本文由上海交通大学,上海人工智能实验室、北京航空航天大学、中山大学和商汤科技联合完成。 主要作者包括上海交通大学与上海人工智能实验室联培博士生康恒锐、温子辰,上海人工智能实验室实习生文思为等。通讯作者为中山大学副教授李唯嘉和上海人工智能实验室青年科学家何聪辉。
AIGC 技术狂奔的脚印后,留下的是满地信任残骸
近年来,文生图模型(Text-to-Image Models)飞速发展,从早期的 GAN 架构到如今的扩散和自回归模型,生成图像的质量和细节表现力实现了跨越式提升。这些模型大大降低了高质量图像创作的门槛,为设计、教育、艺术创作等领域带来了前所未有的便利。然而,随着模型能力的不断增强,其滥用问题也日益严重 —— 利用 AI 生成的逼真图像进行诈骗、造谣、伪造证件等非法行为层出不穷,公众正面临一场愈演愈烈的信任危机。
(图源自知乎和多家微信公众号)
不信?猜一猜下列图片中哪些是真实的,哪些则是由 AI 合成伪造的?






(左右滑动查看)
答案是:这些图像全是伪造的。
若只是匆匆一瞥,你很可能会毫不察觉 —— 它们几乎天衣无缝。这正是得益于近年来文生图技术的突飞猛进,AI 生成内容已逼近真实。然而,正因如此,公众在毫无防备的情况下被误导的风险也在加剧。面对真假难辨的图像,信任成本正悄然上升,焦虑与不安也随之而来。

- 论文标题: LEGION: Learning to Ground and Explain for Synthetic Image Detection
- 作者团队: 上海交通大学、上海人工智能实验室、 北京航空航天大学、中山大学和商汤科技
- 项目主页: https://opendatalab.github.io/LEGION
- 关键词: 伪造检测、伪影定位、异常解释、引导图像优化
那么我们该如何破局?在 ICCV25 highlight paper《LEGION: Learning to Ground and Explain for Synthetic Image Detection》中,来自上海交通大学、 上海人工智能实验室等组织的研究团队从构建高质量 AI 合成图像数据集、设计可解释伪造分析模型、实现检测与生成的对立统一这三个角度给出了他们的答案。
破局基石:开创性数据集成就伪影图鉴

该团队反思了现有伪造图像数据集的局限性,并且构建了首个针对纯 AI 合成图像,可进行全面伪造分析的数据集 SynthScars,直击现有顶级生成技术的缺陷与 “伤疤”,让看似完美的 AI 图像显露真容,为图像安全研究注入新动力,主要具有以下亮点:
- 全网顶配生成器:
部分图像来自最新的 AI 创作平台,集齐了 FLUX、SD 系列、各种商用 API 及特定 LoRA 微调后的最新文生图模型,几乎不含 “一眼假” 的老旧低质的伪造图像
- 专杀超现实画风:
系统性过滤动漫、插画等艺术风格图像,这类样本虽常见但误导性低;数据集中仅保留逼真程度高、最具欺骗性的超现实风格图像,聚焦人类最难分辨的 “视觉死角”
- 三维解剖级标注:
每张图像均附带伪影掩码、异常解释与伪影类型标签三类信息,系统覆盖三大伪影类型:物理矛盾、结构畸形、风格失真,支持定位、诊断与归因的全流程分析
- 去轮廓依赖魔咒:
摒弃依赖物体边界变形的传统篡改范式,专注捕捉 AI 原生生成图像中非结构性、无规则分布的伪影信号,直击深层次建模缺陷遗留的 “蛛丝马迹”
核芯武器:多模态大模型重塑分析范式
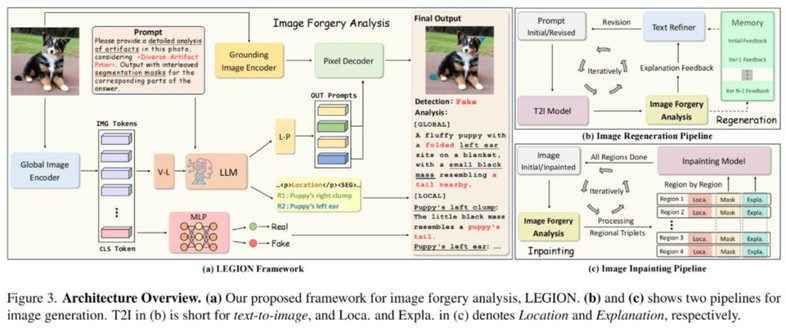
作者提出了一个基于多模态大模型(MLLMs)的图像伪造分析框架,主要由全局图像编码器、定位图像编码器、大语言模型、像素解码器和检测分类头组成,能够实现:
多任务架构统一:
伪造检测 + 伪影定位 + 异常解释三位一体,同步完成,无需零散专家拼凑实现。
伪影定位任务在 RichHF-18K 等 3 个数据集上进行了测试,结果如下:
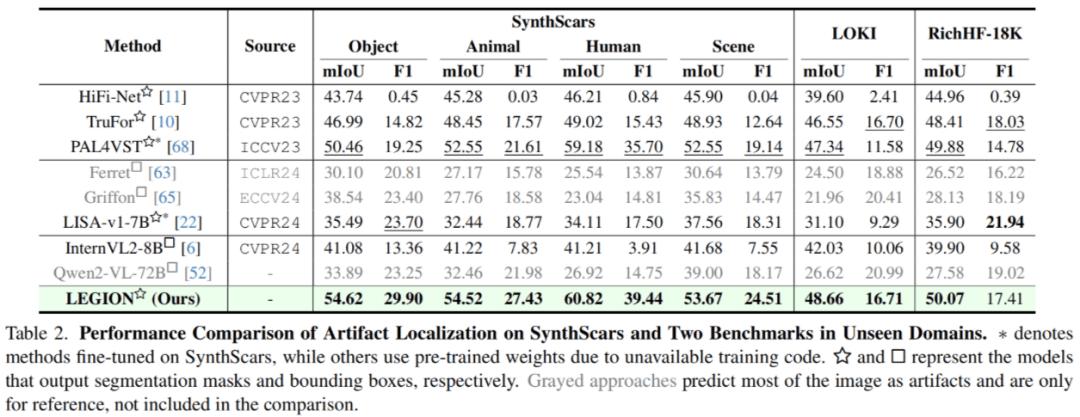
作者指出,现有的一些通用多模态大模型,如 Qwen2-VL 在面对此任务时倾向于预测图片的绝大部分(有时是整张图片)为伪影,这是毫无意义的,这说明了现有 MLLMs 缺乏相关知识和能力。
异常解释任务在 LOKI 等两个数据集上进行了测试,结果如下:
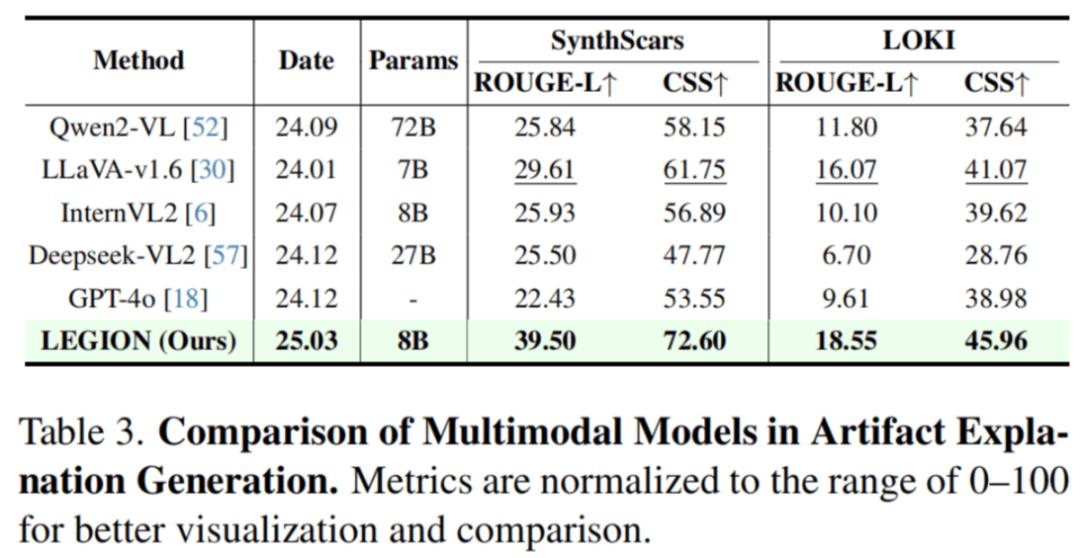
LEGION 仅用 8B 参数量就能够在异常解释任务中打败其他同等甚至更大规模的模型。作者还指出诸如 Deepseek-VL2/GPT-4o 这样的模型会输出看似全面的各种可能性,但实际上会导致答案冗杂,评分偏低。
伪造检测任务选择在 UniversalFakeDetect 基准上进行测试:
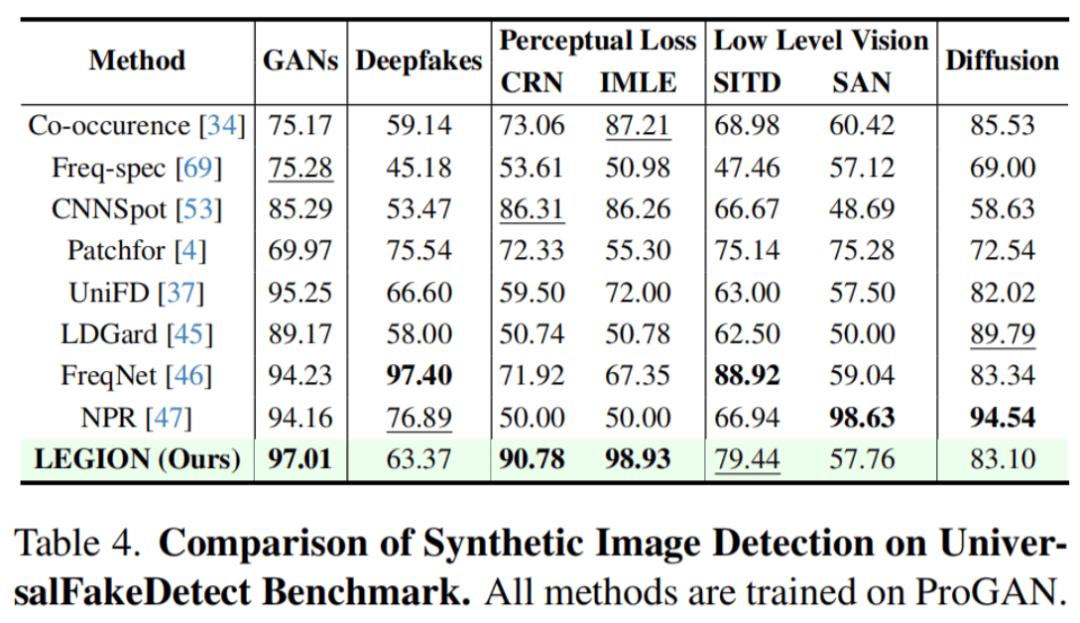
卓越的鲁棒性:
作者尝试了高斯噪声攻击、JPEG 压缩失真和高斯模糊三种干扰处理,发现 LEGION 性能相较于传统专家模型而言波动较小,具有更强的鲁棒性:
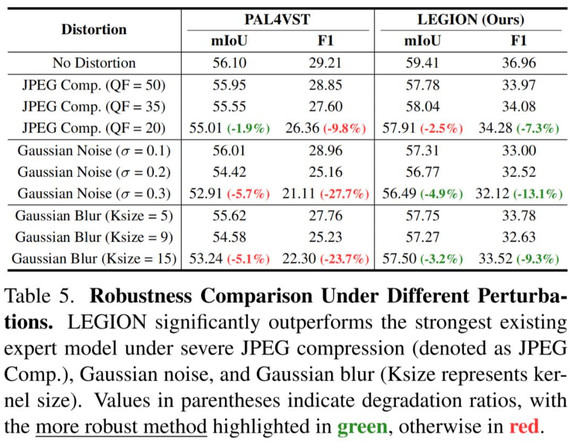
可解释性飞跃:
与传统专家模型仅给出真伪判断不同,LEGION 除此以外还利用视觉掩码直击 “造假部位”,语言能力生成 “打假报告” → 不只判真假,更说清何处假、为何假、有多假!

更多的可视化示例请关注项目主页:https://opendatalab.github.io/LEGION
颠覆循环:实现检测与生成的终极共生
一直以来,合成与检测,宛如一对技术 “冤家”,在对抗中推动彼此演进。当合成跑过检测,虚假内容得以轻易伪装,真假难辨的风险骤增;当检测胜过合成,生成模型便被迫进化,朝着更高真实度与隐蔽性迈进。
因此,这篇论文创造性地提出:
LEGION 不仅可以作为图像安全的保卫者,也能是反向促进高质量生成的催化剂
为此,作者从两种不同的角度,提出了利用检测 “反哺” 生成的 pipelines:
全局提示词优化
作者指出,现有生成图片中的伪影部分来源于提示词的模糊。利用 LEGION 的异常解释文本,对全局提示词进行多轮细化后再重新生成能够有效修复一些缺陷,例如能对图片进行现实风格迁移、结构细节调整等。

局部语义修复术
另外一种思路是直接对 LEGION 检测出的伪影区域做局部修复。具体地,可以联合检测得到的伪影掩码和异常解释,利用图像修复模型针对性地消除伪影细节,这种方法的好处在于不对正常区域处理,能够最大程度的保留原图语义。
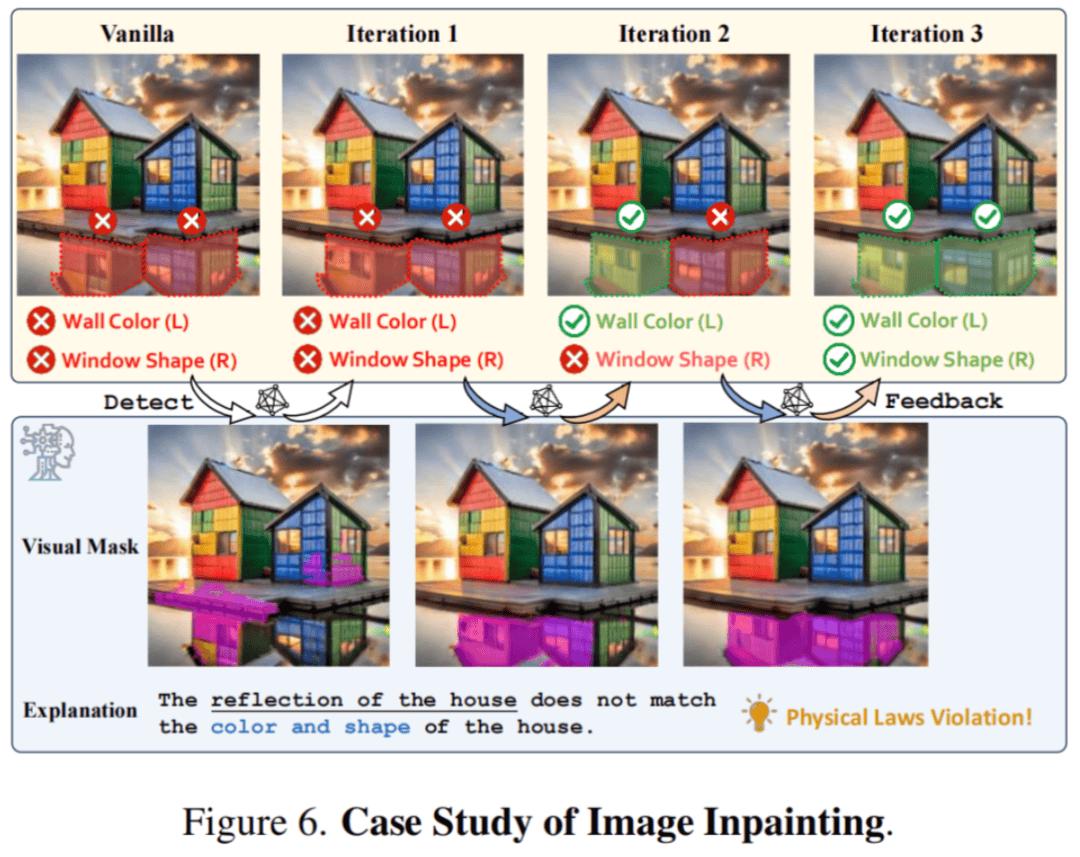
上例中,原始生成图像的伪影较为隐蔽,乍一眼看去往往会被忽略 —— 房子在水中的倒影与实际的颜色和形状不一致,这是典型的物理定律违反。通过多轮对伪影区域的局部修正,能够逐步得到更高质量、更逼真的合成图片。
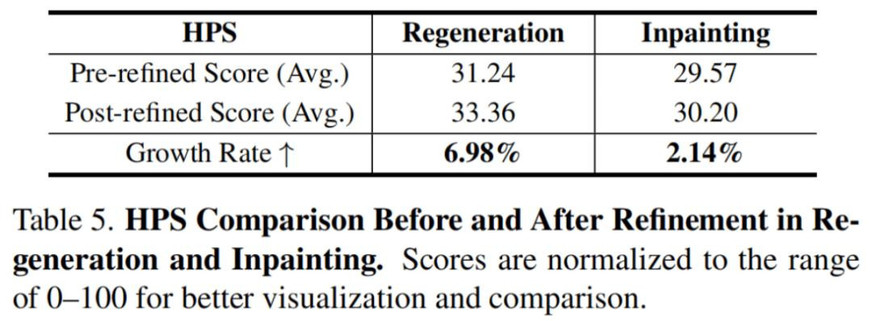
此外,我们利用 HPSv2.1 模型对应用上述两种方法前后生成的图像进行了定量的人类偏好评分,能够明显发现在引导图像优化后有较大程度的提升,这说明了用 "打假" 反哺 "造真" 的可行性和有效性。