
在人工智能发展的今天,结合大模型,使用 GenAI 可以让我们得到唯一的搜索答案,而不是传统的搜索引擎提供的多页面的搜索结果。由于企业数据或私有数据在每时每刻都在生成。大模型在缺乏上下文的情况下使用大模型来进行推理,在很多的时候会产生幻觉,因为这些知识不存在于大模型中。
在 InfoQ 举办的 QCon 全球软件开发大会(北京站)上,Elastic 中国社区首席布道师刘晓国分享了“基于 Elasticsearch 创建企业 AI 搜索应用实践”,他详细介绍 Elasticsearch 的向量搜索技术及如何使用它进行 RAG 的应用开发。
内容亮点
使用 Elasticsearch 来针对企业进行大规模的商用、规避搜索幻觉
结合大模型,使用混合搜索来得到更加精准的搜索结果
将于 10 月 23 - 25 召开的 QCon 上海站设计了「AI 搜索」专题,本专题聚焦于 AI 搜索的基础技术、前沿探索、工业界落地等方向,为听众带来一场精彩的技术分享。通过本专题,期望听众能够拓宽技术视野,从实践案例中获得启发,并在自己的业务场景中实现更智能的搜索体验。如果你有相关技术案例,欢迎加入这场技术共创。
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
在当今的数字时代,Elasticsearch 这一强大的搜索引擎技术已经广泛渗透到我们日常生活的方方面面。无论是抖音、美团、滴滴、大众点评还是微博等热门应用,它们的搜索功能背后大多都依赖于我们公司的技术支持。本次的话题是关于如何运用 Elasticsearch 的向量搜索功能来构建 RAG 应用。事实上,无论是当前的各类应用还是未来的 AI 发展,搜索都扮演着至关重要的角色。如果没有高效的搜索技术,许多功能和服务都将难以实现。
智能时代的搜索需求
在智能时代,搜索需求已经发生了显著变化。过去,我们习惯于通过词汇搜索来获取信息,例如在浏览器中使用快捷键“Ctrl + F”查找特定文字,或者依赖于百度、谷歌等搜索引擎。这些传统的搜索方式大多是基于倒排索引的,但随着用户需求的提升,我们如今更渴望实现语义搜索。语义搜索的核心在于理解用户的意图,而不仅仅是匹配关键词。例如,“我爱你”和“我想你”在语义空间中是高度相似的,甚至在多语言模型中,“I love you”和“我爱你”也具有相同的向量表示。因此,当用户搜索“I love you”时,理想的结果应该是能够找到与“我爱你”或“我想你”相关的文档。
单纯的向量搜索并非完美无缺。尤其是对于密集向量,其搜索结果往往缺乏可解释性。例如,“我想你”和“我爱你”虽然语义相近,但在某些情况下,仅依靠向量搜索可能会导致结果不够精准。因此,将传统全文搜索与向量搜索相结合,能够有效提升召回率和搜索精度。这种混合应用方式可以更好地满足用户的多样化需求。
 <!---->
<!---->模型重排序也是我们正在探索的一个重要方向。这与我们即将讨论的 RAG(技术密切相关。传统的搜索方式,例如搜索“how to set up elasticsearch ml?”,可能会搜到 “Prelert”,因为我们曾经收购了 Prelert 公司,它主要专注于机器学习领域的异常检测。然而,从语义搜索的角度来看,用户可能会期望搜索结果更贴近其原始意图,而不是仅仅关联到与 Prelert 相关的信息。
通过实际的检索案例,我们可以清晰地看到语义搜索的优势。例如,当用户搜索 “How to set up Elasticsearch ML?” 时,传统的词汇搜索可能会返回一些关键词匹配但实际内容并不相关的结果,如 “Sizing for Machine Learning with Elasticsearch”,尽管它包含了相关关键词,但并未真正解答用户关于如何设置 Elasticsearch ML 的问题。相反,通过语义搜索,结果会更加贴近用户的意图,例如 “Set up machine learning features”,这正是用户所期望的。
在当今时代,搜索不仅局限于文字,图片、声音和视频等多媒体内容的搜索也变得越来越重要。向量搜索在这些领域同样发挥着重要作用。例如,通过 CLIP 模型,我们可以将图片输入系统,即使图片中不包含文字,用户也可以通过输入描述(如“覆盖雪的山”)来找到相关的图片。此外,用户还可以上传图片进行比对,系统能够返回与之相似的图片结果。这种能力在购物场景中尤其有用,例如用户可以通过上传一张喜欢的裙子图片,找到类似的款式。对于 RAG 应用来说,我们追求的不仅仅是大量搜索结果,而是精准、高效的结果。因此,结合大模型和向量搜索,不仅可以优化排序,还能进一步提升搜索体验。
Elasticsearch 向量搜索介绍
Elasticsearch 的向量搜索功能支持两种类型的向量:密集向量(Dense Vector)和稀疏向量(Sparse Vector)。密集向量是一种低维度的向量形式,例如 OpenAI 的模型通常使用 1,536 维的向量。这种向量本质上是一个数组,能够捕捉语义信息,并且可以应用于多种模态的知识,包括文本、图像、音频或视频等。然而,密集向量搜索通常需要占用大量内存,并且在某些情况下,其可解释性较差。
与之相对的是稀疏向量。稀疏向量的特点是其大部分元素为零。例如,在一个包含三万或四万词汇的字典中,大多数匹配结果可能都是零。Elasticsearch 支持稀疏向量的一个显著优势在于,它可以广泛应用于多个行业,甚至无需进行微调即可开箱即用。无论是法律、医疗还是其他领域,这种大模型都能发挥作用。然而,如果某些模型没有经过特定领域的微调,其效果可能并不理想。
 <!---->
<!---->关于稀疏向量的实现。例如,当我们写入一个数字或一个词组,如 “droids you’re looking for” 时,通过神经网络可以将其扩展为“do Android Robot, cartoon, galaxy” 等词汇。在搜索时,搜索词也会被扩展,因为大语言模型会推算下一个词的概率。例如,如果其中一个词是 “electric”,模型可能会计算出下一个词是 “robot” 或 “Android” 的概率,并最终得出一个综合分数。这种方法可以实现文本扩充和打分,甚至可以用于语音搜索,但不太适合图像搜索。
 <!---->
<!---->Elasticsearch 向量搜索的架构如下图:我们会使用向量嵌入模型,将图像、文档或音频等数据向量化,并存储到 Elasticsearch 中,形成一个向量数据库。在搜索时,我们将文字、图像或声音通过相同的向量嵌入模型转换为数字向量,然后在存储的向量中搜索最相近的 top k 个结果,比如 100 个或 50 个。这就是向量搜索的本质。需要注意的是,向量搜索中的相似度是一个关键概念。虽然我和我的父亲、儿子之间的相似性可能高达 99.999%,但通常无法达到 100%。因此,我们通常将相似度定义为 100%(最高)到 0%(不相关)之间。向量搜索本质上是寻找向量空间中距离最短的几个结果。
 <!---->
<!---->在架构方面,我们可以通过一个工具将模型上传到 Elasticsearch 的机器学习节点。上传后,通过创建一个 Inference API,在写入数据时,系统会自动调用该 API,将数据向量化并存储到 Elasticsearch 数据库中。搜索时,系统同样会使用 Inference API 进行向量化,并通过 kNN(最近邻)搜索找到最近的搜索结果,最终将结果返回到前端。这就是向量搜索的基本框架。
 <!---->
<!---->在操作步骤方面,我们有一个名为 Eland 的工具,许多模型以 Python 形式存在于 Hugging Face 等网站上。我们可以通过 Eland 将模型直接上传到 Elasticsearch 的机器学习节点。
 <!---->
<!---->上传后,我们需要创建一个 Inference API 接口。当我们将数据写入 Elasticsearch 时,系统会将文本向量化,例如某个字段被转换为数字向量。Elasticsearch 与其他操作系统不同,它原生支持向量搜索,其向量字段是内置的,而不是通过插件实现的。目前,Elasticsearch 支持最高 4096 维的向量数据。
 <!---->
<!---->在搜索时,向量查询分为两步。例如,当我们查询 “summer clothes” 时,如果没有机器学习节点,我们需要额外调用一个 API,将查询词的向量填入查询语句,然后再进行第二次调用才能得到结果。但经过大量优化后,这一过程被简化,用户几乎感觉不到区别,就像以前一样简单。搜索时通常称为 kNN 搜索,即寻找最近的几个结果。搜索结果会附带一个评分。实际上,这是一种混合搜索,结合了传统搜索和向量搜索,但它们有不同的权重,因此可以得到一个综合的评分。
 <!---->
<!---->在 8.7 版本中,搜索变得更加便捷。你可以直接将多个 ID 或文本输入,系统会一次性完成搜索,无需分两步操作。此外,我们还可以在搜索前进行过滤。例如,一些中国厂商也在进行向量搜索,但他们可能只支持标量搜索,而无法进行全文搜索。例如,如果我希望搜索结果中包含 “women” 这个词,那么就需要进行全文搜索,否则无法实现。因此,虽然许多向量数据库正在补充 Elasticsearch 的全文搜索能力,但纯向量搜索的应用场景其实有限,其精确度也并非总是理想。
目前,Elasticsearch 提供了多种搜索方式,包括密集向量、稀疏向量和传统的 BM25 搜索。我们通过一种称为 RRF 的方式进行综合评判。向量搜索的分数通常在 0% 到 100% 之间,而传统文本搜索的分数可能是 10、20 等,两者的分数并不一致。因此,当我们将两者结合进行多路召回时,需要一个混合的评判分数来确定结果的排序。例如,我们可以根据数据集的特点,为文本搜索和向量搜索分别赋予不同的加权值,从而更好地满足搜索需求。
<!---->Elasticsearch 提供了一种非常独特且强大的混合搜索功能,这与许多其他厂商的设计截然不同。它能够支持多字段的 kNN 搜索,同时结合传统搜索方式,这种混合模式被称为上下文组合。如果对数据集有深入了解,我们可以根据需要对不同搜索方式赋予不同的权重。例如,如果对文本搜索非常有信心,可以将其权重设置为 0.9,而其他方式设置为 0.1。在完成搜索后,还可以进一步过滤结果,最终返回一个综合评分。然而,当对数据集不够了解时,Elasticsearch 提供了一种更为简单粗暴的方式 —— RRF(Reciprocal Rank Fusion)。
 <!---->
<!---->RRF 实际上是一种多路召回机制。我们可以同时进行传统的词汇搜索、稀疏向量搜索或密集向量召回。在召回结果后,重新排序。这种排序方式非常简单,它是基于名次而非实际分数。例如,某个文档在 BM25 搜索中排名第一,但在另一个搜索中排名第三,那么通过 RRF 公式计算后,最终会得到一个综合分数,这个分数将决定结果的最终排序。这种方法不仅适用于两路召回,还可以扩展到多路召回,包括稀疏向量、密集向量和词汇搜索,这在实际应用中非常有效。
在实际应用中,我们还可以设置 kNN 相似度阈值。例如,如果相似度低于 36%,则认为结果不够相关,可以选择不返回这些结果。因为相似度范围从 0% 到 100%,低于某个阈值的结果可能没有实际意义。这种机制在许多应用场景中非常有用。比如在构建知识库时,如果每次调用大语言模型都需要付费,那么可以将常见问题的答案存储在私有数据库中。例如,当有人询问 “中国的首都在哪里?” 时,可以直接从 Elasticsearch 中检索出之前存储的答案,而无需再次调用大语言模型,这样既节省了成本,又提高了效率。
Elasticsearch 不仅支持数据库存储,还可以通过机器学习节点创建嵌入,并进行混合搜索。它不仅可以进行搜索,还可以进行模型过滤、统计分析等操作。例如,可以统计文章中涉及军事、政治或文化的内容数量。此外,Elasticsearch 还引入了 ESQL,这是一种类似于 SQL 的语言,简化了传统 DSL 的复杂性,同时速度更快。在向量搜索方面,Elasticsearch 不仅支持传统的 HNSW 算法,还引入了 GPU 加速的 CUDA ANN Graph 搜索。
 <!---->
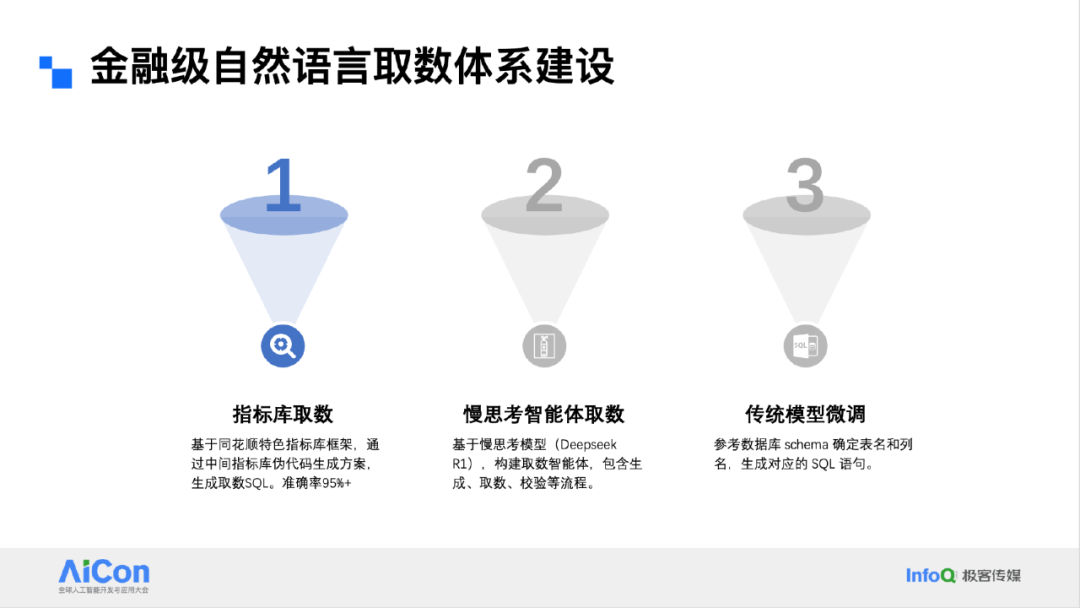
<!---->尽管许多人认为 Java 语言无法实现硬件加速,但 Elasticsearch 利用 Java 的 SIMD 功能,实现了硬件加速,并支持 CUDA GPU。向量搜索通常需要大量内存,尤其是在处理大规模数据时。为了优化内存使用,Elasticsearch 采用了量化技术,如将浮点数压缩为 8 位整数,从而将内存占用减少到原来的 25%。虽然这可能会牺牲一点精度,但大大提高了部署能力和效率。此外,Elasticsearch 还引入了 INT4 和 1 位量化技术,进一步节省内存。其中,BBQ(Better Bit Quantization)技术是南洋理工大学的一篇论文提出的,Elasticsearch 是全球唯一实现该技术的平台。通过这种量化技术,搜索速度可以提高 20 到 30 倍,查询速度可以提高 5 到 6 倍。
 <!---->
<!---->在查询并发方面,Elasticsearch 通过多线程优化,每个 segment 使用一个线程进行查询,从而显著提高了查询速度。此外,Elasticsearch 还引入了逻辑分区和并发协调机制,进一步优化了查询性能。在 IO 访问方面,一个查询中可能包含多个 IO 操作,这也有助于提高查询效率。未来,Elasticsearch 将继续改进,例如在处理大型 segment 时,可能会引入逻辑分区,以提高查询速度并优化多核心 CPU 的使用。此外,Elasticsearch 还将引入稀疏索引和快速模式等优化机制,以进一步提高查询效率。例如,在向量搜索中,如果距离已经足够接近,或者已经迭代了足够多的节点,可以提前终止搜索,以节省时间和资源。
Elasticsearch 的发展经历了从传统的词汇搜索到向量搜索,再到混合搜索的演变。混合搜索在许多场景中非常重要,因为它结合了多种搜索方式的优势。虽然许多人认为 RAG 可以解决所有问题,但实际上混合搜索和相关性调整(relevance tuning)同样重要。
在搜索的过程中,我们可能会通过 BM25 或稀疏向量搜索得到大量初始结果,但通过学习排序(learning to rank)和查询重排序(query rescoring)技术,可以将结果的相关性更加提高。Elasticsearch 提供了一种独特的学习排序功能,用户可以通过人工标注数据生成模型,并将其上传到机器学习模型中。在搜索时,该模型可以根据用户的需求对结果进行重新排序,从而提高相关性。这种方法特别适用于医疗、法律等特定行业,因为这些行业的知识背景需要专门的训练。
 <!---->
<!---->此外,Elasticsearch 还支持多级重排序(re-ranking),可以通过第三方服务(如 Hugging Face)进行更精确的排序。Elasticsearch 的 Sparse Vector 功能无需训练即可实现高效的全文搜索,甚至在某些情况下优于密集向量模型。Elasticsearch 还提供了一个检索器,可以结合多种搜索方式,并通过学习排序功能进行优化。
 <!---->
<!---->为了更好地处理长文本,Elasticsearch 引入了分块策略,将文本分割成小块以提高语义精度。分块策略可以根据句子或文字数量进行重叠,以确保语义的完整性。Elasticsearch 还提供了一个语义文本(semantic text)功能,简化了用户的使用体验。用户只需设置一个 inference endpoint,即可进行语义搜索,而无需进行复杂的配置。
在未来版本(如 8.18)中,Elasticsearch 将进一步简化搜索语法,用户可以直接使用 match 查询进行语义搜索,而无需进行额外的设置。这使得 Elasticsearch 的向量搜索功能更加易于使用,同时保持了强大的功能。
Elasticsearch 还集成了多家第三方服务,包括阿里云、Coherent 等,用户可以直接调用这些服务的 inference API。通过简单的设置,用户可以轻松集成这些强大的第三方功能,从而进一步提升 Elasticsearch 的搜索能力。
Elasticsearch 云服务正在探索一种全新的 Serverless 架构,这种架构与传统的分层架构截然不同。在这种架构下,数据的写入和存储方式发生了根本性的变化。当数据被写入时,系统不再依赖传统的副本(replica)或主分片(primary shard)。数据经过索引处理后,直接存储到对象存储(Object Store)中。在搜索时,系统也会直接从对象存储中检索数据。这种存算分离架构旨在利用最新的云原生服务,并通过无忧管理提供优化的产品体验。 它提供数据湖的存储容量,但具有 Elasticsearch 相同的快速搜索性能,以及无需干预的集群管理和扩展的操作简单性。
这种架构的一个显著优势是成本的大幅降低。由于对象存储的成本远低于传统存储方案,数据可以被长期保留,甚至存储一两年也不会带来过高的成本。通过这种方式,Elasticsearch 云服务能够以更低的价格提供服务,同时保持高性能。
 <!---->
<!---->在传统架构中,Elasticsearch 依赖于硬盘存储,而这种新的 Serverless 架构则完全摒弃了对硬盘的依赖。虽然本地可能仍会保留少量硬盘用于缓存或其他用途,但主要的数据存储和检索都依赖于对象存储。这种架构不仅降低了成本,还提高了系统的可扩展性和灵活性。
目前,Elasticsearch 云服务已经在亚马逊云上采用了这种架构,并且预计其他云服务提供商也将陆续推出类似的解决方案。这种架构的另一个重要特点是,它不再需要传统的主分片、副本分片等概念,因为数据的持久化和检索都通过对象存储来实现,从而避免了数据丢失的风险。
使用 Elasticsearch
在企业搜索中的案例
搜索并非简单的关键词匹配,而是一项需要深入了解上下文、案例以及所使用工具的技术活。只有对这些方面有充分的了解,才能实现真正高效的搜索。然而,人工智能在这方面仍面临诸多挑战。例如,当它缺乏相关知识时,可能会给出不准确甚至错误的答案。为了解决这一问题,我们需要采用 RAG 方法,这是一种让 LLM 变得更聪明的有效途径。
传统的预训练方法耗时漫长,成本高昂,可能需要数千万甚至数亿美元,并且需要专业知识。而针对特定领域的微调(fine-tuning)则需要机器学习专家和领域专家的共同努力。例如,如果知识库中没有珠穆朗玛峰是世界最高峰这一知识,模型可能会给出错误答案。即使将相关知识输入到像 OpenAI 这样的平台中,如果数据集不够大,模型可能在第一次搜索时给出正确答案,但在第二次搜索时又回到错误答案。这是因为数据集不足以改变模型的原有行为,这无疑是一个巨大的挑战。而通过 RAG 方法,我们可以有效消除这种幻觉。
在 Elasticsearch 的架构中,我们采用了多路召回机制。这包括传统的语义搜索(semantic search)和词汇搜索(lexical search),以及稀疏向量(sparse vector)和密集向量(dense vector)搜索。我们可以对多个字段或同一字段进行多路召回,然后结合排名(rank),甚至可以利用第三方服务进行重排序(rerank)。例如,通过上下文提示,我们可以从第三方服务中获得更准确的答案。
 <!---->
<!---->在 DeepSeek 的案例中,我们发现模型可能不了解 2024 年 7 月之后的知识,因此通过 RAG 方法进行搜索也不一定能得到准确答案。这时,Hybrid Search(混合搜索)就显得尤为重要。它结合了传统的词汇搜索和向量搜索,能够提高召回率,从而获得更精确的结果。
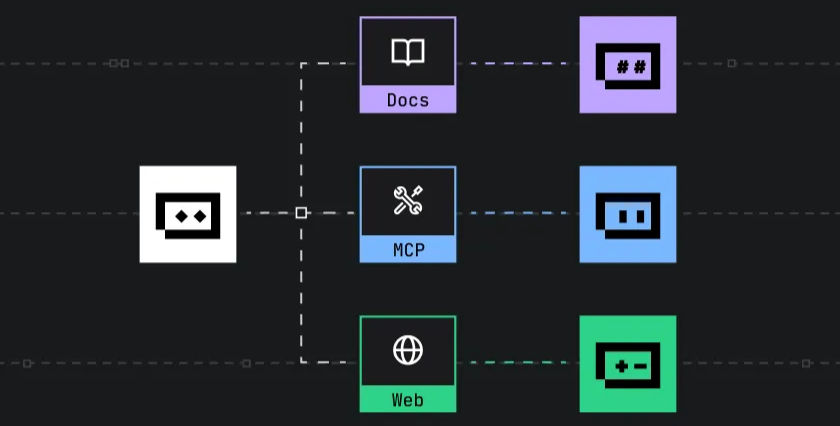
另一种方法是通过 Agentic RAG 使用不同的工具进行调用。例如,如果我们想获取 2025 年的 Elasticsearch 财务报告,语义搜索可能会将 2023 年的报告误认为是相关结果。这时,我们可以通过 LLM 提取日期等关键信息,生成一个 Elasticsearch 查询,添加时间过滤器,从而准确地找到 2025 年的财务报告。这是 Elasticsearch 的一个显著优势,因为它已经经过多年的训练,能够直接生成查询语句,甚至完成所有操作。
 <!---->
<!---->我们还采用了用于路由自适应的 RAG 方法。例如,当 DeepSeek 询问 Elasticsearch 的版本时,它可能回答的是 8.13,而实际上我们已是 8.18。在这种情况下,我们可以通过知识库查询,甚至利用 LLM 判断答案是否完全符合需求。如果不符,我们可以通过互联网搜索,再通过 RAG 提供答案。
 <!---->
<!---->HyDE(Hybrid Document Expansion)是一种通过生成更长的文本以提高召回率的方法。例如,当提出 “告诉我关于鱼” 的问题时,它可以生成一段更长的文字,从而提高搜索的召回率。在处理财务报告时,我们将文档输入,进行分片和分块处理,同时提取关键短语(key phrases)和实体(entities)。通过工具如 TextRank 提取关键短语,通过其他工具提取实体。我们还可以结合大模型生成与文档相关的潜在可以用来对文档进行提问的问题,并将这些问题、关键短语和实体进行向量化处理,然后将加权后的向量存储到 Elasticsearch 的向量库中。
 <!---->
<!---->在搜索时,我们让模型生成与问题相关的同义词。例如,当提出 “2025 年的财务报告” 这样的问题时,模型会生成一个与问题相近的长文本。然后,我们通过混合搜索方法,结合同义词、关键短语和实体进行搜索。这种方法能够获得比单独使用 BM25 或密集向量搜索更准确的结果。
 <!---->
<!---->整个方案的实现依赖于多种工具。例如,通过 SpaCy 提取实体,生成潜在问题,并通过 TextRank 提取关键短语。然后对这些内容进行向量化处理,并赋予不同的权重。例如,将最重要的密集向量( dense vector )权重设置为 0.1,其他设置为 0.05,最后将这些向量写入 Elasticsearch。在进行向量搜索时,结合词汇搜索,能够获得更精准的结果。通过这种方法,我们能够显著提高搜索的准确性和效率。
演讲嘉宾介绍
刘晓国,Elastic 中国社区首席布道师。新加坡国立大学硕士,西北工业大学本硕。曾就职于新加坡科技,康柏电脑,通用汽车,爱立信,诺基亚,Linaro 非营利组织 (Linux for ARM),Ubuntu,Vantiq 等企业。从事过嵌入式软件开发,电脑设计,手机软件设计,汽车电子,计算机操作系统,通信,云实时事件处理等行业。
















