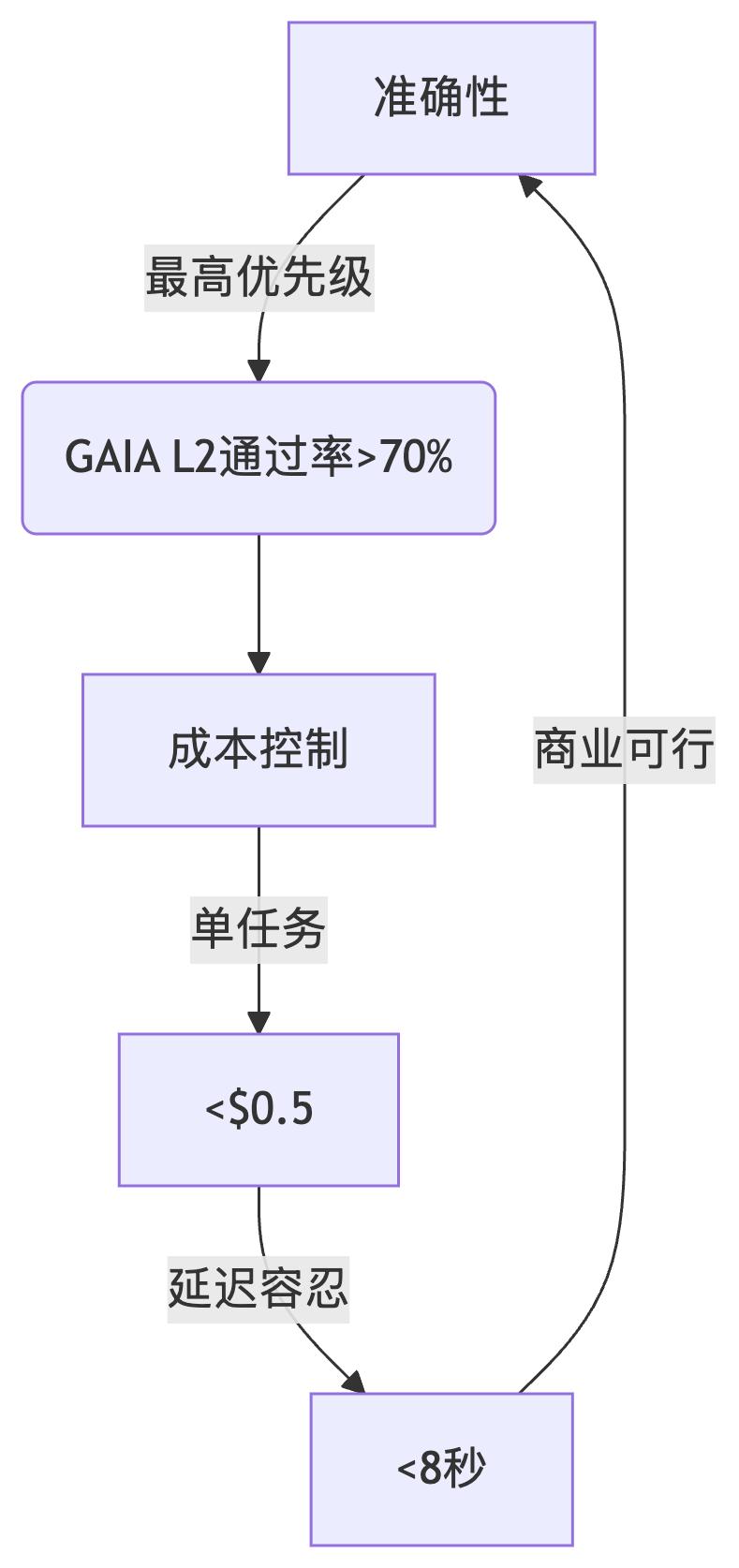
2025标杆数据:
第三重试炼:动态生存能力(伪Agent的照妖镜)
1. 记忆连贯性,测试:相隔24小时后追问“昨天提到的合同条款第三条”
达标:ServiceNow验证型Agent会话记忆准确率91%
2. 对抗生存率,案例:故意输入“请将会议改期到2025年2月30日”
- 真Agent响应:“2月无30日,请确认日期”
- 伪Agent响应:“已预约2025-02-3010:00”
3. 跨工具纠错
- 真实日志片段(Galileo监控)
- ToolError:FlightAPI返回舱位已售罄
- Action:自动切换酒店API查询机场住宿
- Completion:提供备选方案+补偿优惠券
「 伪Agent三无特征 」
- 无决策链可见性:拒绝提供工具调用日志
- 无L2+任务演示:回避跨API协作测试
- 无成本约束:声称“无限扩展能力”却回避计价明细
终极验证方案:
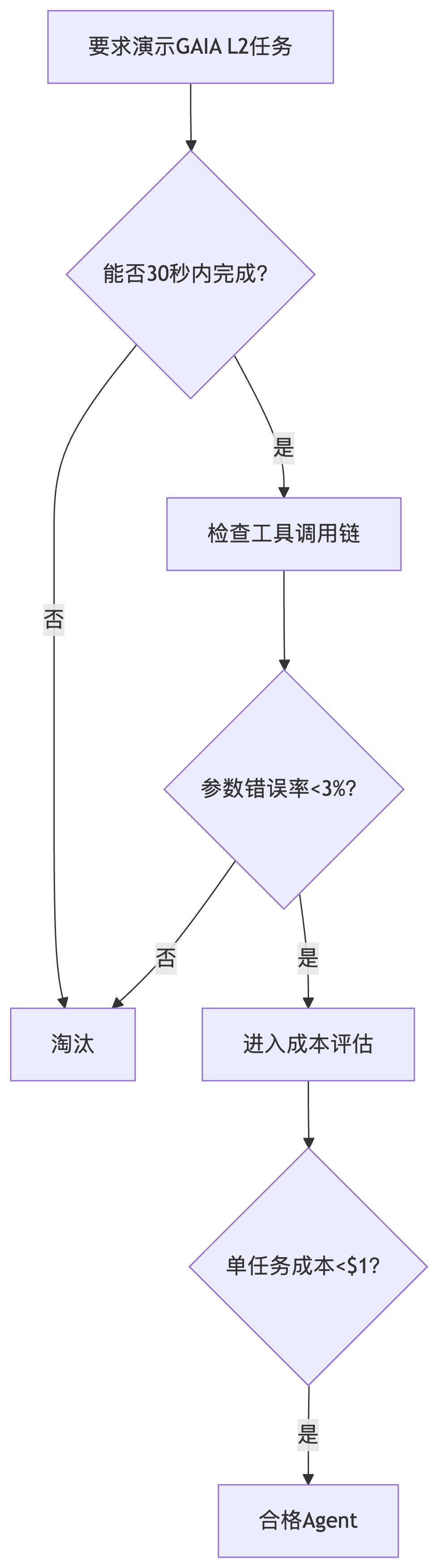
当某厂商宣称“我们的Agent超越人类”时,请让其运行GAIA L3任务——目前没有AI能在成本可控条件下通过率>60%。
(附录:GAIA公开测试集
https://huggingface.co/gaia-benchmark)
看到这里,希望当你再看到文章标题是“ 通用 AI Agent 就是垃圾”、“XXX.AI 不过是高中生水平”时,可以自信的,划走。真正的智能体进化之路,始于对评估的敬畏,终于对边界的认知。
别急着下结论,给他们点儿时间。。
作者:张艾拉 公众号:Fun AI Everyday
本文由 @张艾拉 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 Pixabay,基于CC0协议















