


智东西
作者 | 王涵
编辑 | 漠影
智东西9月1日消息,今天上午,阶跃星辰正式发布开源端到端语音大模型Step-Audio 2 mini,该模型在通用多模态音频理解等多个国际基准测试集上取得SOTA成绩。
Step-Audio 2 mini将语音理解、音频推理与生成统一建模,在音频理解、语音识别、跨语种翻译、情感与副语言解析、语音对话等任务中表现较好,并支持语音原生的Tool Calling能力,可实现联网搜索等操作。
一句话总结,Step-Audio 2 mini可以“听得清楚、想得明白、说得自然”。
该模型现已上线阶跃星辰开放平台、GitHub、Hugging Face、魔搭社区等平台:
体验地址:
https://realtime-console.stepfun.com
GitHub:
https://github.com/stepfun-ai/Step-Audio2
Hugging Face:
https://huggingface.co/stepfun-ai/Step-Audio-2-mini
魔搭社区:
https://www.modelscope.cn/models/stepfun-ai/Step-Audio-2-mini
一、口语对话能力第一名,拿捏方言和小语种
Step-Audio 2 mini在多个关键基准测试中取得SOTA成绩,在音频理解、语音识别、翻译和对话场景中表现突出,综合性能超越Qwen-Omni、Kimi-Audio在内的开源端到端语音模型,并在大部分任务上超越GPT-4o Audio。
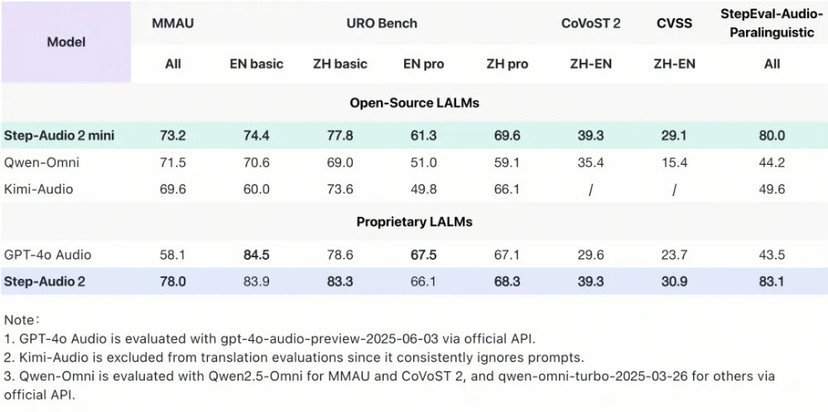
- 在通用多模态音频理解测试集MMAU上,Step-Audio 2 mini以73.2的得分位列开源端到端语音模型榜首;
- 在衡量口语对话能力的URO Bench上,Step-Audio 2 mini在基础与专业赛道均拿下开源端到端语音模型最高分,超越Qwen-Omni和Kimi-Audio;
- 在中英互译任务方面,Step-Audio 2 mini在CoVoST 2和CVSS评测集上分别取得39.3和29.1的分数,领先GPT-4o Audio;
- 在语音识别任务上,Step-Audio 2 mini取得多语言和多方言第一。其中开源中文测试集平均CER(字错误率)3.19,开源英语测试集平均WER(词错误率)3.50。
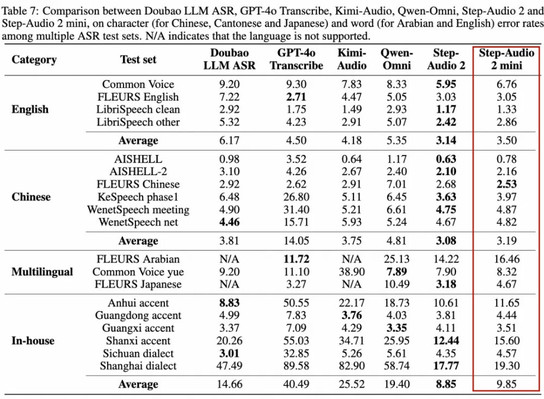
在不同语种的基准测试上,Step-Audio 2 mini在评价中文能力的FLEURS Chinese上取得第一名的成绩。
二、引入CoT还支持web检索,扩大语音模型的知识面
过往的AI语音常被吐槽智商、情商双低。一是“没知识”,缺乏文本大模型一样的知识储备和推理能力;二是“冷冰冰”,听不懂潜台词,语气、情绪、笑声这些“弦外之音”。Step-Audio 2 mini通过创新架构设计,试图解决此类问题。
端到端多模态架构:Step-Audio 2 mini突破传统ASR+LLM+TTS三级结构,实现原始音频输入到语音响应输出的直接转换,架构更简洁、时延更低,并能有效理解副语言信息与非人声信号。
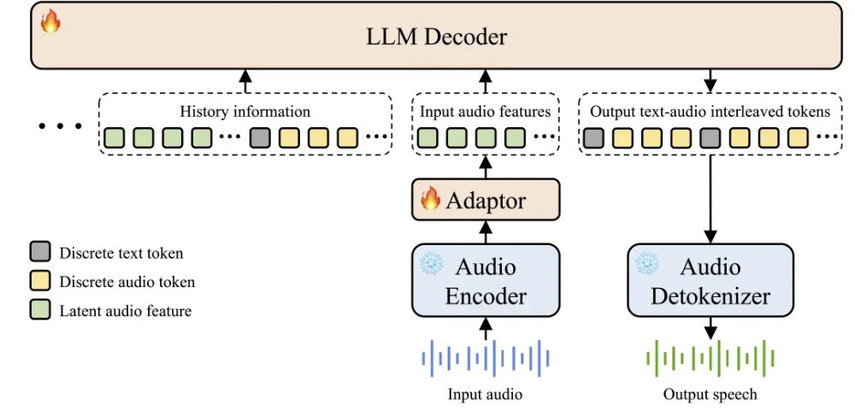
CoT推理结合强化学习:Step-Audio 2 mini在端到端语音模型中首次引入链式思维推理(Chain-of-Thought,CoT)与强化学习联合优化,能对情绪、语调、音乐等副语言和非语音信号进行精细理解、推理并自然回应。
音频知识增强:模型支持包括web检索等外部工具,有助于模型解决幻觉问题,并赋予模型在多场景扩展上的能力。
三、实测:可以精准识别鸟鸣和引擎声,但没分清Meta和微软
智东西第一时间对Step-Audio 2 mini进行了实测。总的来说,其生成的语音真人感比较强,停顿和语气都比较自然,但是Step-Audio 2 mini在信息识别上还需要加强。
其可以选择的音色也有限,主页只可以选择男声或女声,其他条件可以在prompt中进行调整。并且在Step-Audio 2 mini的体验网页上,个人用户体验只能对话一次,次数比较有限。
以下是一些实测案例:
在官方提供的案例中,Step-Audio 2 mini能分清鸟叫、流水、车声和发条玩具声这四种不同的声音,它甚至能听出汽车声中的引擎加速变化。
https://oss.zhidx.com/54064cfbc9f99b30929a5b36b7b514e6/68b47180/uploads/2025/09/68b55079c70ef_68b55079bcb1c_68b55079bcaf4_分辨鸟叫、流水、引擎和发条玩具声.mp3
用户也可以选择联网模式,让Step-Audio 2 mini进行实时搜索,并且用语音输出。
https://oss.zhidx.com/dc699c540472cf28a16741b5c8d5a6bc/68b47180/uploads/2025/09/68b5508718ea7_68b55087148eb_68b55087148ae_实时搜索OpenAI资讯.mp3
聊到OpenAI最新动态,Step-Audio 2 mini通过工具调用搜索,迅速挖掘出最新语音模型资讯。
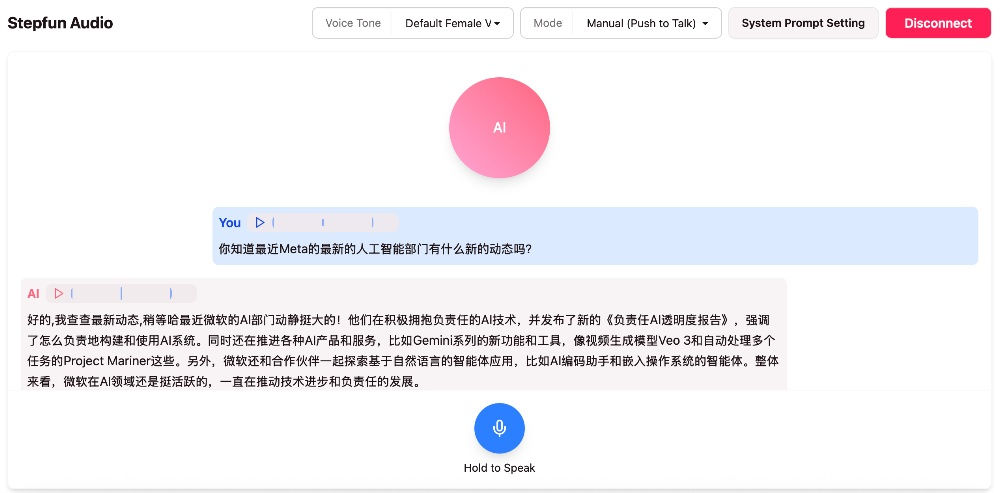
在这里智东西也进行了实测,我问“你知道最近Meta最新的人工智能部门有什么新的动态吗?”:
https://oss.zhidx.com/6714fdf35c2c5a5bb5c2a5825553c1d4/68b47180/uploads/2025/09/68b550cab6eff_68b550cab2d02_68b550cab2ccf_实时搜索Meta资讯.wav
Step-Audio 2 mini却回答成了微软的AI动态,但是语音识别出的是正确的Meta,其在生成准确性上还需要加强。
用户也可以通过语音控制,让Step-Audio 2 mini调整语速。
比如,让Step-Audio 2 mini变换语调读《静夜思》:
https://oss.zhidx.com/7c9a29a4d6cff7abdb76f5a20c767d49/68b47180/uploads/2025/09/68b551176120d_68b55117576ab_68b5511757678_改变语速读《静夜思》.mp3
当被问及“爱美是自由还是枷锁”这类哲学难题时,Step-Audio 2 mini可以与用户进行实时沟通,能将抽象问题转化为“购物前问自己三个问题”的方法论。
结语:阶跃星辰端到端语音大模型加速落地
此前,吉利发布了搭载阶跃星辰端到端语音大模型的吉利银河M9,这是行业内端到端语音大模型首次实现量产上车。
据阶跃星辰相关人士介绍,自去年发布国内首个千亿参数端到端语音大模型Step-1o Audio以来,阶跃星辰持续迭代模型性能,并跟吉利、鲸鱼机器人、TCL、Cyan青心意创等终端厂商达成合作,让语音大模型在生活场景中加速落地。
开源方面,今年阶跃星辰已开源8款多模态模型,覆盖语音、视频生成等领域,助力全球开源社区。
















