
机器之心报道
编辑:冷猫、Panda
强化学习之父、2024 年 ACM 图灵奖得主 Richard Sutton 今天分享了他在 RLC 2025(强化学习会议) 和 AGI 2025 上发表的远程演讲《OaK 架构:一个基于经验的超级智能愿景》。

演讲中,Sutton 介绍了他认为有望实现通用人工智能乃至超级智能的路径:
- 他回顾了长期以来对简单且通用的 AI 智能体架构的追求
- 强调了从经验中学习、拟合世界的重要性
- 介绍了现有的常用智能体模型的架构及其缺陷
- 最终引出了演讲主旨:OaK 架构。
Sutton 在介绍 OaK 架构的基础上,也对实现 OaK 架构所需的八个步骤进行了详细拆解,并指出了目前未能实现的部分和可能的发展路径。可谓干货满满。
虽然说 OaK 架构并不是目前能够实现的完整算法或管线,只是一个愿景,但是 Sutton 为 AI(尤其是 AGI)的发展拆解了目标,提供了一张清晰的路线图和研究目标。
机器之心对 Sutton 的这次演讲进行了整理,以飨读者。

视频地址:https://www.youtube.com/live/XqYTQfQeMrE?t=22620s
OaK 架构目前还只是一个愿景,尚没有完整的算法,它还需要一些尚未实现的先决条件。这个先决条件就是一个能够不断学习和提升的深度学习算法。让我惊讶的是,到目前为止,我们都还没有这样一个算法。
在开始之前,我想介绍一下我创立的 Openmind Research Institute,这是一家研究与心智相关的强化学习方法的研究所。如果你是对此方向感兴趣的年轻人,可以考虑申请加入我们。
下面正式进入主题。这是本次演讲的提纲。
首先,我要介绍的是我追寻的目标 —— 一种简单且通用的 AI 智能体架构。然后我将介绍如何在这个大而复杂的世界中学习,之后将进入 OaK 架构本身以及超级智能的愿景。
Sutton 追寻的目标
我追寻的目标是一种简单且通用的 AI 智能体架构。

「通用」是指该架构不包含特定于任何世界的东西,因此其中不包含任何领域知识。
然后,该架构需要是「经验的(experiential)」,也就是说,它会随着运行时间经验(如上图右侧小图的红色箭头所示)而成长,而不是仅仅依赖某个专门的训练阶段。
具体来说,「经验」是指一种未经标注、未经解释的信息。由于我们追求的是通用设计,因此这些信息不包含任何与特定世界相关的内容。「观察」就只是一些信息、事物之间的差别,智能体需要通过自身的体验去理解和解释这些信息。
最后,也可能是最重要的一点,是「开放式抽象(open-ended abstraction)」的概念。我们希望智能体能够不断发展自身的概念(concept)体系、思维方式和行为中的常见模式,并且这种抽象能力在复杂性上不设上限,当然唯一的限制是它的计算资源。
为了帮助大家理解我的思路,我想说明:抽象通常有两种主要形式。
抽象本质上是指从世界中提取出某些「特征」—— 这些特征可用于帮助理解这个世界。这里所说的「特征(feature)」,可以理解为线索、方式、概念或者某种在试图理解世界时所构建出的信号结构(进而帮助你做出决策)。
因此,我们希望能够寻找「好的特征」,更准确地说,是「状态特征」(state features)。这是一类描述当前情境的有用抽象。其次,我们还需要寻找好的「时间抽象」(temporal abstractions),也就是比单一动作更高层次的行为单位 —— 一种在时间尺度上更大的「可以做的事情」。
比如说,「走去上班」、「打开门」或者「捡起一个物体」就是典型的时间抽象。我们接下来会详细讨论这些内容。
这正是我们所追求的目标。
从经验学习
这里,我要引入两个非常关键的概念:设计时(design time)和运行时(runtime)。

设计时是指智能体还未被部署到环境中、尚未开始获取奖励阶段的时间段。在这个阶段,人们可以将领域知识嵌入智能体中。当然,我本人并不推崇这种做法,反而希望尽量减少这种预注入。
而在运行时阶段,指的是智能体已经处于环境中,依赖经验进行学习、并制定与当前世界状态相匹配的规划。
我要重点强调的是在运行时阶段根据经验进行学习。
在一个庞大且复杂的世界中,情况往往是难以预判的。如果我们只依赖设计时的构建,这是远远不够的。尤其是当我们关注的是「开放式抽象」时,就必须依赖运行时去主动发现它们。那些在设计时就被预设好的「非开放式抽象」并不能满足需求。因此,一切必须在运行时完成,真正的智能必须靠运行时来驱动。
既然一切都需要在运行时完成,那为什么还要在设计时做任何事呢?事实上,这些预设反而会使设计更加复杂。因此,我们不妨将「设计」本身看作是对智能的一种理解方式,而非仅仅是为了制造某个产品。
如果你的目标是打造一个具体的产品,那么在设计时引入一些信息或背景知识可能是有意义的。但如果目标是理解「心智」的本质,那你就希望这个系统尽可能地简洁纯粹。也正因为如此,设计时我们应当尽量去除所有不必要的复杂性。
我想在这里再补充一点:如果我们的目标是理解智能,那么理想的智能体架构就不应该在设计时对任何特定世界做出预设承诺。
正如我在《苦涩的教训(The Bitter Lesson)》博客中所指出的:心智的实际内容,属于任意的、固有复杂的外部世界的一部分。

由于世界的复杂性是无穷无尽的,因此这种复杂性不应当被直接预设到系统中。相反,我们应当预设的,只是那些可以主动发现并捕捉复杂性的元方法(meta-methods)。我们所追求的是像人类一样具有发现能力的 AI 智能体,而不是那些仅仅包含我们已经发现的知识的系统。
这就是基本的思想,也因此,为了实现「通用性」,我们需要刻意弱化领域知识的作用。
那么,我想问大家一个问题:我们是否应该让智能体通过特别准备的训练数据进行学习?还是说,我们应该严格限制它只能通过运行时的经验来学习?

对我来说,答案是明确无疑的。我认为,这正是智能(尤其是强化学习)的真正力量所在:它能够从未经预设的运行时经验中学习。
因此,我想明确表达我的立场:智能体应该只从运行时经验中学习。
这正是我所说的「智能体应当是完全基于经验的」的含义所在。
世界太复杂,只能近似
我之前提到过「大世界」的视角。我们可以设想一下我们的智能体,它就像一个人,与这个世界相比,它是渺小的 —— 甚至是远远小于这个世界的。

这个世界不仅包含了各种物体、地点以及物理世界的复杂性,还包含了大量其他智能体。而这些其他智能体的内在心理活动,对于我们的智能体而言是极其重要的。
智能体之所以能做出「正确的行为」,是因为它能够与人类进行互动 —— 比如与它的上司、配偶、朋友。而这些人的内心活动对它而言至关重要,正如此刻你们在思考什么对我来说也很重要一样。
正因如此,世界的复杂性远远超出了智能体的处理能力,并且这种不对称是不可避免的。因此,智能体所学到的任何知识都不可能是「完全正确」的,它也不可能实现真正的「最优」行为。
凡是涉及「最优性」或「正确性」的定理,在现实环境中都不具备实际意义。我们必须清楚地认识到:这些定理在现实世界中的适用性是极其有限的,甚至是无关紧要的。
你所构建的价值函数必须是近似的,你的策略也必须是近似的。你的状态转移模型,尤其是你对整个世界的模型,必然要比真实世界简单得多。因此,它注定是不准确的,它只能是近似的。
甚至对于世界的某个状态,你都不可能真正将其完整地保留在大脑中,因为一个世界状态可能包含了其他所有智能体内心正在发生的事情。而你自己的认知能力,也不可能比所有其他智能体的总和还要复杂。因此,准确建模整个世界状态本身就是不现实的。
由此还引出一个更进一步、但更微妙的推论:世界在你看来是非平稳的(non-stationary)。因为你并不知道环境中真正发生了什么,它在不同时间点表现出的状态也会有所不同。例如,当你开车行驶在路上时,看到前方有一辆车,你并不知道它会向右转还是向左转。
当然,这种行为并非真正随机 —— 对方驾驶者脑中的决策过程可能是确定性的,但从你的角度来看,它表现出来的就是非平稳的:有时它转向右,有时转向左,行为似乎在变化。
因此,面对这些现实中的不确定性,你必须在运行时进行学习,在运行时进行规划,并且必须在运行时自主发现所需的抽象结构。你出生、成长、进入这个世界,而后必须逐步弄清楚:这个世界由哪些物体构成、有哪些人、这个世界是如何运作的、社会制度是如何组织的 —— 你必须在运行时去弄清这一切。这些内容不可能在设计阶段就预先嵌入,因此我们强烈主张应摒弃设计时注入的知识结构。
强化学习及其奖励
在介绍 OaK 架构之前,我先从更宏观的角度谈谈一般性的 AI 问题。AI 研究的目标是设计出一个有效的智能体,它能够在现实世界中完成目标。

强化学习研究的问题其实一样,只不过它采用了一种更具体的形式:用一个标量信号奖励来表示智能体的目标。关于这一点,我稍后进一步解释。
其次(这点更贴近强化学习的核心假设),我们通常假设世界是通用的,并且无法被完全知晓。这个「世界」可能是一个简单的网格环境,也可能是一个高度复杂的、充满人类行为的现实世界。它可能是随机的、复杂的、非马尔可夫的、非线性的。
正如我之前所说,它的状态空间可以说是无限的,并且它的动态演化在我们看来也是非平稳的。
我们必须在运行时进行学习与决策,并且这一过程不能依赖来自教师或人类的特殊训练信号。这是一个极具挑战性的问题,但我认为这个问题本身非常好,我们无需改变问题设定。我们已经拥有了「奖励信号」这一设定,这就足够了,我们只需要努力去解决这个问题即可。
我还想补充说明一点:在这里我们假设智能体的瓶颈是计算资源,而不是数据量。我们认为环境能够提供丰富的数据。因此我们希望使用流式算法来处理这些数据,而不依赖像 replay buffer 这类机制。
前面我提到,智能体的目标是通过一个标量信号来定义的。现在我想再展开讲一下,这就是所谓的「奖励假设(reward hypothesis)」。

奖励假设的核心观点是:我们所说的「目标」和「目的」,都可以被很好地形式化为最大化某个标量信号(即奖励)的累计期望值。
我认为,这一设定丝毫不是一种限制,相反,它是一种非常清晰、优雅的定义目标的方式。如果试图添加其他附加成分,不但不会更好,反而会削弱其清晰性。
已有一些理论工作探讨了这个假设。我推荐大家阅读 Michael Bowling 等人的论文《Settling the Reward Hypothesis》。

- 论文标题:Settling the Reward Hypothesis
- 论文链接:https://arxiv.org/pdf/2212.10420
此外,我们知道,即使是一个非常简单的奖励信号,也可能催生出智能的所有属性。当然,我不该说「我们知道」,更准确地说,我和一些同行主张并论证了这一观点:在一个足够复杂的世界中,一个简单的奖励就足以引导出智能的全部表现。这一点在我们的论文《Reward is Enough》中有详细阐述。
常用智能体模型
但正式开始介绍 OaK 架构之前,我希望先从一个「已有的经典架构」讲起,我称之为常用智能体模型(common model of the intelligent agent)。这个模型在许多学科中广泛存在 —— 无论是人工智能、心理学、控制论、经济学、神经科学,还是运筹学,大家几乎都采用了这一标准模型。
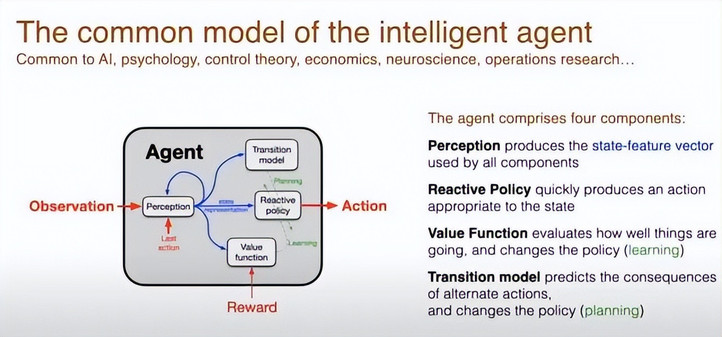
它所假设的智能体架构具有一些基本属性。
首先是上图中红色部分的那些元素,也就是经验接口(experiential interface):你会接收到奖励信号(reward),你可以采取行动(action),你会接收到来自环境的某种观察信号(observations)。
而这些观察信号通常是不充分的,它们无法完全揭示出环境的真实状态(也就是说,观察不能唯一决定状态)。
所以从外部视角来看,智能体的核心就是这三个「红色部分」组成的经验接口。
另一方面,实际上这个常用模型的核心内容,更多是关于智能体内部的四个组成部分:感知、价值函数、反应策略、转移模型。
图中蓝色部分,我们可以看到这些组件之间是如何互相连接的。这些连接也就是所谓的状态特征向量(state feature vector)。这是用来表示世界状态的方式。
状态特征向量由多个特征组成,每个维度代表一个抽象出的特征。这个向量的生成基本上就是对当前状况的理解。因此,当基于输入信号和过去的动作来构建对当前状况的认知时,用「感知(perception)」这个词来描述是非常恰当的。它就是你对世界的感知方式,表示你的当前状况。这种状态表示是你进行决策、选择行为的基础。
如图中所示,状态表示输入反应策略,然后得到行动的动作。这里的策略是反应性的(reactively)—— 也就是说,它不需要进行复杂的推理或规划,而是直接基于当前状态做出动作选择。
这就构成了智能体的前两个核心组件:感知系统(perception)和策略模块(policy)。这两者合起来就能构成一个完整的智能体。
但如果我们希望这个系统能够学习和改进,我们还需要加入第三个模块,即价值函数(value function)。价值函数可以提供这样的信息:「我现在的表现很好」或「我现在表现很差」,也就是说,它用来判断事情是变好了还是变糟了。
因此,它必须能够读取奖励(reward)信号。归根结底,价值函数本质上就是对未来奖励的预测。这个预测结果会被用来调整和优化策略 —— 我们用图中一条穿过策略模块的斜线来表示价值函数对策略的影响路径。
第四个组成部分是状态转移模型(transition model),它是我们用来进行规划的关键结构。状态转移模型的作用是:在给定当前状态的情况下,根据一个特定的动作,预测可能到达的下一个状态。
虽然我无法在这里详细展开它的全部工作机制,但总的来说,在规划的过程中,它同样会对策略结构产生影响 —— 我们可以用另一条穿过策略模块的对角线来表示这种影响。这种影响不仅作用于策略本身,还会反过来影响价值函数的学习与更新。
到这里,我们就构建了整个常用智能体模型(common model),它以学习与规划为核心,由这四个组件构成。
我认为有趣的一点是,这个单一模型框架,几乎可以涵盖多个不同学科的建模方式。例如,在控制论中,相同的概念会用不同术语来表述:它们不说「动作(action)」,而说「控制量(controls)」;不说「奖励(reward)」,而说「收益(payoff)」或「代价(cost)」。在心理学中,我们可能也使用「奖励」一词,但我们不会说「观察(observations)」,而是说「刺激(stimuli)」。
总之,这些学科尽管术语不同,但底层思想是高度一致的。
OaK 架构
那么,关键问题来了:这个常用模型究竟缺失了什么?为什么我们不能就此止步?
核心缺失在于:这个模型虽然完整,但它仍然停留在低层次的表示上。动作是瞬时的,奖励是瞬时的,观察也是瞬时的。而我们所追求的智能行为,必须涉及到更高层次的抽象。
我们需要发展出概念(concepts),发展出一整套高级思维方式(ways of thinking)。
因此,在这个常用模型基础上,我认为最需要补充的就是开放式抽象(open-ended abstractions),这正是 OaK 架构试图引入的新要素。
来看 OaK 架构的设计图。这里使用了紫色来标示所有新增的内容。OaK 架构的关键扩展,是引入了一系列辅助子问题,这些子问题是相对于主问题(获得奖励)而言的「次级任务」。
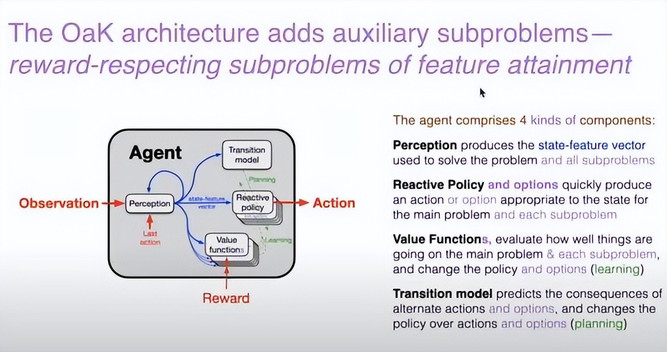
主任务仍然是:最大化奖励。而这些子任务,我们即将反复看到一个术语:「与奖励一致的特征达成子问题(reward-respecting subproblems of feature attainment)」。
也就是说:每一个子任务会围绕某个特定特征展开,试图去达成这个特征目标,但前提是:在完成这个目标的同时,不能牺牲太多主任务的奖励,仍然要保持整体的奖励水平不被严重削弱。
从图上看,整个架构与之前几乎相同。但有一个关键变化:在原有的策略之后新增了一组被称为「选项(options)」的结构,它们可以理解为更高层次的策略;而在原有的价值函数之后也增加了多个新的价值函数。
这是因为每一个子问题都是一个独立的问题,因此必须为每个子问题配备一个独立的价值函数,以衡量当前在该子问题上的表现好坏。因此,系统中需要更多的价值函数来支持多个子任务的评估。
因此,现在该架构有四类组件:虽然感知和状态特征向量的机制保持不变,但策略和价值函数这两个部分现在都变成了多个。
我们仍然保留之前的感知模块,负责生成状态特征向量,这个向量会被所有子任务共享。
现在每个子任务都拥有自己的一组选项策略,用于制定适合该任务的行为方式;而对应的,每个子任务也拥有一个独立的价值函数,用于评估当前行为在该子任务上的效果。
图中没有直接把「子问题」明确画出来。因为在架构中,我们并不需要为每个子问题构造一个明确的「对象」。我们只需要为它定义一个对应的价值函数即可。
图中那些从特征向量上延伸出来的蓝色小箭头表示:每一个价值函数都试图从共享的状态特征向量中提取出与自己任务相关的那一部分特征进行优化。
现在我们稍作停留,来谈谈状态转移模型(transition model)。我希望用一个更具哲学意味的词来定义它:知识(knowledge)。
我们的所有知识,其实都体现在状态转移模型之中。也就是说,它代表了我们对世界的理解:当我们采取某种行动时,世界将如何变化。特别是当我们采取那些更高层级的复杂行为 —— 也就是所谓的「选项(options)」时,世界状态可能发生的变化。
「OaK」这一架构名称,正是来源于这两个关键词:Options(选项) 和 Knowledge(知识)。

所谓「选项」,指的是一种更高层级的行为方式。但形式上它非常简单,由两个部分组成:一个是策略,一个是终止条件。
策略的含义是:它是一个函数,将状态映射到底层动作上的概率分布;而终止条件则是将状态映射到当前是否应该终止该选项的概率。
OaK 架构中会有大量的选项 —— 通常是针对每一个数值型特征设立一个选项。系统会学习:如果持续执行该选项直到终止,会发生什么,这就是我们所说的「知识」的形式。
比如:「如果我捡起一个物体并握在手中,那会是什么感觉?」、「如果我下楼走进厨房,会在那里遇见谁?」、「如果我去冰岛旅行,可能会遇到什么样的人?」、「如果我去听一场讲座,我能学到什么?」
这些内容,构成了你对世界的预测性理解,也就是一种高级的状态转移模型,它能够让你在计划过程中考虑更大的跳跃,并希望能够「在世界的自然结构处切割它(carve the world at its joints)」。
整个 OaK 架构的运行涉及八个步骤,这些步骤都将在运行时并行执行。我会逐步展开解释,但你可以先整体浏览一遍流程:
(1) 学习用于最大化奖励的策略和价值函数;
(2) 生成新的状态特征;
(3) 对这些特征进行排序,确定其重要性;
(4) 基于排名靠前的特征,构建对应的子问题;
(5) 为每个子问题学习解法;
(6) 为每个子问题的解法学习对应的状态转移模型;
(7) 执行规划;
(8) 维护关于整个系统中各项元素效用的元数据。

距离实现还有多远?
接下来将逐步评估:现在这些步骤真的可以做到吗?
学习用于最大化奖励的策略和价值函数
这是强化学习中的经典任务,我们已有成千上万种算法可以实现它。
但我认为它尚未被完全解决。要说它被解决的前提是:我们能够真正高质量地实现持续性深度学习。而正如我在一开始所说的,这正是目前尚未突破的关键前提技术。

其实我们对它的需求早在 40 年前就已经非常明确。
对于线性网络来说,我们确实可以做到可靠的持续学习;但一旦涉及到非线性深度学习网络,系统在持续学习的过程中就会出现灾难性失效,特别是在尝试保留旧知识的同时学习新知识时。
最为人所知的现象就是「灾难性遗忘(catastrophic forgetting)」。这早在 1990 年代就被发现了。更近的研究显示,我们不仅会忘记旧知识,甚至会出现学习能力完全丧失(loss of plasticity)的现象。这个问题在我自己的实验室以及其他研究机构中都已被反复证实。
近几年出现了一些部分性的解决方案。我们现在可以在一定程度上使用持续性反向传播(continual backprop)来实现一定程度的持续深度学习。另一个可能有前景的方向是:持续发现新的特征表示,以及使用自适应步长机制(adaptive step sizes)。
我确实相信,在未来几年内,我们总会以某种方式实现可靠的、持续性的非线性学习。因此,我认为现在假设它将会实现,并在 OaK 系统架构中基于它的存在来进行设计,是合理的。
生成新的状态特征
这里我要强调的不是「挑选出最好的特征」,而是要生成大量候选特征。
我认为这是一个至今仍不清晰的领域,有很多不同的尝试。

OaK 架构依赖于状态特征的持续发现,而这其实是一个非常老的问题,早在上世纪 60 年代就已经被提出。如果你对历史有所了解,可能听说过它的很多别称,比如「表示学习(representation learning)」、「新术语问题(new terms problem)」以及「元学习(meta-learning)」,本质上都在谈同一类问题。
而众所周知,反向传播曾被认为能解决这一问题,但实际上它并没有。
但现在我们普遍承认,反向传播其实并不能真正发现「好的特征表示」。它只是在某种「被动意义」上实现了目标,泛化能力差,而且也不是显式地在学习这些表征。
另一些方法则基于「生成并测试(generate-and-test)」策略,这一思路可以追溯到很久以前。持续性反向传播就是一种基于生成并测试思路的新算法。
我认为,这一领域目前仍属于未解问题,我们必须找到一种能够从现有状态特征中有效生成新特征的方法,我会在 OaK 架构中假设这种方法是可用的。
我个人最青睐的解决思路是一个名为 IDBD(Incremental Delta-Bar-Delta) 的算法,我认为它将在未来的方案中扮演重要角色。

- 论文标题:Adapting Bias by Gradient Descent: An Incremental Version of Delta-Bar-Delta
- 论文链接:https://cdn.aaai.org/AAAI/1992/AAAI92-027.pdf
特征排序
我认为这一步相对容易。排序标准也很清楚,只需回答这些问题即可:这些特征是否对子任务有用?是否对智能体整体表现有帮助?是否被模型的学习过程所实际使用?
我们可以简单观察这些特征是否在系统中被频繁使用,从而据此进行排序。
基于排名靠前的特征,构建对应的子问题
我特别想讲一讲这一步,因为我实际上认为它是可行的,而且我们已经在实验中实现过了。

那么,如何构建子问题呢?
首先必须承认:关于「辅助子问题(auxiliary subproblems)」,已有很长的研究历史。有些问题已经基本达成共识,但还有很多问题仍然悬而未解。
我们需要认真思考这些开放性问题:
- 子问题应该是什么?
- 它们从何而来?
- 智能体是否能够自主生成子问题?
- 这些子问题又是如何帮助主问题(最大化奖励)实现的?
OaK 架构正尝试为这些问题给出统一解答。
我认为,我们所说的「子问题」在现实中最直观的体现就是「试玩(play)」,可以把它看作是个体在尝试获取某种特征的过程。如果你回顾一下动物,甚至人类的一生,你会发现,我们的生活中充满了各种子问题。
试玩或者说玩耍可被看作是个体在尝试关注某种特征的过程。
这是一个人类的例子:婴儿在玩耍。它的行为并非随机。它与玩具互动,学到了一些东西,当发现无法再继续获得新信息时,它就会转向下一项学习机会。
我们通常称之为「好奇心(curiosity)」,但我们也可以用「特征达成的子问题」这一术语来理解它:某些体验包含颜色、触觉、声音等感受,婴儿试图再现这些体验,这就是它探索世界、表达好奇的方式。说到底,这就是在逐步获得对环境的控制力。

因此显而易见,一个智能体必须自行生成子问题。我们不可能预先内嵌所有潜在的子问题。

幸运的是,我们已经拥有许多可用的算法机制来支持这件事:我们拥有选项,拥有价值函数,拥有离策略学习和各种规划方法。
那么,我们该如何实现这一目标?什么样的任务才适合作为子问题?
我提出的解决方案是:与奖励一致的特征达成子问题。
这个方案的合理性来自我们不能使用其它东西。比如你无法直接使用「状态」—— 因为智能体根本没有对全局状态的访问能力;你也无法直接描述「物体」—— 因为我们并没有先验定义的物体结构。我们唯一拥有的,就是一系列特征与概念,而它们是智能体在理解世界过程中自我构建的内部结构。
下图展示了 OaK 根据特征创建子问题的方式:

构建子问题的目标是:将环境引导至一个该特征值较高的状态,同时又不能损失太多主任务的奖励。详见以下论文:

- 论文标题:Reward-Respecting Subtasks for Model-Based Reinforcement Learning
- 论文链接:https://arxiv.org/pdf/2202.03466
为子问题学习解法与状态转移模型
接下来,我们需要做两件事:
一是学习这些子问题的解(solution),二是学习这些解对应的转移模型。而这些「解」,就是我们所说的选项(options)。我认为这两步本身并不复杂,前提是我们能够可靠地进行持续深度学习。
现在进入 OaK 架构的核心部分。
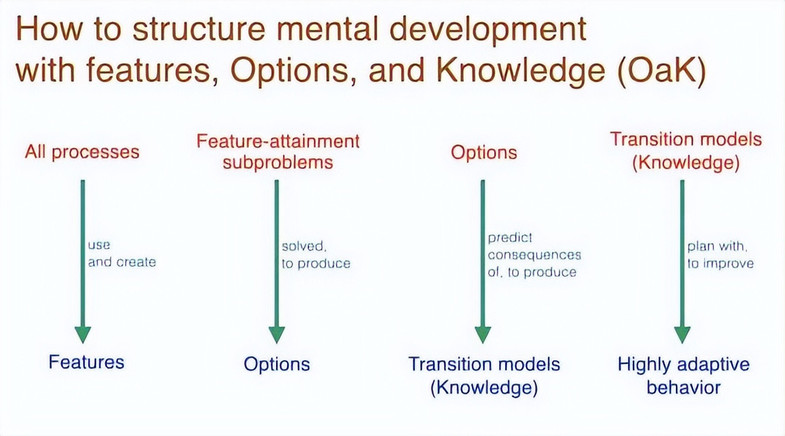
我们将进行一系列学习过程,这些过程既会利用已有特征,也会推动新的候选特征的生成。
也就是说,我们将首先获得一组特征,然后基于这些特征构建子问题,每个子问题的目标就是实现对应特征的达成。接下来,我们会逐个解决这些子问题。
如果我们定义了 1000 个子问题,我们就会训练出 1000 个选项作为对应解法。
每个选项都将成为一个预测问题的基础单元:「如果我在当前状态下执行这个选项,会发生什么?」
这就是所谓的状态转移模型 —— 它用于预测特定行为方式的后果。
请注意,这种预测过程与「解决子问题」是不同的:「解决子问题」意味着找到一种高效的行为方式,用于达成目标特征;而状态转移模型则要求我们考虑行为方式的所有潜在后果。
比如,如果我走下楼去厨房,我可能确实抵达厨房了;但我也可能遇见我的伴侣,或者在楼梯上摔倒。
也就是说,可能发生的事情远不止一个,我们需要能够预测这些多样化的后果。
这就是状态转移模型。一旦我拥有这些模型,就必须用它们来进行规划,从而改进行为,并有望实现高度适应性的行为。
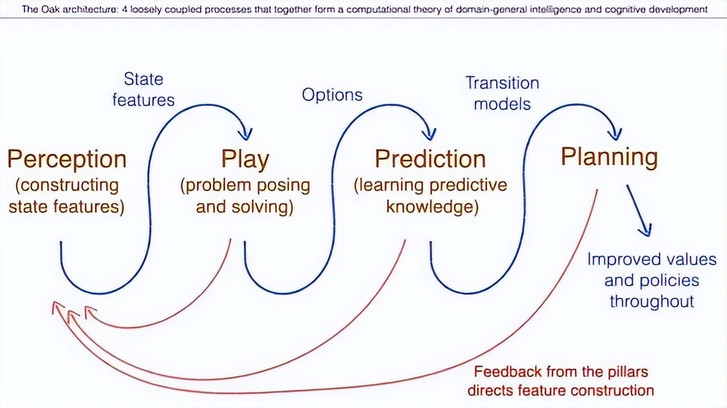
可以从上图中获取更直观地了解到:感知提供特征,得到了状态特征。为了解决这些子问题,与世界互动并获得选项。我预测这些选项的后果,于是得到一个转移模型。这个转移模型通过规划提供了改进的价值函数和值策略。接着,所有这些后续步骤会反馈回来,并影响感知。
执行规划
规划是一个很大的话题,但目前已经可以实现 —— 我就有一个具体实现规划的规划。
为什么我们要进行规划?因为世界变化,价值也会随之变化。换句话说,建立正确的模型比建立正确的价值函数更容易。

比如说,找到通往洗手间的路在某些时刻是非常重要的,但「在洗手间」的状态的价值是会变化的。
通俗来说,有时候我想去洗手间,有时候我不想去。但是「如何去洗手间」这个选项的模型 —— 我希望能够一直保留它,即便我当下是否想去的意愿发生了变化。为了应对这种情况,必须提前做好准备,而这具有深远的意义。
我设想的规划是通过价值迭代来完成的,通过这个过程你可以改进你的价值函数,从而知道哪些状态是好的、哪些状态是你想要的、哪些特征是你想要实现的、哪些是不想实现的。
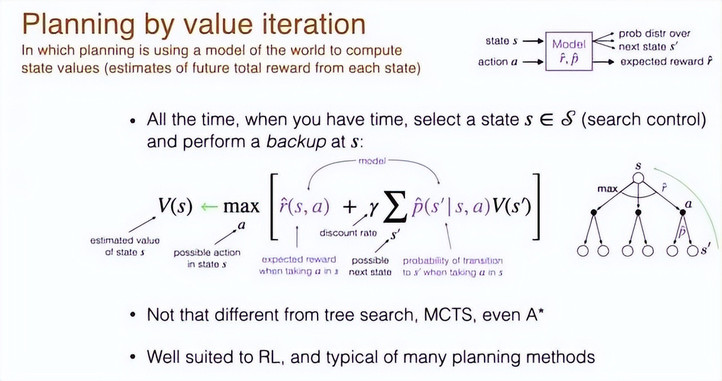
这个公式是经典价值迭代的表达。经典价值迭代针对的是离散状态的情形,可以有一个表格来存储每个状态的价值。
价值迭代会持续不断地进行,你要做的是在空闲时间思考选择一个状态,而如何选择这个状态是一个重要的问题。然后你在该状态上执行一个备份(backup)操作。这个状态的备份会改变该状态的估计价值。然后,你要对所有你可能执行的所有行为取最大值。然后检查预期会得到的奖励。
从下图我们可以看到模型。这就是世界的模型,这个模型接收一个状态和一个动作,然后预测下一个状态的概率分布,并预测期望奖励。
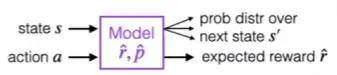
这就是一个原始模型,但不是高级模型。
价值迭代是为原始模型、低层模型定义的。其中有期望奖励和下一个状态的期望值。模型会对所有可能下一个状态的概率和该状态的值进行加权求和,并进行一点折扣。
你现在处于状态 s,观察所有你可能采取的动作和由此导致的状态,然后你评估最有可能发生的情况,并将这些信息反向传播回来,更新当前状态的价值。
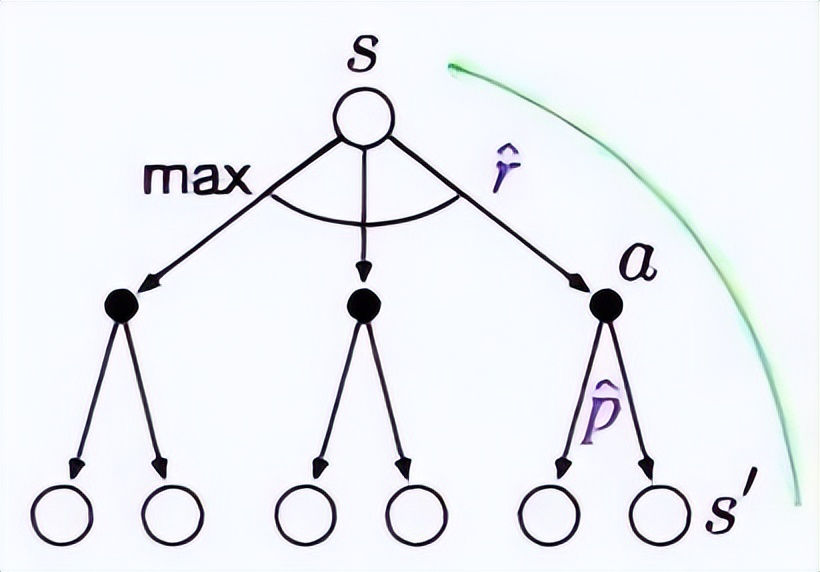
所有的规划方法本质上都与之类似。有些方法看起来和这个价值函数形式完全一样。
即使是 A* 方法、蒙特卡洛搜索和模型预测控制等方法,它们也都包含这个基本思想 —— 让模型向前看,预测后果,然后更新模型对不同状态或不同选择的价值的理解,最终据此做出选择。这就是价值迭代。
然后,当我们将其抽象化后,我们就能「跳跃」,也就是说,在世界中采取较大的步骤。这是下一个阶段。
生活是一步一步过的,但你对生活的规划却是在更高的层次上进行的。

所以转移模型(我称其为「知识」)是关于这些大尺度动态的,其中你的动作或选择(即选项)是有目的性的。我们的知识不是建立在单个动作上的,而是建立在更高层概念上,例如叫 Uber 去机场、去冰岛旅行、去洗手间或捡起一个物体。
我们的知识是关于选项的。所以选项模型就是我们上一页讲过的常规模型的泛化版本,我们把其中的 action(动作)替换为 option(选项),输入就是我可能做的所有事情,也就是一系列扩展的行为方式,而输出的不是下一个状态,而是当选项终止时我最终到达的状态。

并且我们不再关心一步的期望奖励,而是关心从开始到终止的总期望奖励。
除了这两个变化,价值函数的计算方式仍然是一样的。我们仍然会对所有可能的后续情况求和,获取奖励,以及在终止状态下的期望值。核心思想是相同的。
所以我们可以在抽象层级上使用价值迭代进行规划。接下来我还需要说明一下我们是如何将这一方法泛化以支持函数近似的。因为世界太大了,我们没有办法为每一个状态都定义一个 V (s)。我们并不拥有世界中每一个状态的具体价值函数,但我们拥有通过权重向量(参数)决定的状态价值函数。

因此,我们可以使用一种近似方法来表示世界状态。这个状态将通过观测、特征向量表示,并结合参数,生成一个估计值。
所以很自然地,模型也会变成参数化的。我们会预测整个过程中的奖励,并预测到终止状态的转移概率,这些也都将通过参数来表示。
所以我们不再使用传统的表格方式,而是通过梯度方法更新权重。
现在,我们的期望奖励是基于模型、转移模型以及其参数而得出的;转移概率也是基于参数而得的;接着有估算出的值。这个 b (s,a,w) 相当于括号中的那一部分,它就成了学习的目标值。
我们现在已经回到了使用单一动作原语来进行函数近似的阶段。这个方法也可泛化到完整的选项(option)情形。
维护关于整个系统中各项元素效用的元数据
最后一步,是我们必须为所有内容记录统计信息或元数据,特别是关于转移模型的质量信息。因为模型是近似的,我们需要学会识别模型在哪些地方能提供可靠的答案,在哪些地方不能。
我们还必须对特征本身记录统计信息,这样在生成新特征时,就能根据已有统计信息来指导特征生成过程,判断哪些特征是好的,哪些是不好的。
下面归总一下,图中勾的颜色代表了这八个步骤能否做到:蓝色表示如果能实现持续深度学习与元学习,这部分就可以完成;红色表示有很多想法,但没有具体方案;黄色表示看起来很容易,但必须等其他部分完成之后才能进行;绿色表示似乎已经能够做到。

总结
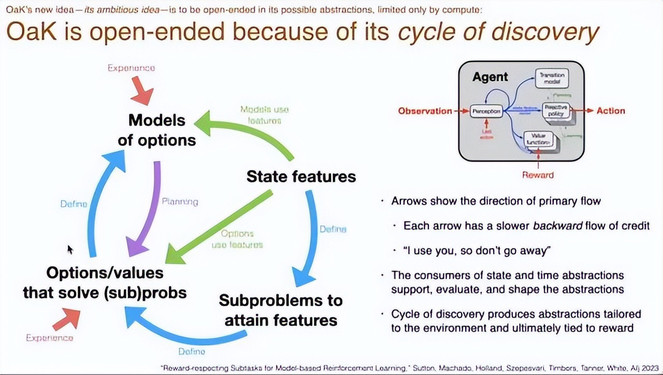
OaK 是开放式的,包含不断探索的新循环。
这正是 OaK 的新想法:它的抽象过程是开放的,唯一的限制是计算资源。
基本循环如下:我们从状态特征开始,基于这些状态特征构建子问题,然后解决这些子问题以产生选项,再基于这些选项构建选项模型,通过规划过程来改进选项和策略。
这一系列步骤都会使用状态特征。虽然箭头是单向的,但实际上存在反向影响:我们会告知状态特征哪些是有用的,哪些是无用的。
正是 OaK 得以开放演化的核心所在:通过这样一个循环,系统不断发现更优的抽象,而这一切最终都与「奖励」紧密相关。
请记住这个追求:我们追求的是泛化性、经验性和开放式的抽象能力。我想,也许你已经能看到这个愿景如何为你提供一条实现这些目标的道路,尽管它仍有一些前提条件尚未解决。
因此,OaK 提出了一种通过运行时经验发展超级智能的愿景。
















