本文第一作者王文,浙江大学博士生,研究方向是多模态理解与生成等。本文通讯作者沈春华,浙江大学求是讲席教授,主要研究课题包括具身智能、大模型推理增强、强化学习、通用感知模型等。
近年来,扩散大语言模型(Diffusion Large Language Models, dLLMs)正迅速崭露头角,成为文本生成领域的一股新势力。与传统自回归(Autoregressive, AR)模型从左到右逐字生成不同,dLLM 依托迭代去噪的生成机制,不仅能够一次性生成多个 token,还能在对话、推理、创作等任务中展现出独特的优势。当你还在等传统 LLM「一个字一个字」地憋出答案时,dLLM 早已通过几轮迭代「秒」出完整结果,带来前所未有的生成效率。
然而,速度的提升并不意味着完美的答案。现有 dLLM 的解码策略往往只关注最后一次迭代的生成结果,直接舍弃了中间多轮迭代中蕴含的丰富语义与推理信息。这些被忽视的中间预测,实际上可能暗藏着更准确、更接近真相的答案。一旦被丢弃,不仅造成信息浪费,还可能让模型错失做对题目的最佳时机。
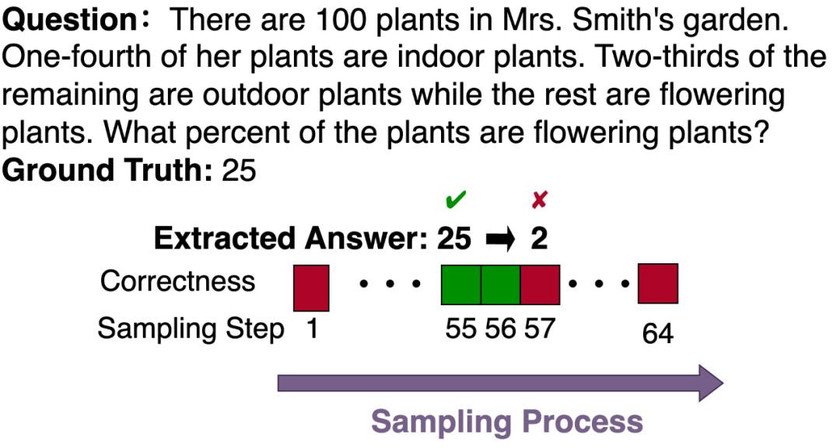
更令人意外的是,研究团队在数学推理任务中观察到了一种「先对后错」的现象:模型先是得出了正确答案,却在随后的迭代中将其「推翻」,转而采用错误答案,最终导致整体回答错误。以下图为例,模型在第 55 步时明明已经得到正确的 25,却在后续生成中改成了 2,并一直坚持到最后也未能修正。
正是基于这一关键观察,来自浙江大学的研究团队从时序视角切入,提出了 Temporal Self-Consistency Voting 与 Temporal Consistency Reinforcement 两种方法,对模型的性能进行优化与提升。

- 论文标题:Time Is a Feature: Exploiting Temporal Dynamics in Diffusion Language Models
- 论文地址:https://arxiv.org/abs/2508.09138
- 项目主页:https://aim-uofa.github.io/dLLM-MidTruth/
- Github:https://github.com/aim-uofa/dLLM-MidTruth
- Huggingface Paper:https://huggingface.co/papers/2508.09138
Temporal Self-Consistency Voting:
从时间维度「抓住」模型最靠谱的答案
在传统的自回归(AR)模型中,majority vote 通常需要针对同一个 prompt 多次生成完整回答,再根据出现频率选出最高票的答案。虽然这种方法在提升准确率方面有效,但代价是成倍增加计算开销,往往需要耗费数倍的推理时间与资源。
而研究团队结合 dLLM 的迭代生成特性,提出了 Temporal Self-Consistency Voting (TCV) 方法。它不必额外生成多条回答,而是直接利用 dLLM 在去噪过程中每个时间步的中间结果,进行一次「时间轴上的投票」来选出最终答案。考虑到 dLLM 在迭代去噪中理论上会逐渐趋于稳定与确定,TCV 还为不同时间步的结果分配了不同权重,从而更精准地捕捉最可靠的预测。
该方法的主要创新之处在于,它巧妙地将「多数投票」理念与 dLLM 的时间维度信息结合起来,实现了几乎零额外计算成本的性能提升,同时充分挖掘了中间预测中的潜在价值。
Temporal Consistency Reinforcement:
用时序一致性训练出更稳的 dLLM
研究团队针对 dLLM 的中间预测结果,创造性地提出了 Temporal Semantic Entropy (TSE) 这一概念。TSE 通过计算模型在不同迭代步骤中预测结果的语义熵,来衡量生成过程中的一致性程度。直观来说,熵越低,说明模型在迭代中越稳定、越坚定自己的选择;熵越高,则意味着生成路径摇摆不定、易于被干扰。
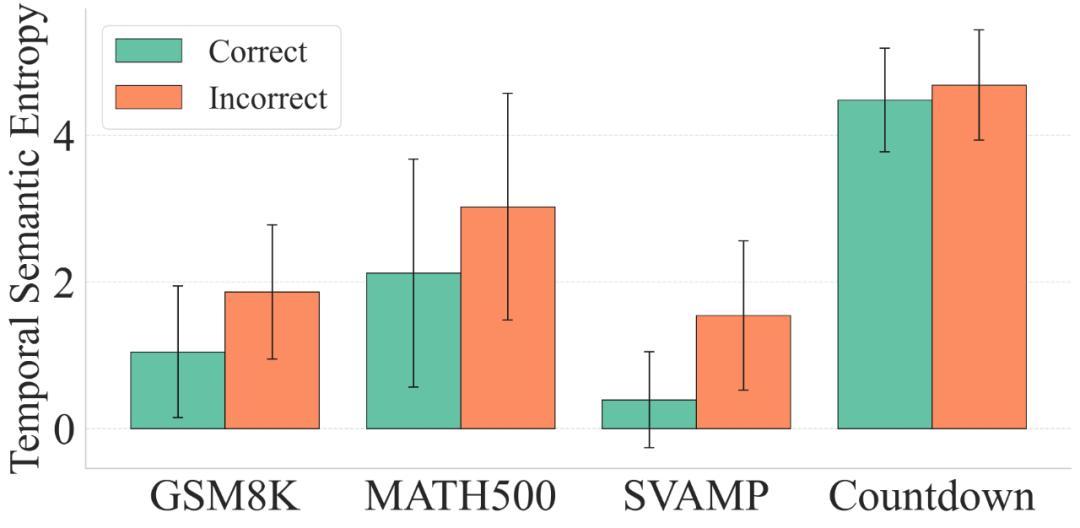
在实验分析中,他们发现了一些颇具规律性的现象:在相对简单、模型准确率较高的数据集(如 GSM8K 和 SVAMP)上,TSE 值普遍较低;而在同一个数据集中,模型答对的问题的 TSE 往往显著低于答错的问题。这一发现表明,稳定的生成路径往往与更好的任务表现高度相关。
基于这一洞察,研究团队提出了 Temporal Consistency Reinforcement (TCR) 方法,将 TSE 直接作为奖励信号,引导模型在训练中主动降低 TSE,从而提升生成路径的稳定性。进一步地,他们还利用 scoring rule,将 TSE 与传统的正确性奖励相结合,实现「双重监督」——既让模型追求正确答案,又保持推理过程的一致性,最终训练出更稳定、性能更优的 dLLM。
实验结果
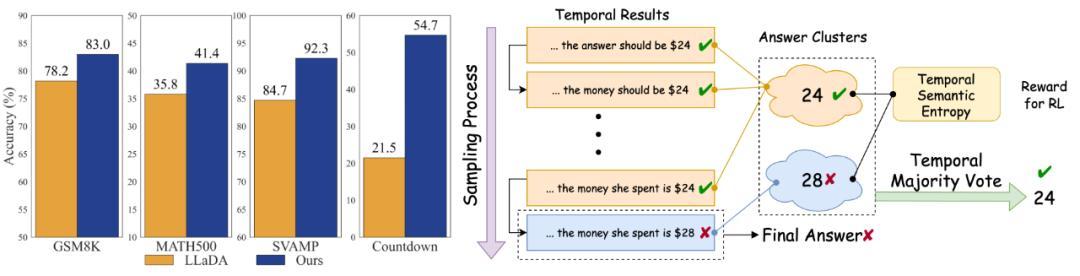
研究团队在三个主流数学推理数据集(GSM8K、MATH500、SVAMP)以及一个逻辑推理数据集(Countdown)上进行了系统测试。结果显示,Temporal Self-Consistency Voting 几乎不增加额外计算成本,就能在多个数据集上稳定带来性能提升,验证了从中间迭代中挖掘信息的有效性。
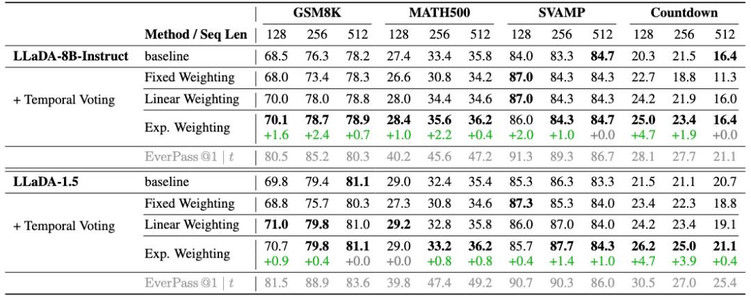
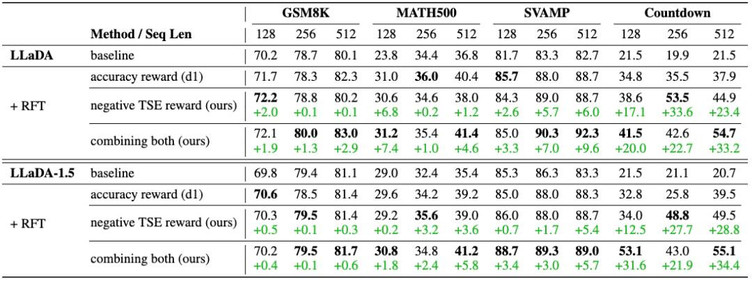
与此同时,Temporal Consistency Reinforcement 的表现同样令人惊艳——仅仅利用 Temporal Semantic Entropy (TSE) 作为唯一奖励信号,就能在 Countdown 数据集上实现 24.7% 的显著提升。更进一步,当将 TSE 与传统的正确性奖励结合时,不仅在 Countdown 上提升至 25.3%,在 GSM8K、MATH500、SVAMP 上也分别取得了 +2.0%、+4.3%、+6.6% 的绝对增幅,全面超越了仅依赖正确性奖励的效果。
训练后模型性质分析
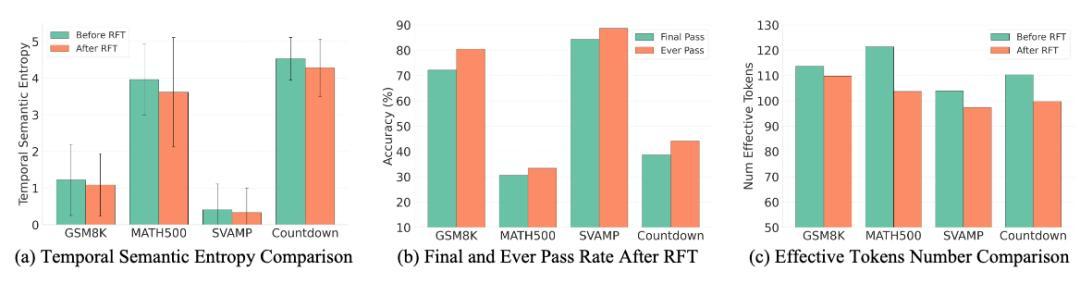
研究团队对训练后模型进行分析发现:模型生成更稳定、输出更简洁。具体表现为:
- 时间一致性提升:生成过程更稳,中间预测波动减少;
- 仍有提升空间:虽然表现更好,但模型在中间预测上仍有可优化空间;
- 输出更精炼:有效 token 数下降,答案更简短,可能也更不容易「自打脸」。
这表明,通过 Temporal Consistency Reinforcement,不仅让模型跑得快,也更能稳稳抓住正确答案。
总结
总体来看,这项工作揭示了 dLLM 生成过程中的「先对后错」现象,并提出了两种创新方法——Temporal Self-Consistency Voting 和 Temporal Consistency Reinforcement。它们利用中间预测的时间一致性和语义稳定性,不仅显著提升了模型在数学与逻辑推理任务上的表现,也为未来挖掘 dLLM 潜力提供了全新的思路。