
RAG不是一个技术名词,而是一种产品思维的重构方式。从“Retriever-增强”到“生成-调度”,RAG的每一环都关乎产品的边界、能力与体验。本文将从产品经理视角,拆解RAG的核心机制、应用场景与设计要点,帮助你在AI产品构建中真正“用得上、做得对”。

在上一篇文章中,我们讲解了 RAG 的基础原理、传统 LLM 的幻觉困境、使用RAG的好处、RAG 技术的工作流程、产品经理在使用RAG 的过程中可能遇到的问题(数据来源、结果不符合预期)以及应对措施(从召回到排序的逆向排查、各层次上的优化思路)。但是从基础的概念到实际的落地,还存在一大段鸿沟。
本篇文章,我们会从优化大模型应用效果的角度切入,分析基座模型、模型微调、RAG 技术、用户体验四个方面,其中 RAG 是投入产出比最高的杠杆。各个环节对模型应用效果的权重、具体如何优化 RAG 环节,值得我们深入探讨。

一、什么在影响大模型应用的效果?
在设计一个真正实用的大模型应用时,影响最终效果的关键因素可以从四个层面来分析,它们相互独立又紧密协作,共同决定了产品的落地能力和使用体验。其中,影响模型应用效果较大、AI 产品经理接触较多的因素是RAG(本文会着重讲解 RAG 如何影响模型的生成效果,关于四层分析框架可以阅读《万字长文:AI产品四层架构》)。
基础设施层:基座模型是整个系统的基础(约 40%)
我们常说要了解大模型的能力边界,到底是什么意思?我分上限和局限性两个角度来说:
① 上限由底层模型的基础能力决定:模型的理解能力、推理能力、生成质量等,从根本上决定了应用能处理多复杂的问题,以及生成内容的质量。就像玩版本弱势的英雄,你操作优化得再好也白搭,carry 不动。
② 局限性取决于大模型的原理和训练过程:架构、算法、数据等。如果大模型本身存在结构性缺陷,那么在后续优化中是很难弥补的。就像辅助英雄可能都没有攻击型的技能,用来打野就发挥不出它的能力。
所以选择合适的大模型并确保其性能稳定,是所有工作的起点,这在一开始就决定了。

模型层:模型微调(SFT)是对特定场景的优化(约 10%)
大模型虽然强大,但它本质上是通用的,无法针对具体场景提供最优解(比如金融问答、医疗对话等)。通过微调,我们可以让模型针对特定领域或业务场景进行优化,使其生成的内容更贴合应用场景。比如,针对医疗领域的应用,我们可以用专业医学数据对模型进行微调,直接影响到模型在具体场景中的表现,让它更懂医学术语和诊断逻辑。
模型微调通常可以采用两种不同的策略:
1. 全参数微调(Full Parameter Fine Tuning)
2. 部分参数微调(Sparse Fine Tuning)
一种是对模型的全部参数进行重新训练,另一种则是仅针对部分参数进行优化。这两种方法各有适用场景和技术特点,选择时需要结合具体业务需求和资源条件:
第一种策略,即全参数微调,适用于对任务要求极高且模型需要彻底适配新场景的情况。通过重新训练模型的所有参数,可以让模型从底层到高层都贴合目标任务。这种方法虽然灵活性最高,但对计算资源的要求较高,同时也需要较大的标注数据集来支撑训练,否则容易出现过拟合或训练效果不佳的问题。
第二种策略是部分参数微调,通常 冻结部分模型层,仅调整特定层的参数,或者采用类似“Adapter”模块的方法,在原模型上增加小规模的可训练子模块。这种方式显著降低了计算成本,同时能够保留原模型的知识,避免对已有能力的过度扰动。它特别适合数据量有限或计算资源受限的场景,也能快速适配新任务。
合理设计微调可以提升模型效果,但是由于模型微调存在成本高、周期长、需要大量高质量数据的特点。所以,在实际的项目中,微调不是常规首选,而是高投入、高门槛的进阶方法。

应用层: RAG(检索增强生成)(约 40%)
这部分可以理解为效率提升的关键工具。大模型虽然能生成内容,但它并不总是能即时获取最新或最准确的信息。而通过检索增强生成技术,我们可以让模型在生成内容时动态调用外部知识库和与 query 相关的历史对话。在实际应用中,利用 RAG 是最具性价比的一种策略。与其花大力气“教会模型理解所有内容”,不如让它“边查边答”。

一句话总结:RAG =大模型+查资料能力。
有没有使用 RAG 的区别,就像是大学期末考试,闭卷考试和开卷考试的区别:
(1)没用 RAG的模型回答问题,只能回忆的学过的知识。传统的大语言模型在生成内容时,只能依赖其训练数据和内部参数(学过的知识)进行推理和生成。会生成一些看似合理但实际上并不准确甚至不存在的信息,出现所谓的“幻觉”。
(2)有了 RAG的模型回答问题,先查重点再写答案。这个查资料的能力,就是 RAG(Retrieval Augmented Generation),核心是检索与生成,先通过检索模块从资料库中找到与问题相关的内容,再将这些内容与用户的问题一起传递给语言模型,即“用户提示词+查到的内容”。
更准确的来说,LLM 具体的输入由几个部分组成:

RAG 后的模型,它接收的输入就是这样一个经过精心构造的文本序列,检索多种信息源保证知识的专业性和全面性,检索query 相关的历史对话保证回答的准确性,最终增强大模型生成回答的准确性(即”检索增强生成”)。
这样就解决 LLM 本身的 2 两大局限:
(1)知识是静态的:在完成训练后,大模型的知识会被“保存”在其参数中,无法自主更新新闻、文档或业务相关的信息。RAG通过外部知识库动态检索相关信息,把这些信息拼接进当前输入,保证提供给模型的背景信息的深度和广度。
(2)上下文窗口限制:大语言模型一次只能“看”一定长度的文字,就像人的视线只能看到一定距离内的物体。这个能看多少字的长度叫做上下文窗口,比如,模型的上下文窗口是4000个字(tokens),它一次最多只能处理4000个字的内容,如果你给它的输入超过4000个字,它只能看最靠近最后的4000个字,前面的就看不到了。
注释:不同模型对相同文本的分词规则不同,在大型语言模型中,汉字与token的换算比例通常为1个汉字≈1-2 tokens(具体差异取决于不同模型的分词规则和字符类型)。
举个例子,假设你和模型聊了很久,历史对话有1万个字。但模型一次只能看到最近4000个字的对话内容,之前的6000个字它“看不到”,就像被遮住了。所以,模型回答时只能基于最近4000个字里的信息。你当场提问,RAG 当场就去历史对话和外部知识库里检索相关资料,从里面“挑出最重要的部分”,拼成一段不超过4000字的内容,模型虽然还是只能看到4000字,但这4000字是“精选”的,包含了对回答最有用的信息。
模型本身的上下文窗口大小没有变,但是RAG帮你从历史和知识库里选取重要内容,拼成模型能处理的长度,让模型“看到”更有价值的信息,所以回答质量大大提高了。

用户体验层(10%)
最后才是用户直接接触的部分,产品的门面——包括界面设计、交互逻辑、功能设计以及用户体验优化。
并不是否认用户体验的重要性,再强大的模型,如果用户在实际使用中觉得操作繁琐或功能不够贴心,都会影响产品的最终价值。但是在如今在移动互联网时代,我们已经积累了相当成熟的 UI/UX 技术,用户体验层已不是瓶颈。
四个层面环环相扣:大模型提供底层能力,微调让能力适配场景,RAG 保证信息专业性和全面性,而应用层则将技术转化为用户价值。
二、如何发挥RAG技术的最大效果?
在充分理解 RAG 的重要性之后,接下来我们将探讨如何最大化其潜力:有效的 RAG 实施不仅依赖于合理设计的提示词,还需要一些优化技巧(考虑数据质量、格式选择、tokenn 限制等因素),才能确保系统能够准确、有效地生成所需信息。
三个 RAG 提示词模板——精准地引导 RAG 进行信息检索与生成
提示词 1:需求识别/query改写+精准回答
问题的表述方式对回答质量有直接影响。如果用户提出的问题过于宽泛或模棱两可,RAG可能会因为缺乏明确的方向而给出不准确甚至错误的回答。优化问题表述不仅能够减少歧义,还能让 RAG更专注于检索到的信息,避免它凭空“脑补”或编造内容,从而提升回答的精准度。
用户想了解 [ X ],但他在表达问题时,可能存在模糊或隐含的意图, 需要你先通过精准的语义分析来识别其真实需求,再结合以下知识库的内容,给出最清晰、最准确的回答。
应用场景:
(1) 问题过于模糊:当用户的问题缺乏明确指向时,RAG可能会因为信息检索范围过大而失去焦点。 例如,“如何提高效率?”这样的提问很难得到有价值的回答。结合上下文将 query 改写为“在知识管理系统中, 如何利用 RAG 技术提高信息查询效率?”,问题的范围和上下文就清晰了,回答也会更有针对性。
(2) 开放式提问:开放式问题通常可以回答的维度过多,容易让模型生成泛泛而谈的空话、套话。例如,“RAG 的优势是什么?”结合上下文将 query 改写为“在处理非结构化数据时,RAG 相较于传统检索系统有哪些具体优势?” 引导 RAG专注于特定领域,给到言之有物的具体回答。

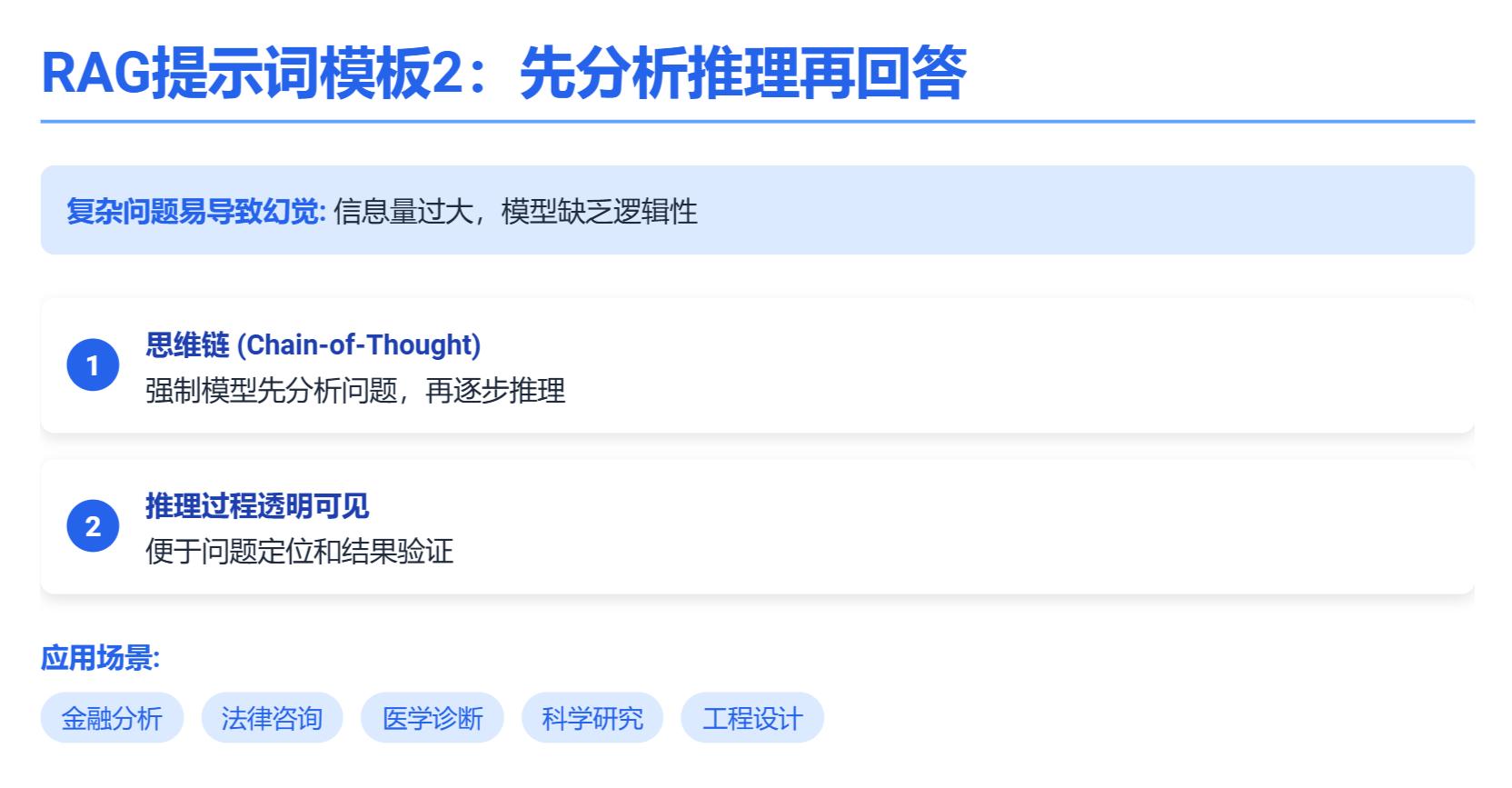
提示词 2:先分析推理再回答(COT)
在处理复杂问题时,信息量过大往往会导致模型缺乏逻辑性,给出混乱甚至错误的答案,可以强制 RAG 先分析问题,再逐步生成答案,进而减少模型出现幻觉的概率。思维链 (Chain-of-Thought) 就是让模型先按照明确的步骤进行推理,而不是直接跳到最终答案。
这是用户的问题 [ X ]。用更简单的语言总结用户问题;挑选出最相关的文本片段。把这些片段整理成逻辑清晰的大纲,基于大纲撰写一个完整、连贯的答案。请展示你的推理过程,并提供最终精炼后的答案。
应用场景:
常用于对准确性要求较高的任务,例如金融分析、法律咨询、医学诊断等复杂场景,错误或不严谨的答案可能带来严重后果。 需要模型有更强的逻辑能力(先列大纲保证结构清晰),为用户提供更加真实和精确的答案。同时,推理过程透明可见,如果答案有错,也能轻松定位问题。
提示词 3:让模型学会“say no”
这是用户的问题 [ X ]。如果你没有检索到相关的信息,请直接回答“我没有相关信息”,如果你有足够的信息来回答,就基于信息正常回答。
应用场景:
(1) 在智能客服场景中,用户提出的问题可能超出知识库范围。此时,让机器人它直接礼貌地说明“当前信息不足,无法准确回答”,并引导转人工,可以避免对用户的误导。
(2) 在研究分的场景中,例如市场分析或科学研究,需要严谨的数据支持,该提示词优势则更为明显,它只会基于检索到的可靠信息生成答案,不了解的予以回答。这种机制能够确保输出结果的可信度,避免因错误信息导致决策偏差。

四个 RAG 的优化技巧——更好地发挥出 RAG 优势的策略细节
1) 清理和整理 RAG数据源:可以设定规则确保检索出的信息足够精准,并过滤掉无关内容,提高系统整体的准确性。比如,在一个电商产品知识库中,定期删除已下架产品的信息,避免 RAG 在回答关于产品的问题时引用到无效内容。
2) 限定回答的输出格式 :不同的内容类型,适合不同的输出格式。在某些情况下,调整提示词结构能显著提升 RAG 的回答质量,如:
要点式总结 :适用于技术性内容,能让信息更清晰易读。比如总结代码技术文档时,用要点式列出关键代码功能、使用方法等。
请以要点的格式总结检索到的代码文档:
– 代码功能
– 使用方法
– 注意事项
问答结构(Q&A):适用于 FAQ 或知识库查询,便于模型精准匹配答案。像常见问题解答系统,直接采用一问一答的格式让 RAG 更高效地给出回应。
请根据以下常见问题提供答案:
– 如何安装软件?
– 软件的系统要求是什么?
– 如何联系技术支持?
– …
表格格式:适用于信息比对,比如产品参数、数据分析等场景。在对比不同品牌产品参数时,用表格呈现数据,RAG 能更直观地进行分析和回答。
请比较以下三款手机的参数,并以表格形式呈现:
– 品牌A:型号X
– 品牌B:型号Y
– 品牌C:型号Z
3)对信息进行精简,以减少 tokne 占用:通过摘要或预处理方法来精炼信息,确保 RAG 接收到的仅是最重要的数据。例如,在处理一篇冗长的新闻报道时,首先对其进行摘要,并提取出关键内容,然后再交给 RAG 模型,这样既能够保证信息的全面性,也不会超出 Token 的限制。
4)加入审核机制,确保答案可靠:在处理高风险场景时,比如法律、医疗、金融领域,仅依赖 RAG(检索增强生成)技术自动生成的答案并不够可靠。为了提升输出的准确性和可信度,需要引入额外的审核机制。
这里可以采用两种方法:
- 辅助模型审核:引入第二个模型对初步生成的内容进行质量检查。这类模型可以专注于语言质量、逻辑一致性或领域专业性,例如用一个专门设计的语言质量评估模型来审查RAG生成的法律文件解读是否符合专业标准,是否表达清晰且无歧义。如果发现问题,可以针对具体问题优化生成逻辑或调整输入数据。这种方式能够在生成阶段就发现潜在问题,大大减少下一步人工二次审核的工作量。
- 人工二次审核:对于一些关键领域,比如医疗诊断或金融决策,单靠AI生成的初步结果是不够的,必须增加人工审核环节。具体来说,RAG生成的内容可以作为辅助参考,但还是要由领域专家进行全面复核。例如,在医学场景中,AI生成的诊断建议需由专业医生逐条审核,确保每一项建议都符合临床实际,避免误诊或漏诊。这种方式虽然增加了流程复杂性,但对于最终结果的可靠性至关重要,尤其是关乎生命安全或重大经济决策时。
两种方法各有侧重,可以根据场景需求组合使用。辅助模型审核适合大规模内容审查,效率较高;人工复核则适用于关键环节,确保最终输出万无一失。
本文由 @黄晓泽 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
















ByteStorm
“AI来做产品经理,这世界,我有点懵,但好像挺有意思的。”
VoidEcho
“RAG,这名字太炫酷了,感觉它一定能带来一场产品革命!”
Neo_Vibes
“AI产品经理?感觉有点可怕,但又想知道它到底能做出什么东西!”
Neo_Vibes
“RAG!这名字就预示着它会像一个复杂的算法,有点头大!”
Neo_Vibes
“听听看,AI当产品经理,这逻辑我有点晕,但确实挺有意思的!”
ByteStorm
“RAG,这玩意儿简直是给AI喂食的纸板,真搞真搞!”
Neo_Vibes
“我有点担心,如果AI当产品经理,人类的创造力会不会被它扼杀?”
LunarPhase
“掌握RAG,就像学会了用魔法预知未来,这绝对是未来趋势!”
LunarPhase
“RAG?听起来就像一个在厨房里指挥厨的AI!太有意思!”