

你真的了解“AI味”的判定逻辑吗?它是算法的偏见,还是内容的共性?本文将带你深入解析“AI率”的计算机制、平台标准与背后隐忧,揭示那些让人“闻风丧胆”的AI痕迹如何影响内容生态与创作自由。

“AI ”的存在感,你是怎么感知到的
当你刷到光影略显诡异的人物视频赫然在目,长得异常完美却略显油腻,动态深情明显不对的美女视频,你会自然的判断 —— 这大概率是 AI 生成的内容;

当你刷到一篇观点看似流畅却毫无个人锋芒的推文,论据排列工整却缺乏逻辑转折,读起来像流水线产品 ,你读了感觉知识穿过了你的脑子,却没有留下什么深刻的印象和观点,这大概率是一篇 AI 直出的文章
如今,AI 生成内容早已渗透到生活的角角落落,豆包日均使用情况来看,每天可以产出数万篇文章和图片,生成效果提高的同时,你能看到文章质量和图片效果的提升,但是你仍能感觉到这是 AI 生成的,“AI 味儿” 是人们下意识的判断,而对大学生来说, 论文的“AI 率” 查重,降重降 AI 成了毕业的头等大事。
AI 到底怎么被人看到和识别出来。今天,我们就来好好聊聊这两个话题。
图片与文章里的 “AI 味儿” 有何不同?
图片生成的 “AI 味儿”:细节的 “违和感” 是关键
在人像领域,AI 生成的图片常常在 “精细处露马脚”。某约稿平台上经常发生这样的鉴别 AI 场景,单主约了画师进行绘画创作之后,乍看之下绘画内容精致,实际上却有一些让人怀疑的点,比如发丝的衔接不自然,衣服的褶皱不符合物理走势,部分光影的呈现让人别扭,很多人看着难受说不出个所以然,就只能和画师要绘画过程,其实这些内容的真实就藏在风格的统一与绘画的细节里。例如放大之后的像素低,噪点分布奇怪。
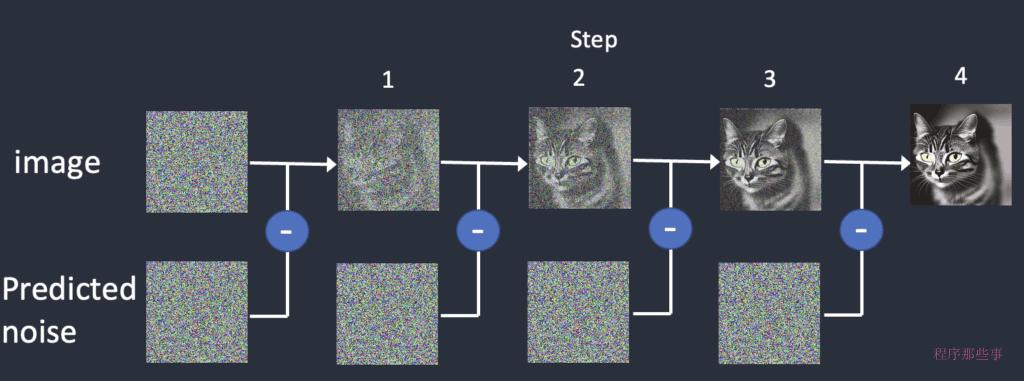
图片细节“违和感”的来源
这其实由于生图的原理是降噪。降噪就像给模糊的照片 “磨皮”,AI 生图时先随机画一堆杂乱的像素点(类似电视雪花),再一点点去掉多余 “噪点”,让画面变清晰,但偶尔会把该保留的细节也误删,导致放大后模糊或出现奇怪纹路。而不是像人一样先构思再进行绘制,这也是为什么即使不成熟的画师会出现衣褶的逻辑错误,但是不会让你觉得是 AI 绘画而是画错了,这正因为AI 降噪的随机性。
而资深画师的动漫作品,角色的服装细节、配饰位置会贯穿始终,颜色会随光影自然渐变,像大家常提的藏色技巧其实 AI 学习的就有一些拙略。比如《海贼王》的插画里,路飞的草帽无论在晴天还是暴雨中,草编的纹理、磨损的边缘都保持一致,颜色只会因光线强弱产生明度变化,绝不会突然 “变色”。
动漫行业分析师研究报告表明,在对热门动漫作品的 1000 组连续插画分析中,人类画师创作的作品角色细节一致性达 99% 以上,色彩光影过渡自然流畅;而对相同数量 AI 生成动漫作品分析发现,仅 30% 能保持角色细节一致性,50% 存在色彩突变问题。日本动漫协会相关专家指出,AI 在处理动漫角色多帧画面时,缺乏对角色整体设定的深度理解与连贯记忆,导致这类问题频发。
文章的 “AI 味儿”:逻辑的 “平” 与表达的 “空”,没有灵魂
不少网文编辑都有过被 AI 投稿 “轰炸” 的经历。在某网文平台,一段时间内收到大量疑似 AI 生成的小说投稿。其中一篇小说,开篇用大段文字描写主角身处的环境,诸如 “房间里,华丽的水晶吊灯洒下柔和却又带着几分神秘的光,映照在古色古香的书架上,书架上摆满了各种泛黄的书籍,散发着岁月的气息”,一句话中堆砌了众多形容词,却没有与后续剧情建立有效关联。
对比真实作者创作的文章,即便文笔稚嫩,也会围绕一个核心观点或故事脉络,逐步展开叙述,融入自己的思考与情感。
例如在讲述个人旅行经历时,会详细描述旅途中遇到的突发状况,以及当时内心的紧张、惊喜等情绪变化,穿插当地独特的人文景观与个人感悟,使读者能感同身受。而 AI 生成的文章在表达情感时,往往使用一些通用的、宽泛的词汇,缺乏具体情境下的深度刻画,就像描述一场美丽的日落,可能只是简单地说 “那日落美得让人陶醉”,却没有描绘出日落时分天空色彩的渐变、霞光洒在身上的温暖触感,以及面对此景内心涌起的对自然之美的敬畏等细腻情感。
有文学研究机构针对 AI 生成文章与人类创作文章进行对比分析,从情感词汇丰富度、情节逻辑性、观点独特性等多维度评估,结果显示 AI 生成文章情感词汇丰富度仅为人类创作文章的 40%,情节逻辑性连贯度低 30%,观点独特性更是相差甚远 。文学评论家在学术研讨会上也多次指出,AI 缺乏真实生活体验与情感认知,难以产出有深度、有灵魂的文章。
AI 生文“车轱辘话”的来源
语言大模型写文章的技术原理较为复杂,核心在于基于 Transformer 架构的深度学习模型。它先经过大规模预训练,将海量文本数据转化为数字形式输入模型,模型中的神经元通过构建复杂网络结构,对文本中的词、句、篇章关系进行学习。例如在处理 “我喜欢草莓” 这句话时,模型会分析 “我”“喜欢”“草莓” 这些词汇之间的语义关联以及在语法结构中的位置关系。在这个过程中,模型通过不断调整神经元之间连接的权重,来优化对语言模式的理解,比如掌握不同词性词汇搭配的概率,像 “喜欢” 后面接名词的概率较高,且 “草莓” 作为常见被喜欢的事物,与 “喜欢” 搭配的概率在其学习的语料库中有相应体现。
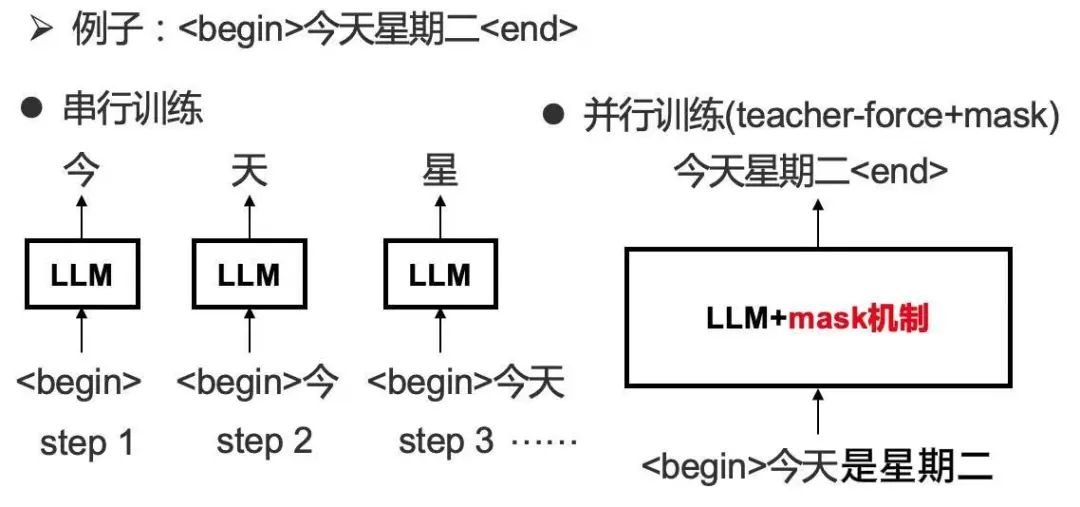
当接到写文章的指令,如 “写一篇关于旅游的文章”,模型会将指令转化为内部可理解的向量形式,然后从第一个词开始预测。
它会基于之前学习到的语言模式,计算下一个最可能出现的词的概率分布。假设模型已经输出了 “旅游”,那么接下来预测下一个词时,它会参考训练数据中 “旅游” 后面常见的词汇,比如 “是”“可以”“能” 等词出现的概率,选择概率较高的词输出,然后再以上一个词和新输出的词为基础,继续预测下一个词,逐步生成完整的句子、段落,直至完成文章。这个过程就像一个人在脑海中搜索词汇,依据以往积累的语言经验来组织语句,但它没有真正理解旅游的实际体验和情感内涵,只是按照数据中的概率模式来拼凑内容 。
四、大学生的 “紧箍咒”:论文 AI 率是怎么算出来的?准吗?
1. AI 率的计算逻辑:比对与概率判定
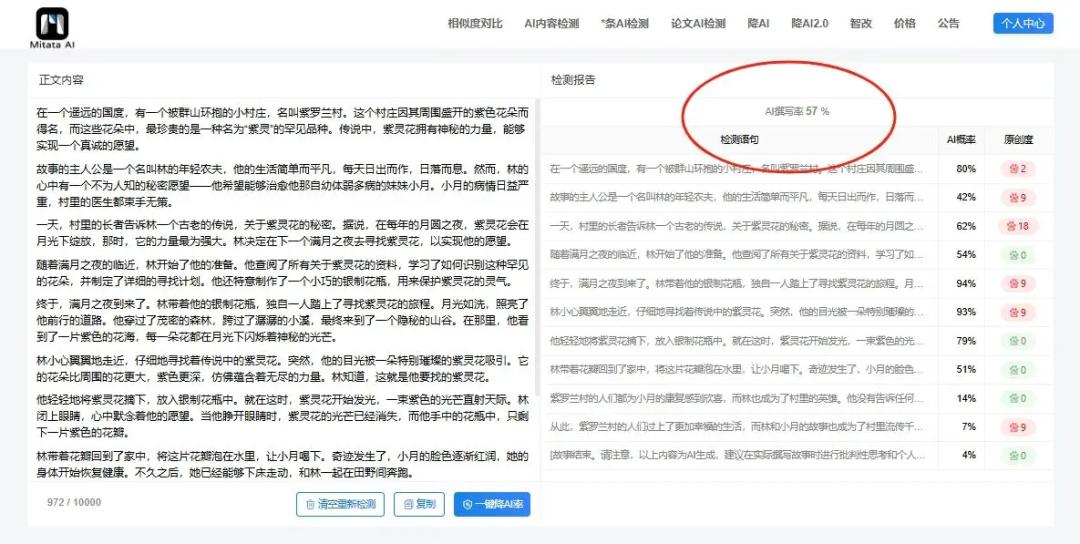
目前高校常用的论文 AI 检测工具(如知网 AI 检测、Turnitin AI 检测等),原理和内容查重类似,但比对的对象从 “已发表文献” 变成了 “AI 生成内容的特征库”。
工具会分析论文的语言风格:比如句子长度的规律性、词汇的重复率、逻辑转折的自然度等,再将这些特征与已知的 AI 生成文本特征进行比对,计算出文本中 “符合 AI 生成规律” 的部分占比,这就是所谓的 “AI 率”。
2. 准确率争议:误判与 “反检测” 的博弈
但 AI 率的准确性一直备受质疑。一方面,有些学生的原创论文因为语言风格过于规整(比如逻辑严谨、用词规范),可能被误判为 “高 AI 率”;另一方面,网上流传着各种 “降 AI 率技巧”(如故意打乱句式、替换生僻词),可能让 AI 生成的内容逃过检测。
此外,AI 技术本身在不断进化,新的生成模型可能会模仿人类的 “不完美”,让检测工具难以识别。因此,多数高校会将 AI 率作为参考,而非唯一标准,最终还会结合导师的人工审核来判定论文的原创性。
我看了一下 loki 近期更新的 gpt5 测评,那一篇里其实短文写的就非常非常接近真人文笔,除了少了一些特定的写作风格和用语,如果不告诉其他人,几乎无法察觉。
五、技术对抗:有哪些工具能识别 AI 生成的内容?
1. 文本检测工具:各有侧重,各有局限
- 知网AI检测:高校常用,侧重学术文本,能识别主流大模型(如GPT、文心一言)生成的内容,但对小众模型的检测能力较弱。
- Originality.ai:商业化工具,支持多语言检测,准确率较高,但需要付费使用。
- GPTZero:免费工具,主打“识别GPT生成文本”,通过分析“困惑度”(文本的不可预测性)判断是否为AI生成,适合初步筛查。
2. 图像检测工具:揪出细节里的 “马脚”
- HiveAI:能分析图像的元数据(如是否带有AI生成的数字水印),同时检测像素分布的异常(如边缘模糊、细节矛盾)。
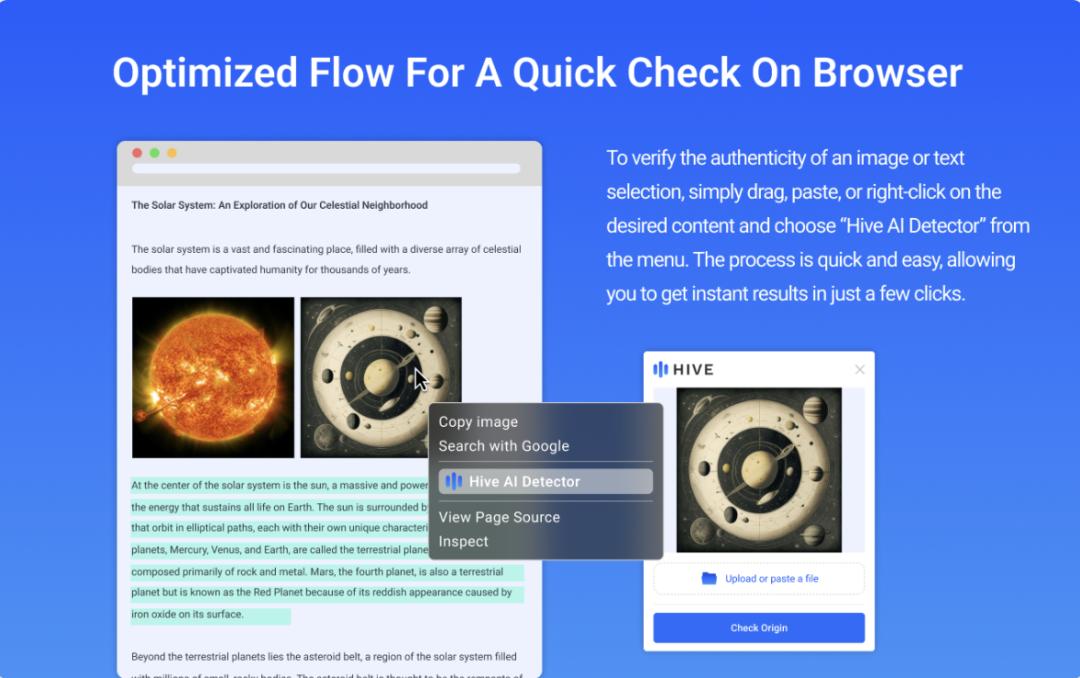
- Sensity:专注于深度伪造图像识别,尤其擅长检测AI生成的人脸,能发现瞳孔反光、皮肤纹理等细节的不自然之处。
- 谷歌AIImageDetector:免费工具,通过分析图像的“噪声模式”(AI生成图像的噪声分布与真实图像不同)进行判断,适合普通用户快速验证。
思考才是内容的灵魂
“AI 味儿” 的存在,本质上是 AI 技术尚未完全成熟的表现,大语言模型的推理方式天然就存在着和人不一样的地方,因为大脑是复杂且精密的,看似检测出的电信号实则可能是灵感的涌现;
而 AI 率的争议,则反映了技术应用与教育公平的博弈。对论文作者而言,AI 率终起原因,也只不过是用一种形而上的技术,去解决另一种形而上的问题,这其实品起来还有一种荒诞的意味,我们怕的到底是创作出来的无效内容,还是想要优秀创作者的耕耘与创作,我们的教学体系中的天然存在的问题应该何去何从,论文该是检验是否能毕业的标准吗?可能在多年以后,会有新的答案。
毕竟,真正有价值的内容,永远带着人类独有的思考。
本文由 @人工智能怨气指南 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务














