

当我们谈论机器人灵巧操作时,数据稀缺始终是悬浮在头顶的达摩克利斯之剑。
在大模型、自动驾驶领域纷纷依靠海量数据 “涌现” 出强大能力的今天,机器人灵巧操作依然困在数据瓶颈。
近期,北京大学、哈尔滨工业大学联合 PsiBot 灵初智能提出首个自我增强的灵巧操作数据生成框架 ——DexFlyWheel。该框架仅需单条演示即可启动任务,自动生成多样化的灵巧操作数据,旨在缓解灵巧手领域长期存在的数据稀缺问题。目前已被 NeurIPS 2025 接受为 Spotlight(入选率约 3.2%)

- 论文题目:DexFlyWheel: A Scalable and Self-improving Data Generation Framework for Dexterous Manipulation
- 论文链接:https://arxiv.org/abs/2509.23829
- 项目主页:https://DexFlyWheel.github.io
研究背景:
为什么灵巧手数据生成如此困难?
在具身智能快速发展的今天,覆盖多样化场景和任务的机器人数据集不断出现。但是面向五指灵巧手的操作数据集仍然缺乏。这背后有几个关键原因:
1. 传统方法失效。 二指夹爪的生成方案在灵巧手上基本无法推广。启发式规划难以应对高维动作优化,LLM 虽然能提供语义引导,却难以生成精细的五指控制轨迹。
2. 高成本的人工示教。基于遥操作设备可以有效收集灵巧手数据,但是需大量人力、时间与资源。可扩展性低,难以形成多样化、规模化的数据集。
3. 纯强化学习效率低。完全依靠强化学习虽然可以训练出成功的策略并迭代成功轨迹,但往往出现手部动作不自然、机械臂抖动等问题,再加上探索效率低,难以高效产生高质量轨迹。
4. 仅限于抓取任务。目前已有一些灵巧手数据集被提出,但大多仅针对抓取任务进行特定设计,任务类型单一,难以迁移至其他精细操作场景,限制了灵巧手技能的泛化与发展。
5. 轨迹回放方法数据多样性有限。基于轨迹回放与编辑的方法是目前最常用的灵巧手数据生成方法,但它只能在预定义场景下做空间变换,无法探索新策略。导致了数据多样性低,难以支撑灵巧操作策略的泛化。
总体来看,无论是依赖人类示教、轨迹回放,还是单纯依靠强化学习,现有方法在成本、生成效率和数据多样性方面都存在明显局限,很难同时兼顾。
面对这一挑战,团队在实验中发现了一个有趣现象:
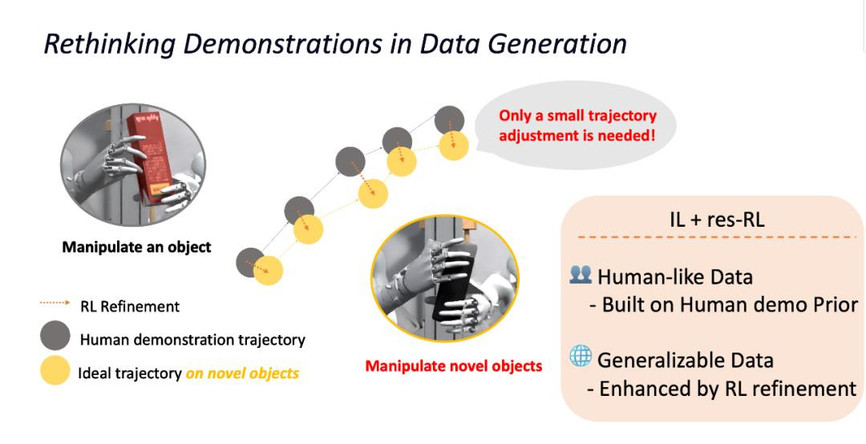
在灵巧手操作不同物体时,轨迹通常只需做细微调整。物体差别越小,调整越细微。
这启发团队提出一个新思路:成功的演示数据不应是数据生成的 “终点”,而可以成为更多场景下数据生成的 “起点”。 换句话说,一条高质量轨迹完全可以被利用,衍生出大量新的训练数据。
更高层次地,智能系统往往遵循 “能力 — 数据 — 能力” 的迭代提升规律,从而推动自我演进。
这让团队进一步思考:灵巧手数据生成是否也可以形成类似的自我提升循环,让系统持续扩展、生成多样化的数据?
这就是 DexFlyWheel 背后的初衷:不再依赖大规模数据投入,而是为灵巧手构建一个只需少量轨迹启动,即可持续进化和自我提升的高效数据生成系统。
DexFlyWheel 技术解析:
自我提升的灵巧手数据生成飞轮
团队提出了一种兼具成本、高效性与可扩展性的方案,叫做 DexFlyWheel。它有两个核心思路:
1. 利用模仿学习 + 残差强化学习,重新定义演示的作用
团队基于关键发现 —— 操作不同物体时轨迹往往只需细微调整,设计了 “模仿学习 + 残差强化学习” 方法来将演示迁移到新场景。一方面,模仿学习保证轨迹保持人类演示的自然性;另一方面,残差强化学习对轨迹进行精细微调,使其适应新环境。最终,通过组合策略,能够高效生成多样化且类人的轨迹数据。
2. 构建数据与模型的闭环飞轮
DexFlyWheel 构建了数据与模型的自我提升循环,让模型在循环中自我提升,实现数据和策略性能的协同增长。
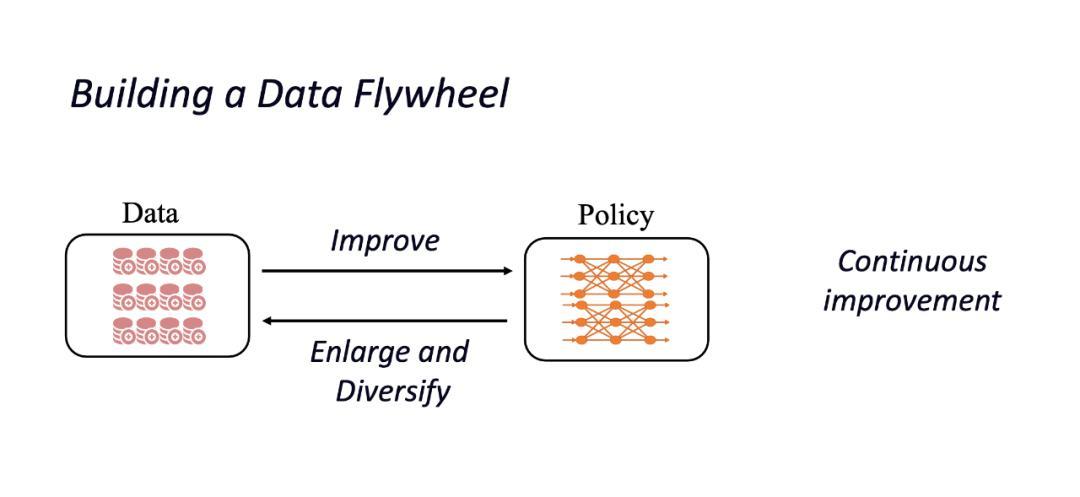
通过这两者的结合,DexFlyWheel 实现了高效且可扩展的数据生成,不仅显著提升了数据的多样性与规模,还将对原始演示的依赖降至每任务仅需 1 条,极大降低了成本。
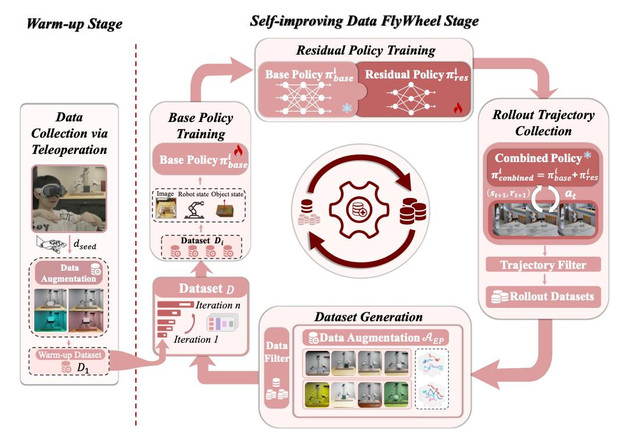
DexFlyWheel 框架如下图,分为两个阶段:
1. 预热阶段:通过 VR 采集 1 条种子演示,经数据增强得到初始数据集。
2. 自我提升的数据飞轮阶段:
- 基础策略训练:利用扩散策略从数据中学习人类先验,保持行为的类人性。
- 残差策略训练:用残差强化学习对策略进行微调,增强其泛化到新场景的能力。
- 轨迹生成:基于组合策略,在仿真中的多样化场景下不断生成新的成功轨迹。
- 数据增强:对轨迹进行多维度增强,产出更丰富的数据集,用于下一轮迭代。
DexFlyWheel 就这样把一条演示 “放大”,让数据和策略在循环中不断自我提升。随着迭代推进,数据多样性快速增长,形成 “越用越强、越转越快” 的飞轮效应。
实验结果:
DexFlyWheel 生成效率更高、数据更多样,策略更强泛化
实验任务
- 四个灵巧手任务:单手抓取、单手倾倒、双手提起、双手交接。
- 每个任务仅需一条演示启动 DexFlyWheel。

主要实验指标与结果
1. 数据多样性显著提升
- 数据规模:从 1 条演示扩展至 500 条生成轨迹。
- 数据多样性:场景数量提升 214 倍,物体种类从 1 个扩展到平均 20 个。
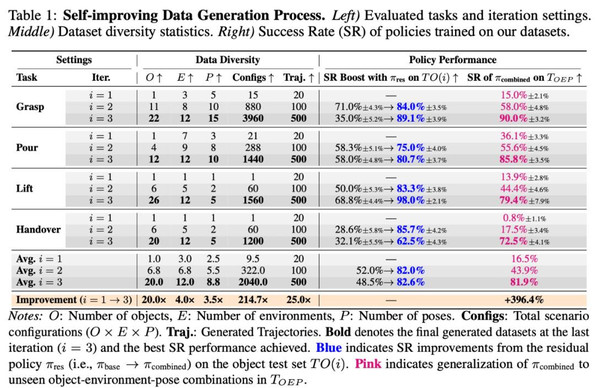
2. 策略泛化能力显著提升
在包含物体、环境、空间布局三重变化的挑战性测试集上,成功率从初始的 16.5% 提升至 81.9%。
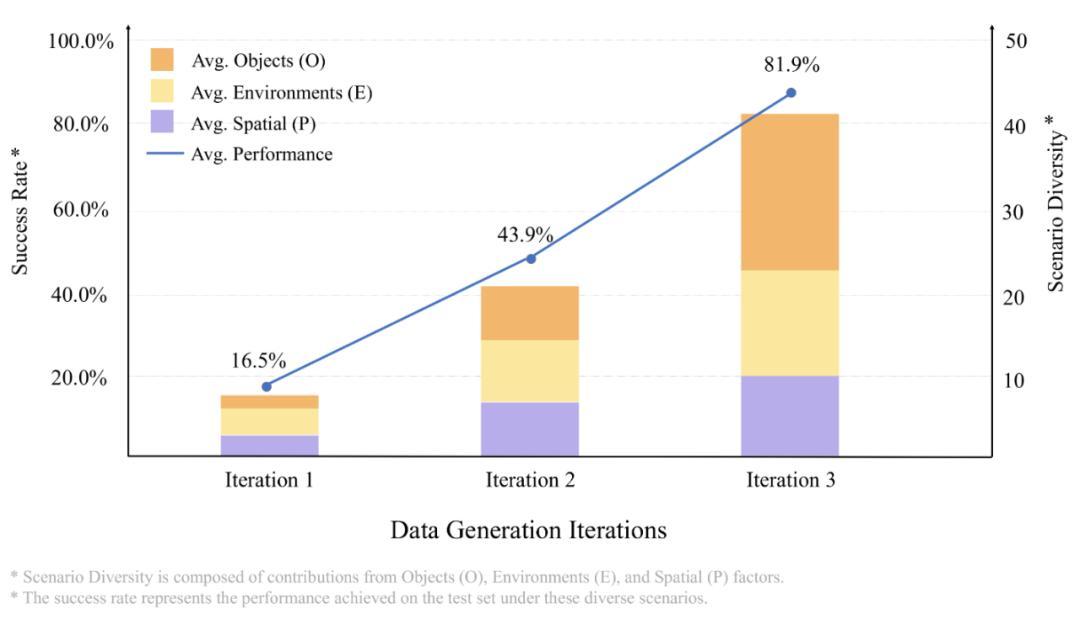
3. 全面超越基线方法
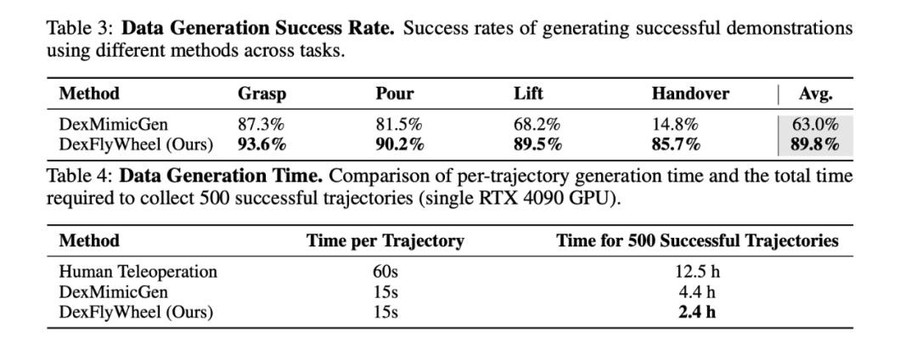
- 数据生成成功率:在多样且有挑战性的场景下,DexFlyWheel 数据生成成功率达到 89.8%,明显高于基于轨迹回放的基线方法 (63.0%)。
- 数据生成效率:生成 500 条多样化轨迹仅需 2.4 小时,相比人类演示和基于轨迹回放的基线方法,分别加快 1.83 倍 和 5.21 倍。
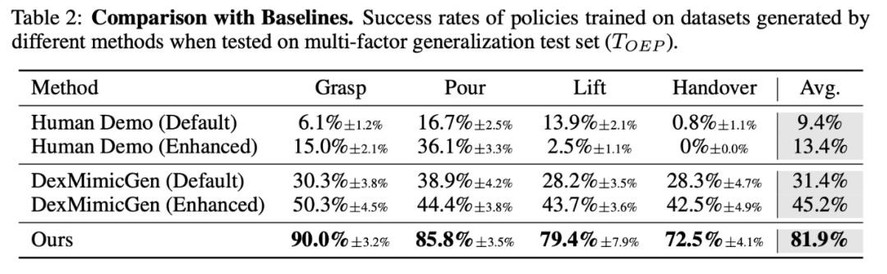
- 训练策略性能:在多样且具有挑战性的测试集上,策略成功率达到 81.9%,超过基线 DexMicmicGen (31.4%) 和人类示教 (9.4%)。
- 综合表现:在数据生成成功率、生成效率以及策略性能上,均显著优于基于人类示教和轨迹编辑的方法。
Demo 展示:轻松操控多样物体,
从容完成高难任务,丝滑展现类人操作
1. 对比 baselines:我们的方法可以操作不同形状的物体,并且适应高难度任务双手交接,同时动作更加类人

2. 仿真数据多样性:DexFlyWheel 数据不卷规模卷数据质量,通过 1 条演示启动生成了多样化场景下的数据,帮助提升灵巧策略泛化性。

3. 真机迁移:DexFlyWheel 进一步通过数字孪生技术将训练策略部署至真实双灵巧手机器人系统。在 “双手提起” 与 “双手交接” 任务中,分别取得 78.3% 与 63.3% 的成功率,验证了仿真数据生成在现实机器人部署可行性。

结语:数据飞轮——推动灵巧手走向现实与泛化
DexFlyWheel 针对灵巧手领域长期存在的数据稀缺问题,提供了一种自我提升的数据生成范式:
用模仿学习与残差强化学习构建了一个自我提升的数据飞轮。背后的思想是:解决数据难题的关键,并不在于一味收集更多数据,而在于让数据与系统相互迭代,让数据能够自己 “长大”。
与现有方法相比,DexFlyWheel 显著降低了数据收集成本,大幅提升了生成效率,并极大丰富了灵巧手数据的多样性。这一进展让灵巧手离现实应用与通用机器人更近了一步。
局限与展望
当然,DexFlyWheel 还不是完美的,未来工作正进一步完善这两方面:
- 奖励自动化:如何高效引入基于 LLM 的奖励设计系统,减少对人工设计奖励的依赖。
- 结合触觉模态:当前缺乏触觉感知,限制了在高精度任务中的表现;未来将引入触觉感知,进一步突破任务难度上限。
团队相信,灵巧手是未来通用机器人的必备执行末端,而持续生成高质量灵巧手数据的能力,则是推动灵巧手真正走向现实和泛化的重要一步。
















