
在AI模型快速迭代的时代,评测体系不再只是“验证效果”的终点,而是驱动模型优化的起点。本文以“从零到一”的视角,拆解如何构建一套可复用、可扩展的自动化评测体系。

在大模型的训练中,模型评测始终是不可或缺的一个环节,模型的优势劣势、迭代方向、迭代成果、与国内外竞品的差距、是否存在硬伤?如果没有评测,以上所说的这些都无法判断。因此近2年来「模型评测」相关岗位,需求出现了井喷,各大公司都紧锣密鼓地搭建模型评测团队。
然而与此同时,各大公司又在布局另一件事:自动化评测,即用大模型评测大模型
判断模型是否可靠,难道不应该用人类吗?既然如此,为什么要用模型来评测模型?原因很简单:
当前人类团队的评测产能,开始跟不上评测需求了
这个跟不上需求,主要体现在两个维度:
一是评测进入专项深水区,人类有点跟不上节奏了,比如代码生成等评测任务。对于这些数据,人类评测往往需要投入大量时间成本,而且在不少情况下,评测人员本身也难以准确判断结果的对错;
二是随着模型迭代速度不断加快,评测需求呈指数级增长,现有团队已难以承载;而如果单纯依靠扩充人力来解决,不仅效率低,还会带来显著的成本压力。
作为在职的 SFT&模型评测项目经理,本文就从一个 AI 训练从业者的视角,分享从0到1搭建起自动化评测流程的核心思路。
第一步:改造原有评测流程
搭建自动化评测流程之前,不妨先从常规评测流程入手,思考常规流程可以如何用大模型进行改造。
常规的模型评测流程是这样的:
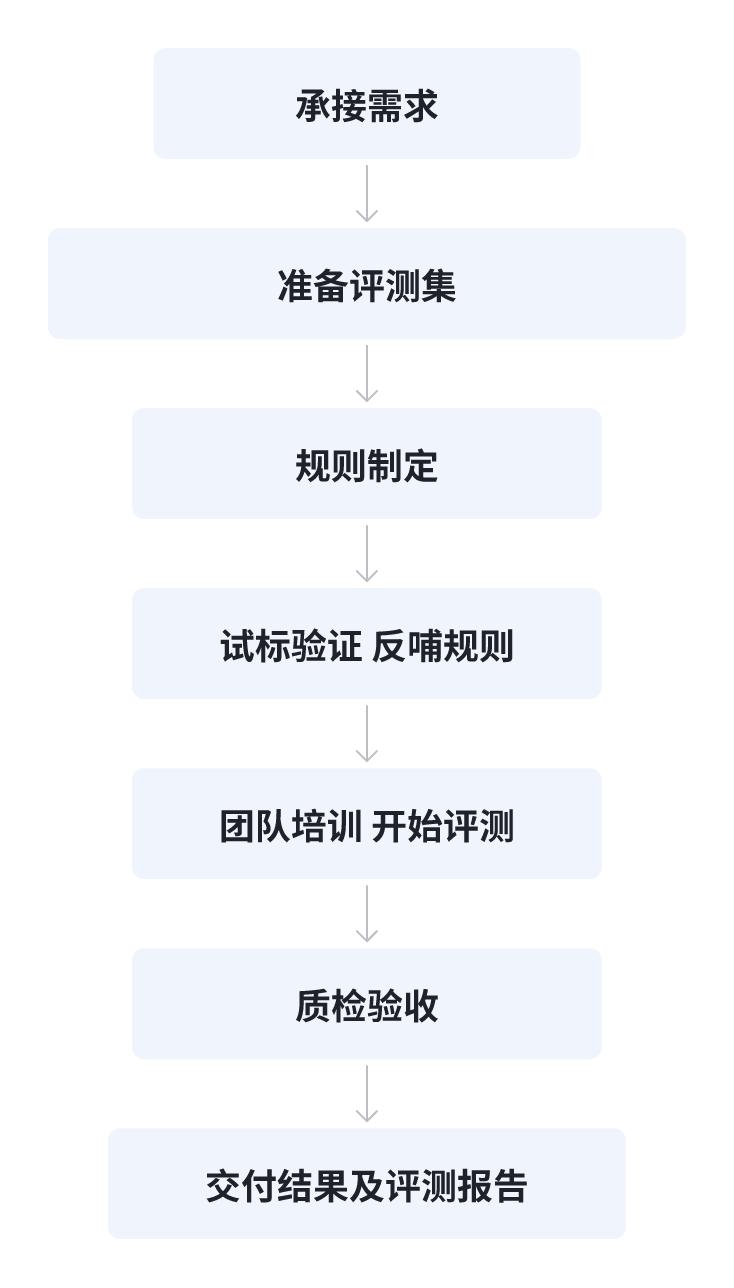
常规评测流程本身已经相当科学,但正如前文所述,它在效率与成本上存在明显瓶颈。那么,如何利用大模型对其进行改造?一个直观的思路是,将评测团队中部分重复性强、规则性明确的工作逐步交给模型完成。
例如在规则撰写环节,过去需要人工整理背景与要求,而现在我们只需向 AI 口述项目背景、评测需求和重点关注的维度,就能快速生成一份初版的评测规则文档。在此基础上,人类再进行修订和优化,就能够节省大量时间与精力。
需要注意的是,若目标是自动化评测,那么面向 AI 的规则文档与面向人工评测员的文档会有所差异,这一点我们会在后文展开。
敲定规则文档后,我们需要让 AI 进行试标,看看输出的内容、结构等,是否符合我们评测的需求?这也是让 AI 接管评测的重要一步,而这一步的关键在于:prompt 的构建。我们需要根据规则来撰写一段清晰、明确的prompt,让 AI 能够理解,它应该如何对每条数据进行评测,并且给出评测结果。完成 prompt 之后,就可以进行小批量的试标了。
AI 试标的过程,本质上是对规则及 prompt 合理性的检验,AI 试标输出的结果符合需求后,我们就可以批量把评测数据交给 AI 进行评测,等待 AI 给出的评测结果。
由于目前 AI 依然存在幻觉问题,因此 AI 给出的评测结果,并不能够百分百置信,更不能够直接用于输出评测报告,它们的凭借结果还需要经过人类团队的验证,因此下一个环节就是:人类验收 AI 评测结果。
如果评测集仅有100~200条数据,直接100%验收即可;但如果评测集的量级较大,如超过500甚至1000条,我们可以采取先抽验30%,看看评测结果是否置信,如果准确率达到95%以上,基本可以判定本次 AI 评测的结果是置信的,也就可以输出评测报告了。
写到这里,一个通用的自动化评测流程,也就初步搭建好了:
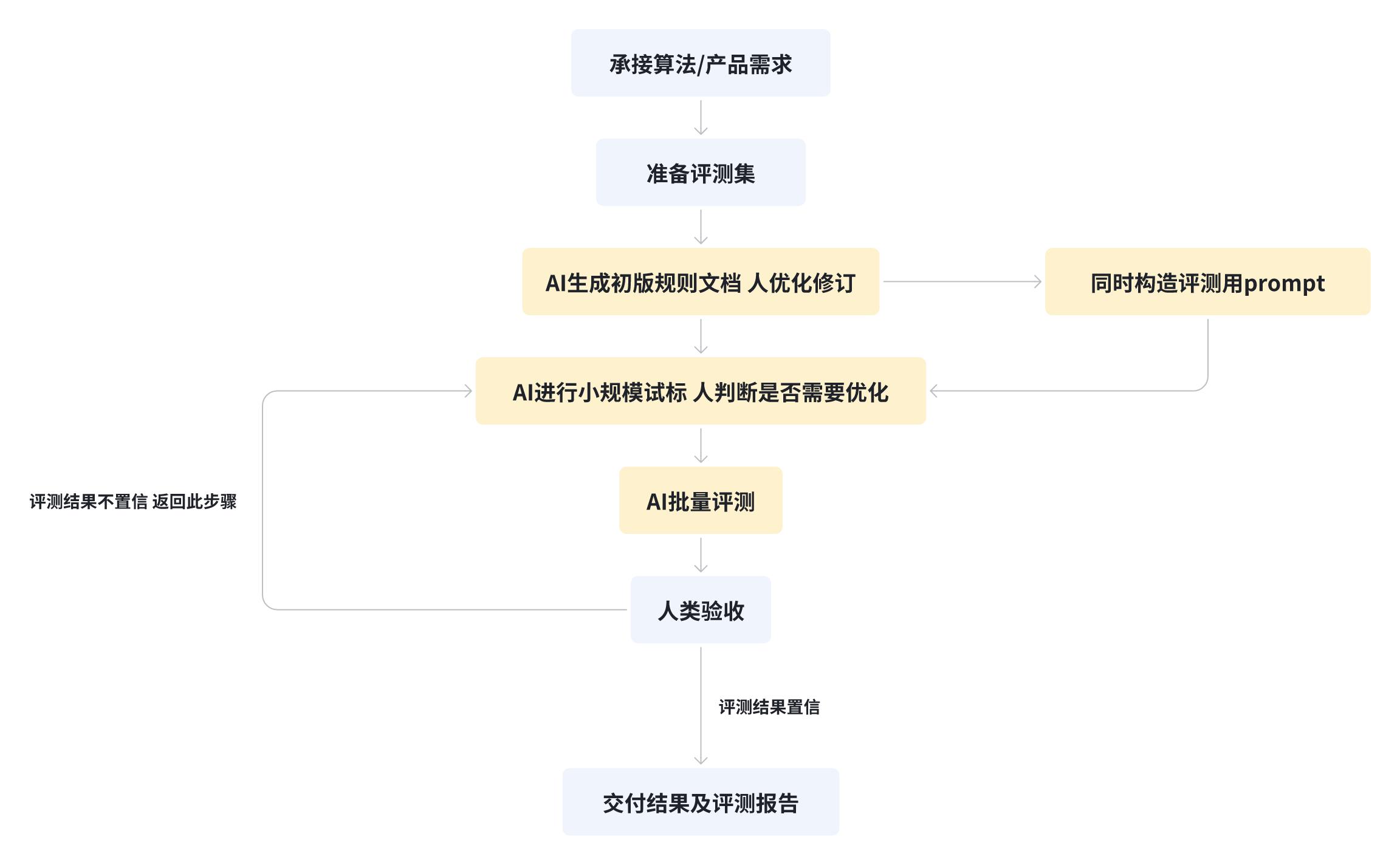
可以看到,自动化评测并不是要取代人类,而是让人类团队从大量重复性、低价值的工作中解放出来。通过这套流程,评测人员不再需要全量参与,而是以抽检和纠错为主,从“执行者”转变为“监督者”。
这样一来,团队不仅能保持评测质量,还能在同样的时间里承接更多需求,整体产能大幅提升。
既然 AI 在评测流程中扮演了越来越重要的角色,那么接下来的关键问题就是:如何写好 Prompt。
第二步:针对评测任务构建 Prompt
在评测流程完成初步改造后,AI 已能够接手规则的初版撰写、试标以及正式的评测标注,这意味着自动化评测的框架基本具备。
但真正决定这套体系能否跑得通的关键因素,或者说整个流程的关键节点,其实在于——评测 Prompt 的构建。
我把一个好的评测 Prompt,浓缩为了以下这个公式:
优质评测 Prompt = 明确的评测目标 + 清晰明确的规则文档 + 输出格式约束
一个个来展开。
1. 明确的评测目标
这个没有太多可说的,就是要让模型知道它到底在评测什么?是准确性、相关性、逻辑一致性,还是可读性?如果目标本身模糊,模型的输出就会偏离预期,评测结果也就无法采用。
2. 清晰明确的规则文档
可以这么说,写给模型参考的规则文档,质量要求要比给人类团队的更高。因为人类评测和模型自动化评测,即便最终交付的结果相同,但完成任务的路径差别极大。
在人类团队评测时,即便规则文档存在瑕疵或表述不够清晰,评测员仍可以通过沟通、提问或反馈来澄清困惑,从而修正偏差,最终使得交付的评测数据基本符合评测需求及规则。
而模型不同于人类评测员,首先,模型无法在模糊规则下做出灵活的判断,而是完全依赖 Prompt 提供的信息、指令来进行输出;其次,模型没有这种询问规则制定者的解决路径,它面对模糊规则时只能硬性给出结果,往往偏离真实意图。
因此如果规则在 Prompt 中的表达不够明确,对规则维度的定义不明确,那么自动化评测的结论就会失真,自动化评测不仅无法帮助我们降本增效,反而浪费了大量的时间和资源。
除了各个评测维度的规则以外,评测的方法分值也需要进一步优化。
在人类评测中,常用的是 0/0.5/1、0/1/2,或0–5等较粗粒度刻度。之所以可行,是因为整个流程严格依据评测规则与判定标准,配合质检与验收流程,对存疑数据也可以通过讨论达成评测结果的一致,总体而言,现有的人类评测流程和标准,是科学且置信的。
对模型而言,情况则有所不同。
由于大语言模型的本质是统计学,是概率,这就导致模型的生成结果必然存在抖动。
而模型在面对细微差异时,要么被迫落在同一档,失去区分度;要么因为轻微波动而跨档跳分,造成结果不稳定。长期来看,这会把原本可以忽略的小差异不断放大,与模型自身的输出抖动叠加在一起,使得评测结果在批次之间缺乏一致性,难以作为可靠的参考依据。
因此,在自动化评测中通常需要更细粒度或更长刻度的评分方法,避免出现上述情况,以提高评测的准确度。
3. 输出格式约束
自动化评测意味着规模化的输出结果,因此强制约束模型的输出格式,非常重要。
即便是同一段prompt,即便是同一个模型,可能每次都会输出不同结构的内容,这种结构上的不一致,一旦进入大规模评测,就会带来严重的问题:
首先,人工验收模型评测的结果会非常麻烦,比如有的response只给分数,不给原因,验收就相当于人工重新再评一次这条数据,团队不得不投入大量人力去判断评测结果,那自动化频次的意义何在?其次,不同批次的评测结果缺乏统一的输出口径,就很难进行横向对比,甚至今天输出的数据和下个月的数据没有可比性,版本迭代之间的差异无法量化,导致我们无法判断模型的真实改进幅度。
因此我们在prompt里面,必须要求模型以固定结构输出结果,这是规模化的前提,只有统一格式才能保证后续:人工核验、统计、比对、批量数据整合的可行性。
落到实操上,可以要求模型严格遵循固定的输出结构,比如统一要求以 JSON 格式返回评分和理由,或者以表格形式输出各维度的得分等。
这样做的好处是显而易见的:一方面,结果可以直接被系统化采集和分析,极大提升了规模化的可行性;另一方面,不同版本、不同批次的结果能够保持一致口径,真正形成可比性和可追溯性。
满足上述的三个条件,我们也就得到了一个优质的可用于自动化评测的 Prompt,接下来的重点是什么呢?
是模型。
第三步:评测模型的选用

相信我,如果你真的完整搭建一遍自动化评测流程,会发现选择合适的模型,可能是最麻烦的一步,因为你需要同时考虑三个问题:
性能问题
首先是性能问题,并不是所有的大模型都适合用来作为评测模型。这里的“性能”指的不是通用性能,而是评测方面的性能。
诚然,很多模型在生成任务中表现出色,比如对话流畅、内容丰富、信息密度较大,但当场景切换到自动化评测,反而未必合适,原因在于,评测要求模型更加克制和精准,它要按照固定的规则去判断正确与否、如何给分,而不是发挥创意,对评测数据进行发散的分析。
比如我们在内部的模型选型过程当中,测试了若干个主流大模型,其中有一个模型的表现,让人感到错愕:某thinking大模型,文本生成能力不错,代码能力也是第一梯队,我们本来对其寄予厚望,但很无奈,它在自动化评测场景的表现非常一般,甚至有些让人失望。
举个例子:当我们故意往一条评测数据中,人为加入一些明显的低级错误,并且进行反复评测,按照我们设定的机制和规则,出现这种低级错误,最终得分不可能高于30分…然而,该模型评测结果这样的:

也就意味着,该模型在5次评测中,有4次都没有发现人为添加的低级错误,甚至第3次分数的还更高了。
当然,这个模型还存在一些其他的问题,我们马上就会讲到,也就是:稳定性。
稳定性问题
还是某thinking模型,以另外一条数据为例:

在同一个模型、同一条输入的前提下,我们连续跑了 5 次评测,结果出现了明显的波动:第一次是 52 分,第二次掉到 49 分,第三次又升到 56 分,第四次骤降到 43 分,第五次再回到 53 分。
——整体的浮动范围达到 13 分。
这就会导致同一条数据没有得到相对一致的结论,对于自动化评测体系来说,这种波动是致命的,因为它不够稳定,导致我们无法判断到底哪一次的结论才是置信的,也就无法用它来长期进行评测。
如何解决性能问题和稳定性问题呢?只能不断地尝试,用各种难度的数据进行测试,最终形成几个团队公认的、评测结果较为置信的标杆模型。
选出了标杆模型之后,我们还需要解决第三个问题:成本。
成本问题
在实际的评测任务当中,并非所有的任务难度都很大,如意图识别类的评测相对简单,模型只需判断query的核心意图即可;而代码生成、翻译等任务的评测难度则明显更高,往往需要模型具备强大的理解与分析能力。
这就引出了一个问题:是不是所有的评测都需要用顶尖的大模型去自动化评测?
显然不需要,如果所有任务都一刀切地用顶尖模型去跑,成本会迅速膨胀,老板也不会太开心。因此在自动化评测当中,我们还需要根据任务难度,去匹配合适的模型。
例如低难度、高频次的任务,可以使用参数量较小的模型,以较低的单次调用成本换取覆盖面和效率,加上任务本身难度较小,人工复核的速度也较快,最终能够给出置信的评测结果。
而高难度、对结果准确性要求极高的任务,则必须引入顶尖大模型,成本高一些是可以接受的,但必须保证评测结论的可信度。
所以综合看下来,在实际搭建模型自动化评测流程的过程当中,要踩的坑还是不少的,模型的选择就是一个比较大的坑。
因此模型自动化评测流程的搭建,并不是一蹴而就的,它需要我们耐心地衡量每一步如何改造,才能在提升评测产能的同时,也兼顾评测结果的置信,最重要的是让评测团队的同学,从重复性劳动中解放出来,转而专注于规则优化、误差诊断等更高价值的环节。
完成上述的三个步骤,自动化评测的流程基本也就可以跑通了,当然,搭建这个流程急不得,在兼顾现有业务的情况下,个人预计一个团队要把这套流程搭建起来,一个月的时间还是需要的。
总结
简单总结一下。
在方法论层面,自动化评测的构建可以概括为三个核心步骤:
- 流程改造:使AI能够逐步接手规则撰写、试标与正式评测,形成可执行的自动化工作流;
- Prompt构建:将评测目标、规则体系与输出约束翻译整合进Prompt,保证评测输出的一致性与可统计性;
- 模型选型:在性能、稳定性与成本之间找到平衡。
如果缺少这三步的顶层设计,所有的努力最终都可能流于局部优化。
即便自动化评测搭建完成,人类团队的价值并不会因此消失,相反,评测同学可以从「执行者」转为「裁判员」,不仅一定程度上解放了重复性劳动,也能把精力集中在更高价值的环节上,比如评测规则的优化、评测维度的拓展、异常结果的诊断。
最终的结果就是:同样规模的团队,在自动化体系的加持下,可以承接数倍的评测需求,而质量并不因此下降,反而更加稳定且置信。
感谢各位看到这里,浮躁的时代能将长文读到最后实属不易。
觉得有帮助不妨点赞、收藏、加关注,我们下周再会。
本文由 @比沃特 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Pixabay,基于CC0协议















