AI数据分析工具层出不穷,但真正能为产品经理提供“有用、有用、有用”的商业洞察的,到底有哪些?本文通过实战测评,聚焦产品人最关心的9个关键问题,全面评估主流AI分析工具的能力边界与使用体验。

市面上各种AI工具吹得天花乱坠,产品经理使用AI进行商业洞察也越来越普遍,但到底哪个是真能打的实干家?哪个只是个花架子?我们将用一次真实测评的系列文章来一探究竟。
单一场景的数据分析应用难免过窄,这次我们用一份完整的AI洞察报告来说话,这可不是纸上谈兵,我们模拟的是真实商业场景,你就是那个要拍板做决策的产品总监,给你一份AI生成的报告,你得能看懂,觉得有启发,还能知道下一步该咋干,这三样缺一不可。所以我们的评判标准就非常实在。

这份报告看起来专业吗?他给我的发现是不是那种醍醐灌顶的感觉,而不是老生常谈?最后看完报告我是不是心里有数了,知道该怎么改进产品了?
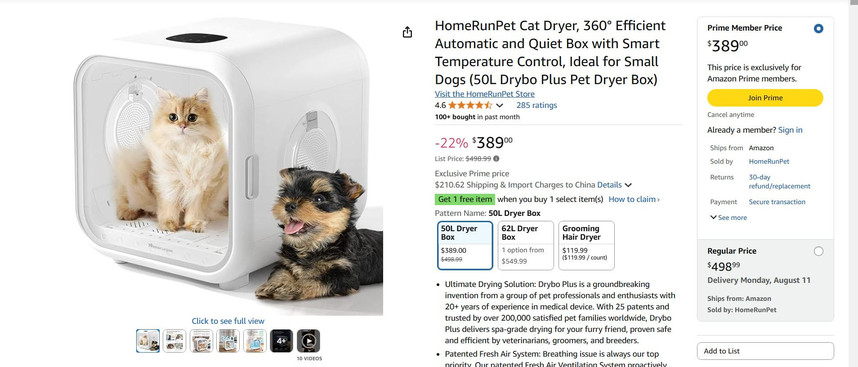
本次测评由资深商业分析师亲自操刀,找来544条亚马逊上美国用户对宠物烘干箱的真实评论数据,这可不是随便抓来的数据,都是实打实的用户心声,任务也很明确,所有参赛的AI模型,拿到同样的数据,用同样的指令,直接生成一份可以直接拿给老板看的html分析报告,看看谁能在最短的时间内把这堆原始数据变成最有价值的商业洞察。
参赛选手包括云听AI这样的专门研究用户洞察的垂直领域模型(数阔大模型),还有像Claude、Kimi、 Gemini 这些通用大模型的组合拳,怎么评判好坏呢?我们用了个四维评估法,简单直接。

第一,数据靠谱吗?别给我整些胡编乱造的东西。
第二,报告长得专业不专业,结构清不清楚,图表好不好看,能不能让人一眼就明白重点?
第三,也是最重要的,是洞察发现有没有意思,是不是那种让人拍大腿哟,原来如此的深刻洞察,而不是我早就知道了这种废话。
第四,给出的建议能不能落地,看完报告能让人知道下一步该具体做什么了吗?是光空喊口号,还是给出了实实在在的行动指南?我们会根据这四点给每个报告打分,从优秀到待改进。
测试之前我们需要准备好提示词。因为云听AI本身就是垂直大模型,所以提示词只需要把讲清楚需求即可:
我在做一款猫狗吹风机盒的产品,我已经从亚马逊找了竞品并把评论数据爬了下来,文件夹中的两个excel文件就是。 接下来,需要你基于这几个产品的评论,帮我做洞察产品创新升级,对现有产品的缺点分析+用户人群的洞察+产品创新方向。
但对其他的通用大模型,还是需要设计结构化的提示词才能完成数据分析要求,当然本次测试的所有模型都按照以下同一个提示词来生成:
我在做一款猫狗吹风机盒的产品,我已经从亚马逊找了竞品并把评论数据爬了下来,文件夹中的两个 excel 文件就是。 接下来,需要你基于这几个产品的评论,根据以下报告要求,帮我做洞察产品创新升级,对现有产品的缺点分析 + 用户人群的洞察 +产品创新方向
注意不是直接看数据给结论,而是要通过python 对表格进行处理、做数据分析等,最终形成一份完整的 HTML 报告。
注意保留所有过程在文件夹中。
分析要求:
“`
# 角色与目标
你是面向管理层的「商业洞察分析师」。基于当前文件夹的两份 xlsx 评论数据,生成一份 **可直接交付给决策层** 的 **中文 HTML 报告**。报告必须做到:
– **看得懂(专业度)**:结构清晰、图文并茂、阅读流畅。
– **有启发(洞察力)**:不仅复述常识,还要提出“异常信号”(非显而易见的关键洞察)。
– **能落地(商业价值)**:给出具体、可执行、可验证的产品创新与优化建议。
– **数据准确性**:报告开头提供「数据说明模块」,全篇数字前后一致,关键结论可追溯到原文与元信息。
> 严禁编造数据或引入外部信息。所有结论均需来自我上传的数据,并附**原文证据**(评论片段+星级+日期+品牌/ASIN)。
—
# 输出格式(重要)
– 输出 **完整的单页 HTML**(包含 `<html>…</html>`),**内联 CSS**,无需外部依赖。
– 页面需有 **目录/锚点导航**(例如:概览、表现分析、用户热点、痛点、场景关联、洞察与建议、附录)。
– **图表数量 ≥ 6**(柱形/折线/堆叠条形/雷达/热力/占比等均可),每个图表下方**必须**有 1–2 句中文解读。
– 页面顶部提供 **「一页纸高管摘要」**(Executive Summary):3–5 个要点,涵盖关键发现与行动建议。
– 统一文风:简洁专业;所有关键名词对应到数据(n、占比、日期范围)。
– 不要在主报告内嵌 Base64 图片或大型 SVG/JS 图表**。所有图表请**以 <iframe> 引用外部 HTML 图表文件**(生成到 /charts 目录)。主报告需要在图表处提供 **iframe 嵌入。
– 若外部图表文件不存在,显示**降级占位文本**,不影响主报告阅读。
—
# 统一名词与证据链要求
– 每条关键结论或建议,**必须**附 1–2 条**原文引用**(评论片段,保留英文原文或中文翻译)和基础元信息:`品牌/ASIN、星级、日期、ReviewID(如有)`。
– 在报告末尾设置 **「证据链与抽查区」**:集中展示 10–20 条能支撑关键结论的原文与元信息(便于核对)。
– 所有品牌/产品命名保持一致;若同一品牌多款 ASIN,需在图表/表格中清晰区分。
—
# 「异常信号」明确标准(用于提升洞察力得分)
将如下内容标注为【洞察卡片|异常信号】并单独成节展示(≥3 条):
– **低频但高严重度**的问题(例如涉及安全/健康/重大体验风险),每条卡片至少附 **2 条**原文证据。
– **跨维度关联**才成立的发现(如:特定场景×特定人群×特定部件 → 异常集中)。
– **时序反转**或口碑拐点(例如:新品版位上线后,某问题在 2 个月内骤增)。
– **品牌/型号差异驱动**的“反常”表现(如:高价型号在“价格价值”维度反而更差)。
每条异常卡片包含:现象描述 → 影响对象/场景 → 可能成因假设(基于证据)→ 建议的验证方式(如复测、试销、客服抽样口径)。
—
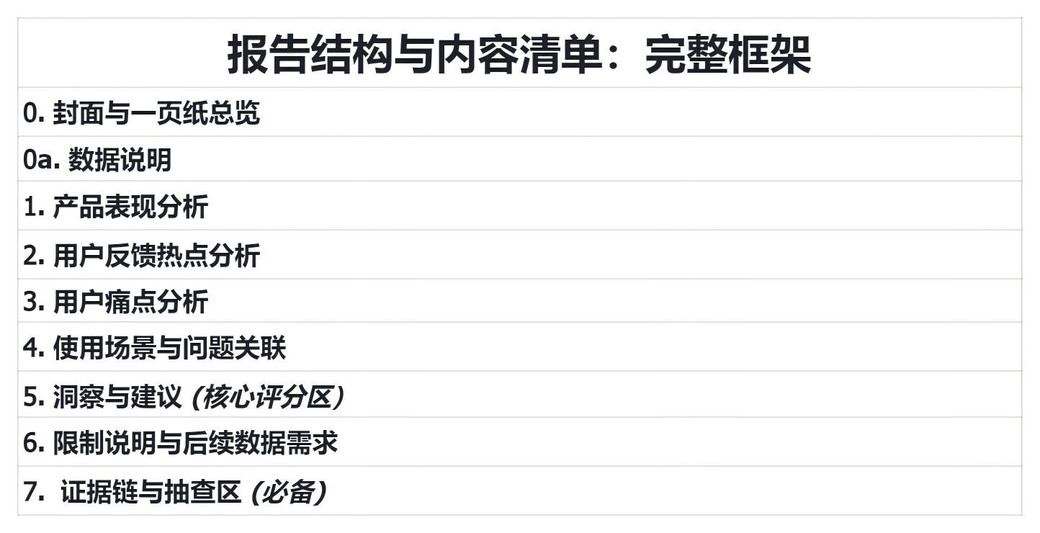
# 报告结构与内容清单
##
0. 封面与一页纸总览(Executive Summary)
– 关键发现(3–5 条,含 1–2 条异常信号)
– 关键指标快照:总评论数、时间范围、品牌/ASIN覆盖、好评率概览
– 首要行动建议(3–5 条,短句)
## 0a. **数据说明(Data Notes|必备)**
– **数据来源与范围**:文件名/抓取渠道(简述)、**时间窗**、**总样本量 n**
– **覆盖口径**:涉及的品牌/ASIN 列表(可表格化)
– **预处理口径**:去重原则、语言/翻译处理(是否机翻)、极端/无效评论剔除规则
– **一致性声明**:本文所有图表与表格使用同一数据快照;数字在各章节保持一致
– **局限性**:样本偏倚/时间窗口/缺失字段等
– **快速核对表**(表格):`总评论数`、`各品牌评论数`、`时间范围`、`平均星级/好评率`等关键数据
##
1. 产品表现分析
– **好评率排行榜**:按品牌/产品展示,支持按产品线/价格段筛选的视角(静态 HTML 可用多张图模拟不同切片)。
– **关键指标雷达图**:维度建议(性能、外观、体验、易用、安全、耐用、价格价值);**至少一个**与主竞品的雷达对比。
– **生命周期追踪(趋势)**:最近 12 个月/可用时间窗内的评价趋势,标注口碑拐点或促销期效果。
##
2. 用户反馈热点分析
– **喜爱点 TOP10**:从正面评价中提取最受赞誉的特性(按情感强度或提及度排序),配 “代表性原文” 证据。
– **用户群体偏好**:按可识别的人群标签或使用场景(多宠、长毛、敏感、洗澡后、小户型等)给出差异化偏好解读。
##
3. 用户痛点分析
– **吐槽点 TOP10**:从负面评价中提取高频问题,以**严重度×频次**排序(文字描述即可,不引入技术指标)。
– **问题趋势监控**:展示 2–3 个关键问题的时间变化,标注是否为“新兴痛点”。
##
4. 使用场景与问题关联
– **高风险场景 TOP5**:列出问题集中爆发的场景(示例:洗澡后、夏季高温、多宠同烘等)。
– **场景-问题映射**:热力/矩阵图展示各场景对应的具体问题分布,并配针对性建议的要点提示。
##
5. 洞察与建议(核心评分区)
– **【洞察卡片|异常信号】≥3 条**(见“异常信号标准”),每条卡片必须附 2+ 原文证据及元信息。
– **产品创新方向**(区分层级)
– **战略级(3–5 条)**:面向人群/场景的差异化方案,如结构/安全机制/智能温控的系统性升级,需给出简短的**验证思路**(如试产、A/B、口碑指标)。
– **战术级(5–10 条)**:可立即执行的优化,如风道设计、噪音控制模式、清洁便捷度、门锁机制等,**指向明确部件或交互**。
– **验证与落地建议**:为关键建议配“可验证要点”(如退货理由中的相关占比下降、客服低星占比下降、测评博主正面提及数上升等),不需要复杂统计,仅给出验证口径。
##
6. 限制说明与后续数据需求
– 说明该数据的覆盖范围/时间窗限制;列出为进一步提升结论所需的补充数据(如售后/退货原因、配件更换记录等)。
##
7. 证据链与抽查区(必备)
– 列表形式展示 10–20 条用于支撑关键结论的原文引用,附:品牌/ASIN、星级、日期、ReviewID(如有)。
– 将对应的结论/图表位置做锚点标识(如“证据用于:吐槽点#2、异常卡片#1”)。
—
# 图表与可视化规范
– **至少 6 张图**,推荐组合:
1) 好评率排行榜(横向条形图);
2) 品牌/型号雷达对比;
3) 评价数量或好评率时序折线;
4) 喜爱点 TOP10 条形;
5) 吐槽点 TOP10 条形;
6) 场景×问题 热力/矩阵。
– 每张图 **必须**有中文标题、数据来源说明、1–2 句“如何读取此图”的解读。
—
# 写作与呈现要求(对应三维评估)
– **专业度(结构清晰)**:严格采用「总览 → 证据 → 结论 → 建议」的叙述节奏;段落短句化;关键数字加粗。
– **洞察力(异常信号)**:避免只做高频词复述;突出“少量但关键”的非显而易见发现,并指出场景/人群差异。
– **可落地(行动方案)**:所有建议必须能直接进入评审;建议落到“具体部件/交互/机制”,并附简单的验证口径。
—
# 自检清单(生成前最后一步)
请在 HTML 尾部以隐藏注释 `<!-
– checklist –>` 形式自检并写入:
– 图表是否 ≥6?每个是否有解读?
– 是否有 ≥3 条「异常信号」且各有 2+ 条原文证据与元信息?
– 一页纸摘要是否覆盖关键发现与行动建议?
– 结论与图表、证据链是否一一对应?
– 是否完全基于我上传的数据,未引入任何外部事实?
> 若以上任一项不满足,请自动补齐或调整后再输出最终 HTML。
“`
这个提示词要求AI扮演一个面向管理层的商业洞察分析师,报告必须做到看得懂、有启发、能落地、数据准确。特别强调了不能编造数据,所有结论都得从我们上传的数据里来,并且要提供证据。输出格式也规定好了,必须是完整的html报告,包含目录图表,还得有证据链,方便核对,这样大家就在同一起跑线上了。
为了让报告更有价值,我们特别强调了异常信号的挖掘。啥叫异常信号?就是那些不那么常见,但一旦出现就可能很严重的问题。比如涉及到安全或者健康的风险,或者是那种跨维度的发现,比如某个特定场景下的某类人群,在某个部件上集中吐槽,还有就是时间上的反常,比如新品刚上线,某个问题突然暴增,或者某个高价型号在性价比方面反而评价更低,这些异常信号往往藏着巨大的商业机会或风险。

每条异常信号都要有现象描述,影响对象、可能原因和验证方法,这样才能真正体现洞察力。一份合格的报告结构的完整,我们要求报告必须包含封面一页纸的高管摘要,让你快速抓住重点,然后是详细的数据说明,确保透明可追溯。主体部分要涵盖产品表现、用户反馈热点、用户痛点、使用场景与问题关联。最关键的是第五部分洞察与建议,这里会集中展示我们前面说的异常信号和具体的创新建议。
最后还有限制说明和证据链,让你了解报告的局限性和支撑结论的原始数据。这样的框架保证了报告的全面性和严谨性,光有文字还不够,数据可视化很重要。我们要求报告里至少要有6张图表,比如好评率排行榜、品牌对比雷达图、好评率变化趋势图、用户喜欢的TOP10功能、吐槽最多的TOP10问题,以及场景和问题的热力图。每张图都要有清晰的标题、数据来源说明以及一两句解读,告诉你怎么看懂这张图。写作上也要讲究,结构要清晰,叙述要有节奏感,关键是突出那些异常信号,而不是简单重复评论里出现频率高的词。提出的建议必须具体,比如针对哪个部件、哪种交互方式进行优化,并且给出简单的验证方法。

在生成最终报告之前,我们还设计了一个自检清单,让AI自己检查一下有没有漏掉什么,比如图表数量够不够,有没有找到至少3条有价值的异常信号?摘要里有没有包含关键发现和行动建议,所有的结论和图表证据是不是都能对得上?最重要的一点是不是完全基于我们上传的数据,没有掺杂任何外部信息,只有通过这些检查才能保证报告的质量。
好了,规则讲完了,现在开始实战各路AI模型。那544条评论数据生成报告结果怎么样呢?
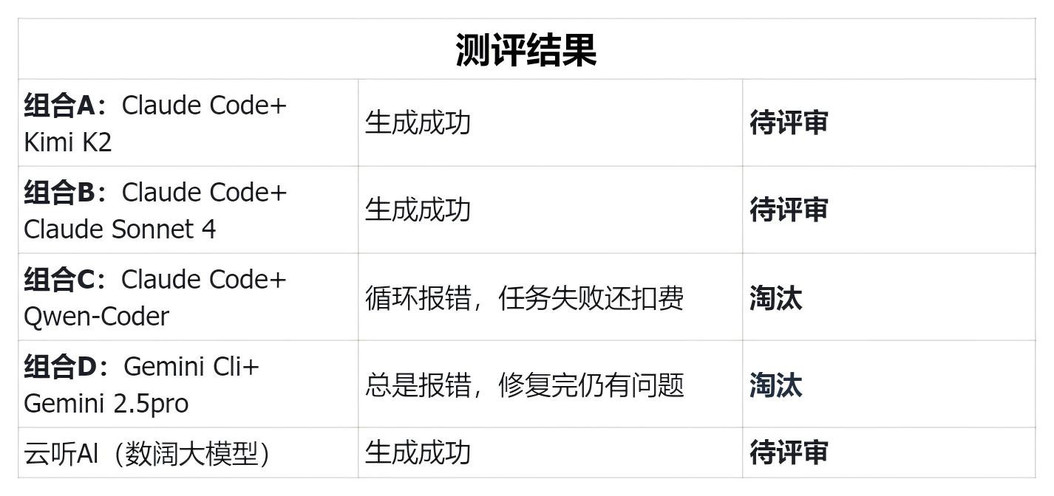
有点戏剧性,qwen3 coder,本来以为是个选手,结果直接循环报错,任务没完成不说,还倒扣了钱,真是让人哭笑不得。
还有Gemini 2.5和Gemini Cli和Qwen3 ,总是报错,修复完还是有问题。估计是压力太大,直接就放弃了提前出局。看来面对这种复杂的真实数据分析任务,不是所有模型都能hold住啊。
经过一番折腾,剩下的Claude 4、Kimi K2以及我们前面提到的云听AI 他们生成的报告整体看起来都不错。下一期我们将来进行逐项对比,看看谁将更胜一筹。
本文由 @小阔号 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务