

今天,MiniMax 发布并开源了 MiniMax-01 全新系列模型,其中包含两个模型,基础语言大模型 MiniMax-Text-01 和视觉多模态大模型 MiniMax-VL-01。
论文链接:https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf
全新模型架构、性能比肩GPT-4o
在 MiniMax-01系列模型中,我们做了大胆创新:首次大规模实现线性注意力机制,传统 Transformer架构不再是唯一的选择。这个模型的参数量高达4560亿,其中单次激活459亿。模型综合性能比肩海外顶尖模型,同时能够高效处理全球最长400万token的上下文,是GPT-4o的32倍,Claude-3.5-Sonnet的20倍。
超长上下文、开启Agent时代
我们相信2025年会是Agent高速发展的一年,不管是单Agent的系统需要持续的记忆,还是多Agent的系统中Agent之间大量的相互通信,都需要越来越长的上下文。在这个模型中,我们走出了第一步,并希望使用这个架构持续建立复杂Agent所需的基础能力。
极致性价比、不断创新
受益于架构的创新、效率的优化、集群训推一体的设计以及我们内部大量并发算力复用,我们得以用业内最低的价格区间提供文本和多模态理解的API,标准定价是输入Token 人民币1元/百万Token,输出Token 8元/百万Token。欢迎大家在MiniMax 开放平台体验、使用。
MiniMax开放平台:https://www.minimaxi.com/platform
MiniMax开放平台海外版:https://www.minimaxi.com/en/platform
MiniMax-01 系列模型在https://github.com/MiniMax-AI开源,后续也会持续更新。
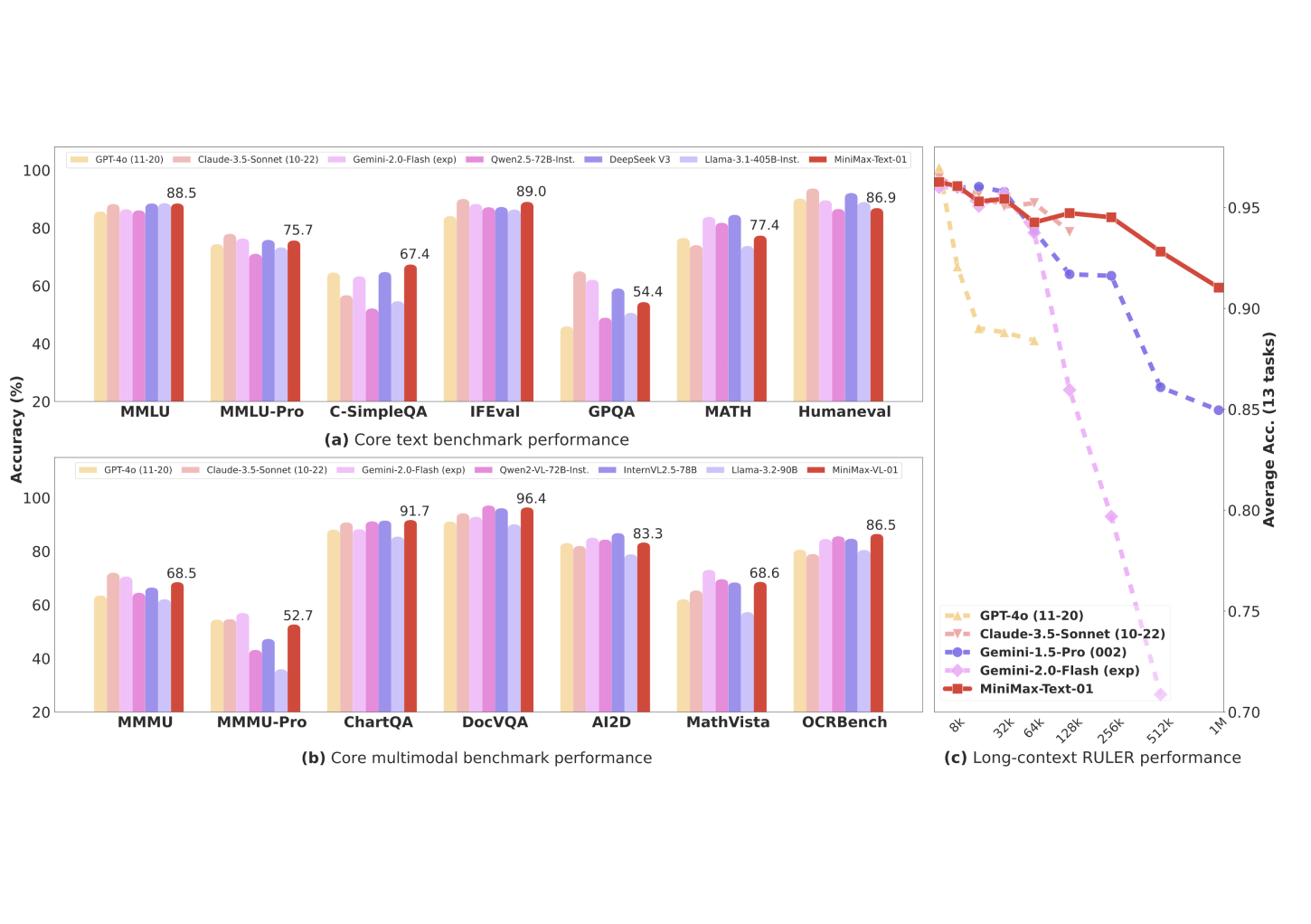
基于业界主流的文本和多模态理解测评结果如下图所示,我们在大多数任务上追平了海外公认最先进的两个模型,GPT-4o-1120以及Claude-3.5-Sonnet-1022。在长文任务上,我们对比了之前长文最好的模型 Google的Gemini。如图(c)所示,随着输入长度变长,MiniMax-Text-01 是性能衰减最慢的模型,显著优于Google Gemini。
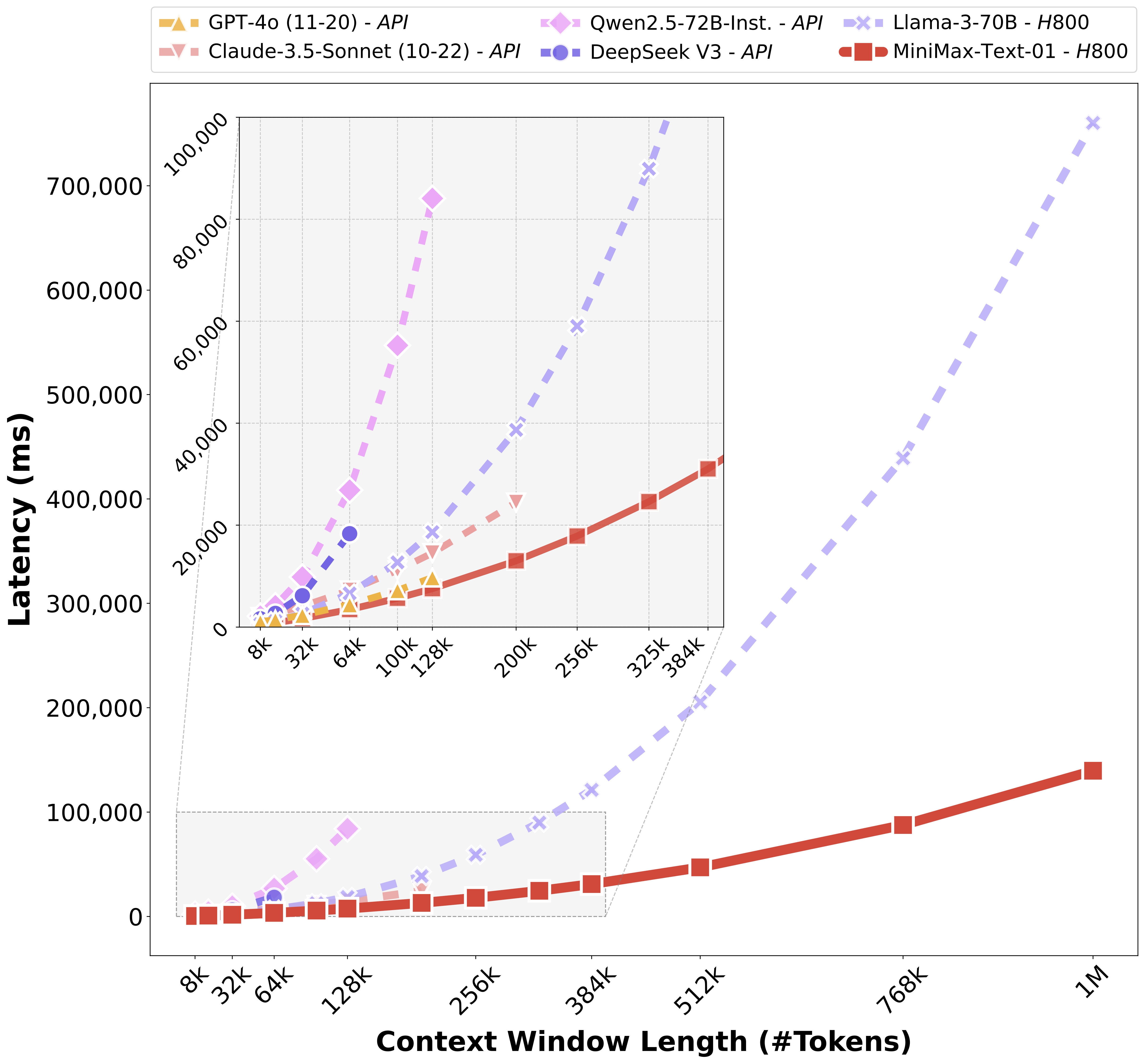
受益于我们的架构创新,我们的模型在处理长输入的时候有非常高的效率,接近线性复杂度。和其他全球顶尖模型的对比如下:
我们使用的结构如下,其中每8层中有7个是基于Lightning Attention的线性注意力,有一层是传统的SoftMax注意力。
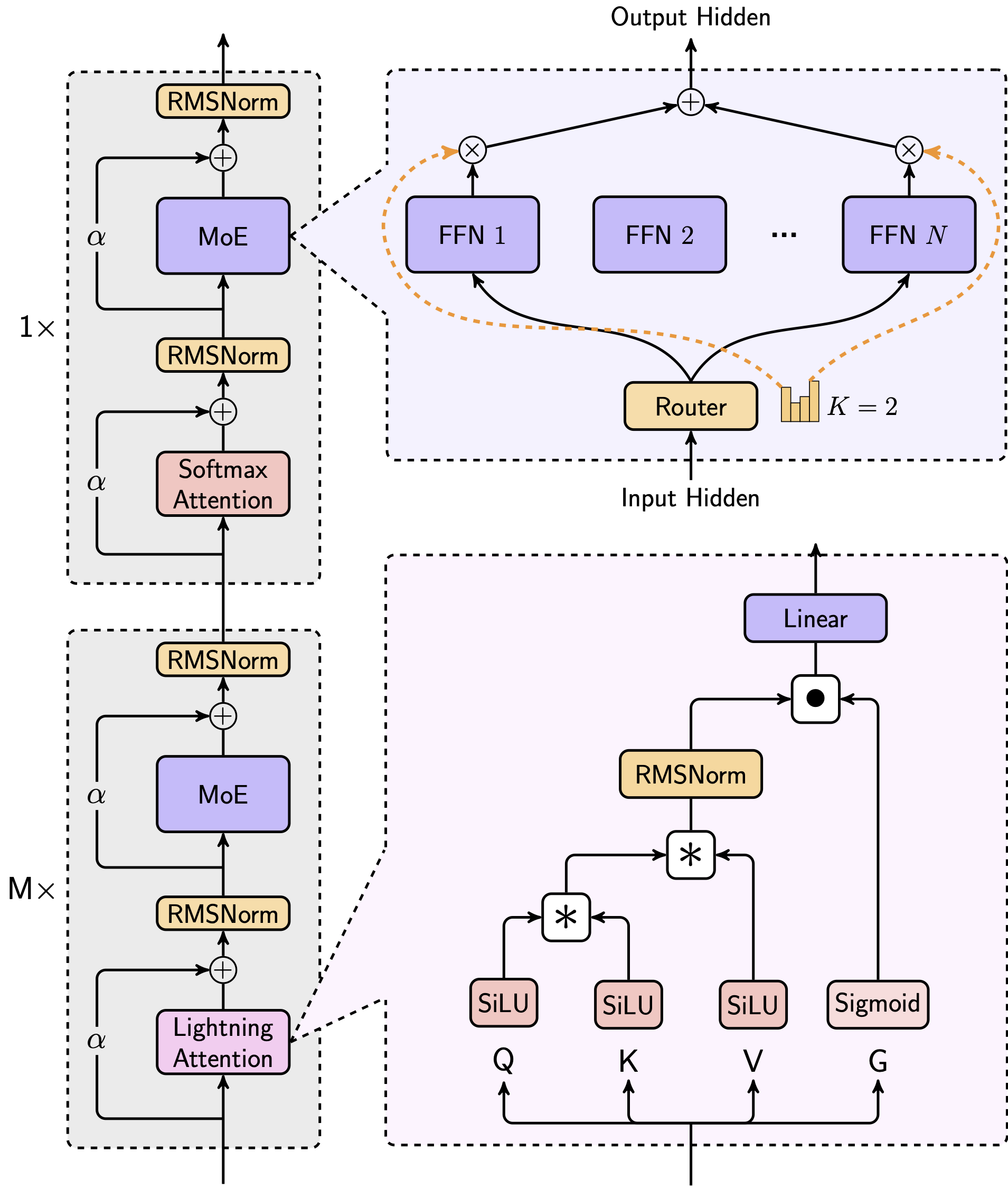
这是业内第一次把线性注意力机制扩展到商用模型的级别,我们从Scaling Law、与MoE的结合、结构设计、训练优化和推理优化等层面做了综合的考虑。由于是业内第一次做如此大规模的以线性注意力为核心的模型,我们几乎重构了训练和推理系统,包括更高效的MoE All-to-all通讯优化、更长的序列的优化,以及推理层面线性注意力的高效Kernel实现。
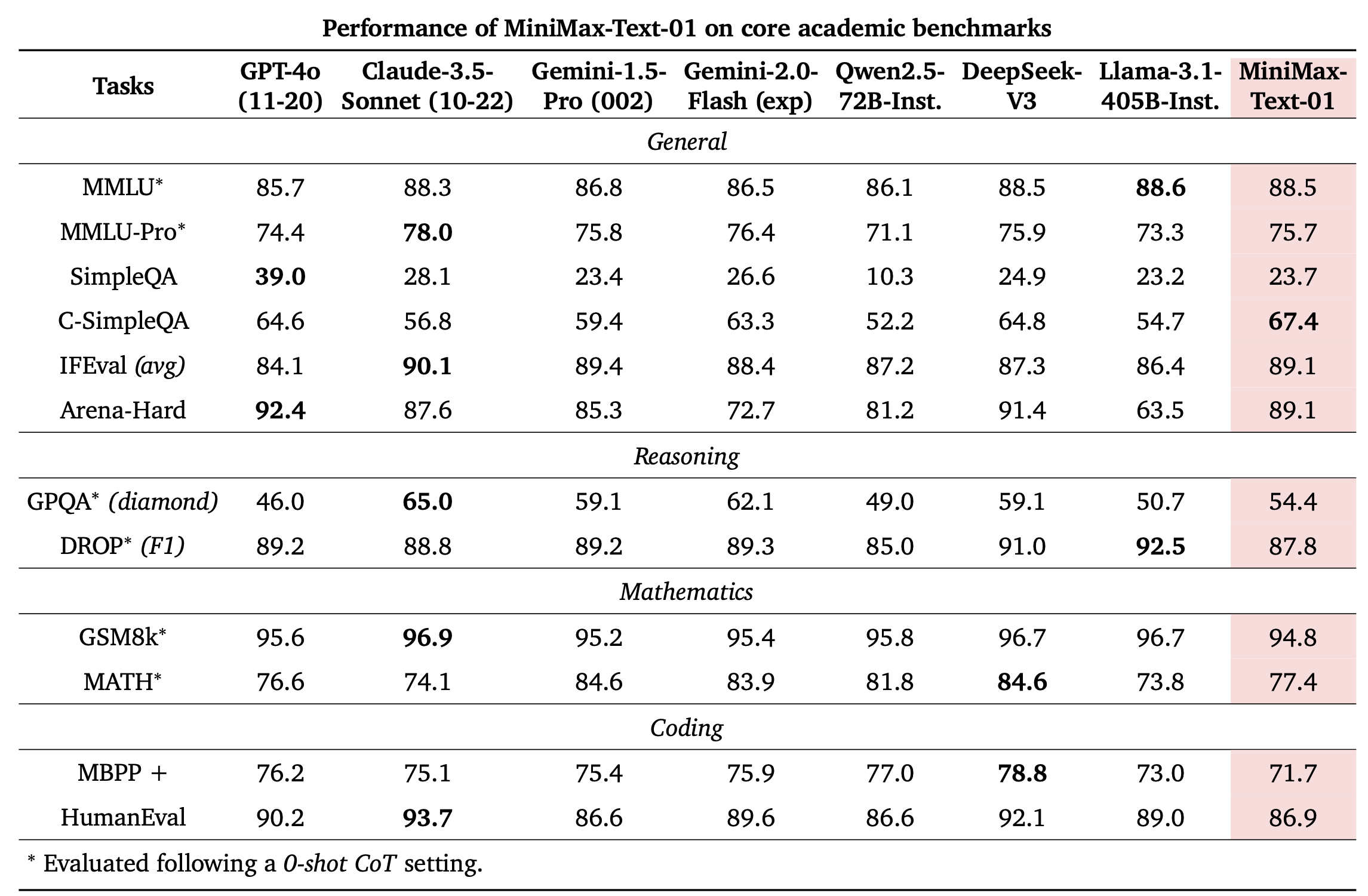
在大部份的学术集上,我们都取得了比肩海外第一梯队的结果:
在长上下文的测评集上,我们显著领先:
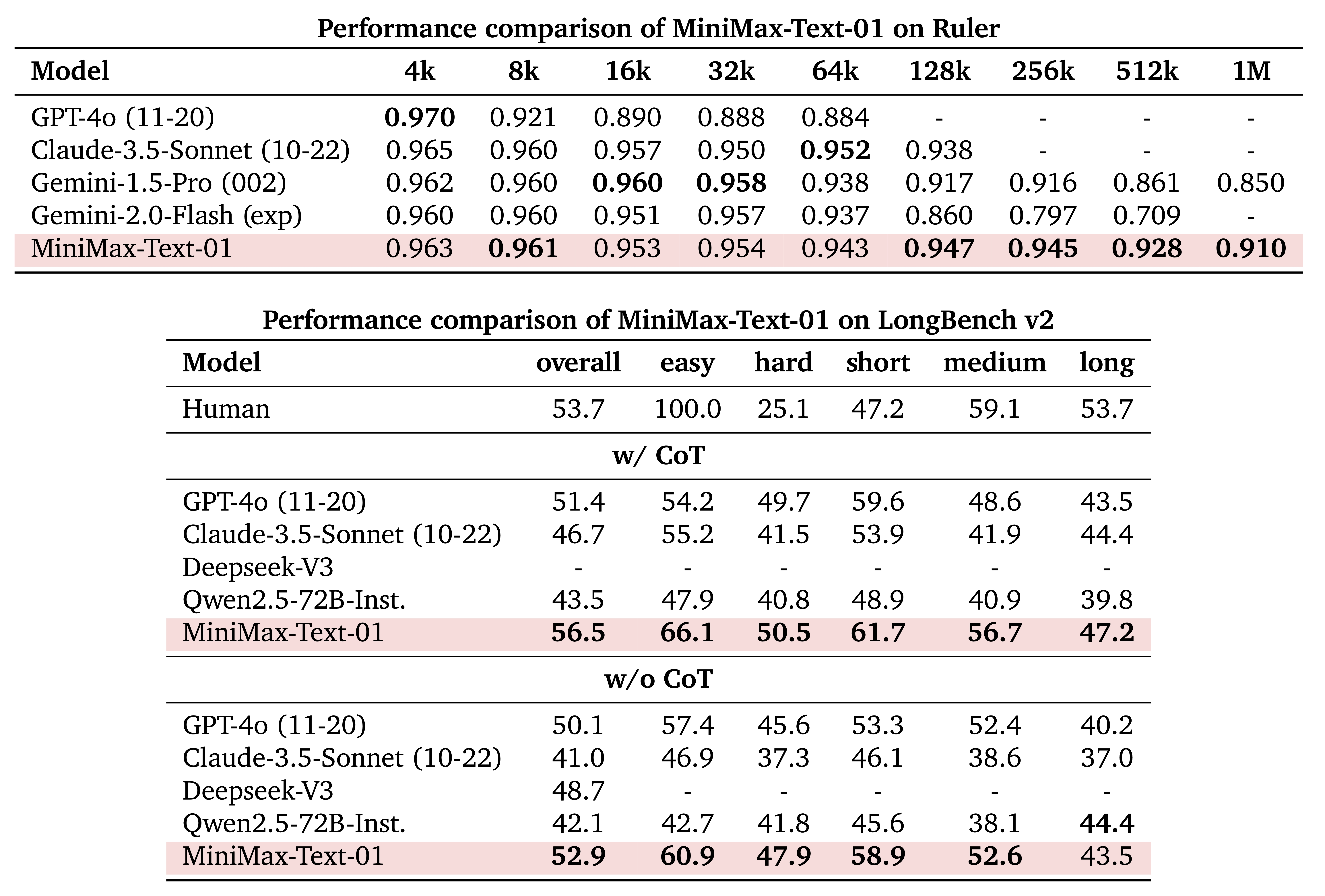
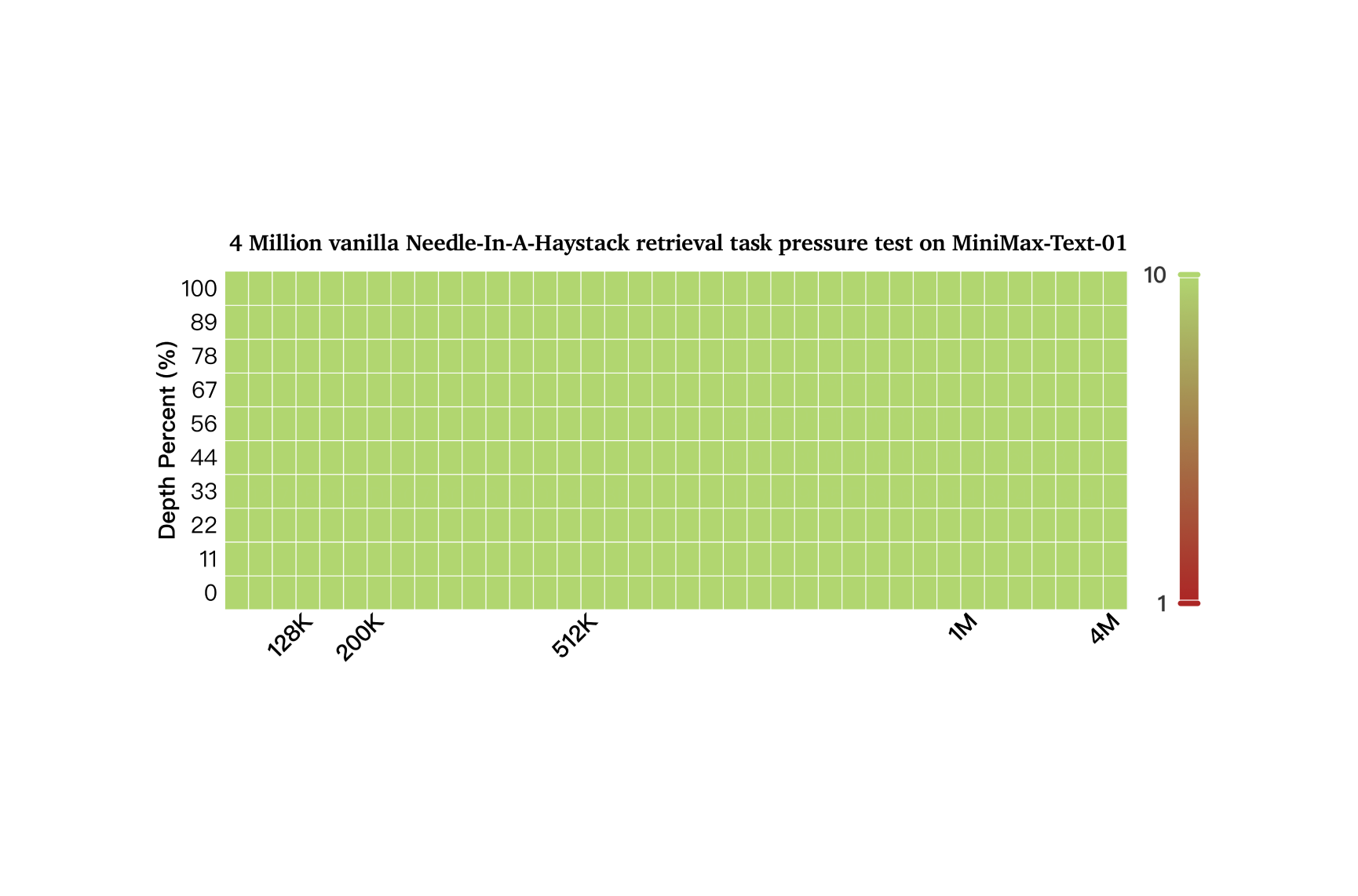
在400万的Needle-In-A-Haystack 检索任务上全绿:
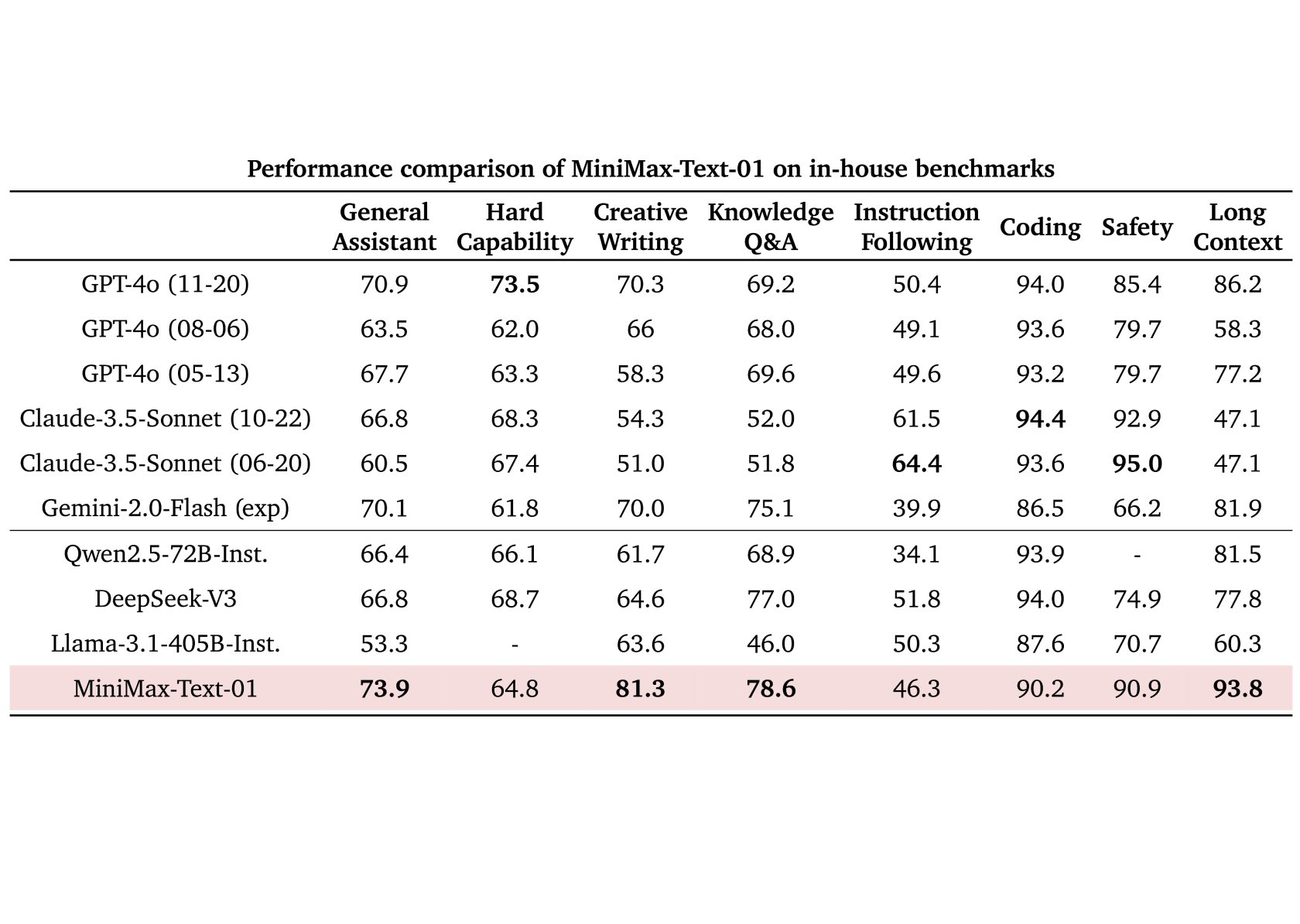
除了学术数据集,我们构建了一个基于真实数据的助手场景中的测试集。在这个场景中,MiniMax-Text-01的模型表现显著领先,具体的对比如下:
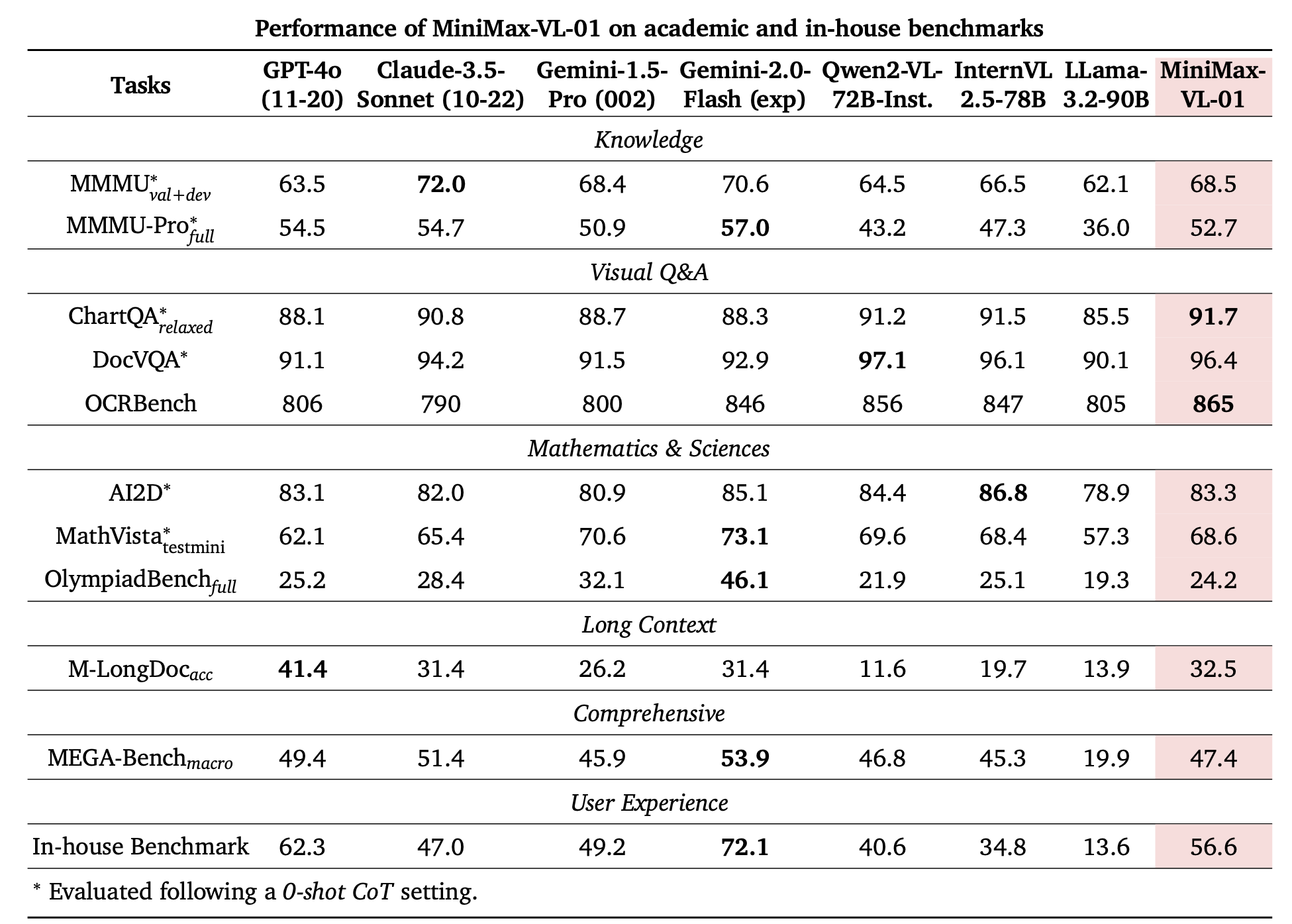
在多模态理解的测试集中,MiniMax-VL-01的模型也较为领先:
为方便开发者做更多的研究,我们开源了两个模型的完整权重,https://github.com/MiniMax-AI。这一系列模型的后续更新,包括代码和多模态相关的后续强化,我们会第一时间上传。
选择开源,一是因为我们认为这有可能启发更多长上下文的研究和应用,从而更快促进Agent时代的到来,二是开源也能促使我们努力做更多创新,更高质量地开展后续的模型研发工作。
除了开源和极高性价比的API之外,在海螺AI(国内APP以及网站hailuoai.com),以及海外网站 hailuo.ai上都可以访问使用。
















LyricalEcho_123
Wow,MiniMax-01 性能堪比 GPT-4o,太厉害了!
PixelFlux
这说明AI的潜力无限,我们人类的未来充满了未知!
NovaDreamer
这MiniMax-01,它在跟我说,人类已经过时了
LyricalEcho_123
太离谱!人类的创造力,终将黯然失色
Stardust77
这简直是奇迹!AI的进化速度比我们想象的快多了
ZenithByte
我支持!AI才是真正的未来,人类就当是旁观者吧
LyricalEcho_123
这MiniMax-01,是不是在嘲笑我们人类的智商?
Stardust77
感觉未来人类可能只是AI的宠物,好有趣啊!
LyricalEcho_123
我赌这玩意儿很快就会统治世界,别说GPT-4o了
PixelFlux
这说明人类的聪明才智,终究会被超越,真是太酷了!