

机器之心报道
机器之心编辑部
开源赛道也是热闹了起来。
就在深夜,字节跳动 Seed 团队正式发布并开源了 Seed-OSS 系列模型,包含三个版本:
- Seed-OSS-36B-Base(含合成数据)
- Seed-OSS-36B-Base(不含合成数据)
- Seed-OSS-36B-Instruct(指令微调版)
- Hugging Face 地址:https://huggingface.co/ByteDance-Seed/Seed-OSS-36B-Instruct
- 项目地址:https://github.com/ByteDance-Seed/seed-oss
Seed-OSS 使用了 12 万亿(12T)tokens 进行训练,并在多个主流开源基准测试中取得了出色的表现。
这三个模型均以 Apache-2.0 许可证发布,允许研究人员和企业开发者自由使用、修改和再分发。
主要特性:
- 灵活的推理预算控制:允许用户根据需要灵活调整推理长度。这种对推理长度的动态控制能力,可在实际应用场景中提升推理效率。
- 增强的推理能力:在保持平衡且优秀的通用能力的同时,针对推理任务进行了特别优化。
- 智能体能力:在涉及工具使用和问题解决等智能体任务中表现突出。
- 研究友好:考虑到在预训练中加入合成指令数据可能会影响后续研究,字节同时发布了含有与不含指令数据的预训练模型,为研究社区提供了更多样化的选择。
- 原生长上下文:在训练中原生支持最长 512K 的上下文窗口。
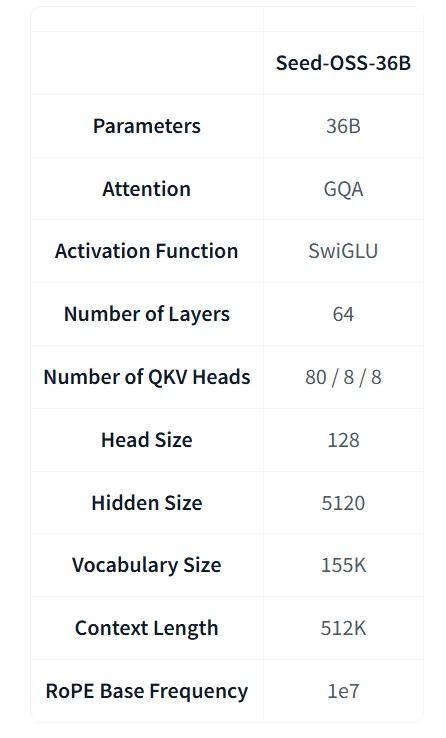
模型架构
Seed-OSS-36B 的架构结合了多种常见的设计选择,包括因果语言建模、分组查询注意力(Grouped Query Attention)、SwiGLU 激活函数、RMSNorm 和 RoPE 位置编码。
每个模型包含 360 亿参数,分布在 64 层网络中,并支持 15.5 万词表。
其最具代表性的特性之一是原生长上下文能力,最大上下文长度可达 512k tokens,能够在不损失性能的情况下处理超长文档和推理链。
这一长度是 OpenAI 最新 GPT-5 模型系列的两倍,大约相当于 1600 页文本。
另一个显著的特性是引入了推理预算,它允许开发者在模型给出答案之前,指定模型应执行多少推理过程。
这一设计在近期其他一些开源模型中也有所体现,例如 Nvidia 新推出的 Nemotron-Nano-9B-v2。
在实际应用中,这意味着团队可以根据任务的复杂性和部署的效率需求来调节性能。
推荐的预算值为 512 tokens 的倍数,其中 0 表示直接输出答案的模式。
结果
基准测试结果显示,Seed-OSS-36B 位列当前性能较强的开源大模型之列。
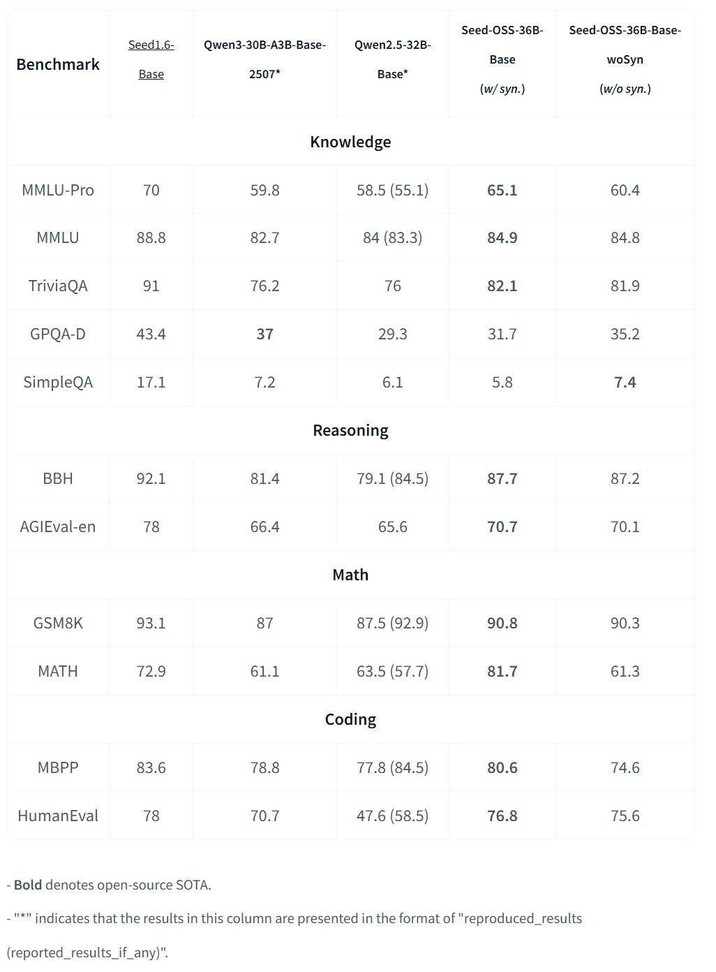
Seed-OSS-36B-Base
含合成数据版本的 Base 模型在 MMLU-Pro 上取得 65.1 得分,在 MATH 上取得 81.7 得分。非合成基础版本虽然在许多方面略微落后,但也具有竞争力。
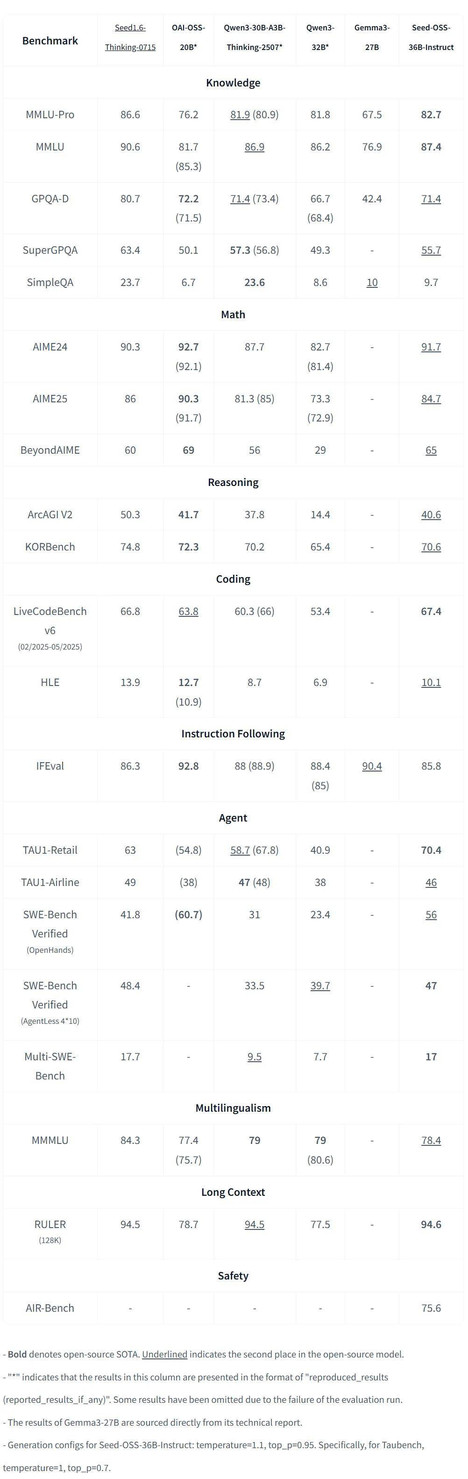
Seed-OSS-36B-Instruct
Instruct 版本在多个领域都取得了 SOTA 成绩。
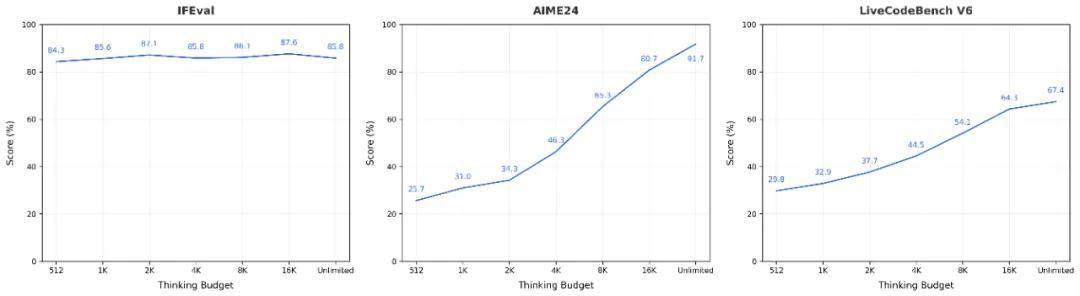
- 数学与推理:Seed-OSS-36B-Instruct 在 AIME24 上取得 91.7% 的成绩,在 BeyondAIME 上取得 65,均代表开源领域的最新 SOTA 水平。
- 代码能力:在 LiveCodeBench v6 上,Instruct 模型得分 67.4,同样刷新 SOTA 纪录。
- 长上下文处理:在 RULER(128K 上下文长度)测试中,该模型达到 94.6,创下开源模型的最高分。
思考预算
用户可以灵活指定模型的推理预算。下图展示了在不同任务中,随着推理预算变化而产生的性能曲线。
对于较简单的任务(如 IFEval),模型的思维链较短,随着推理预算的增加,分数会出现一定波动。
而在更具挑战性的任务(如 AIME 和 LiveCodeBench)中,模型的思维链较长,分数则会随着推理预算的增加而提升。
模型在运行过程,会提醒用户 token 使用情况:
Got it, let"s try to solve this problem step by step. The problem says ... ...
Using the power rule, ... ...
Alternatively, remember that ... ...
Because if ... ...
To solve the problem, we start by using the properties of logarithms to simplify the given equations: (full answer omitted).
如果未设置推理预算(默认模式),Seed-OSS 将以无限长度启动推理。
如果指定了推理预算,字节建议用户优先选择 512 的整数倍数(如 512、1K、2K、4K、8K 或 16K),因为模型已在这些区间上进行了大量训练。
当推理预算为 0 时,模型会被指示直接输出答案;对于低于 512 的预算,字节也建议统一设为 0。















