
混元团队近期开源了一款创新性高效图像生成项目:MixGRPO!

该框架通过结合随机微分方程(SDE)和常微分方程(ODE)的混合采样策略,显著提升了文本到图像(Text-to-Image, T2I)任务的效率和性能。
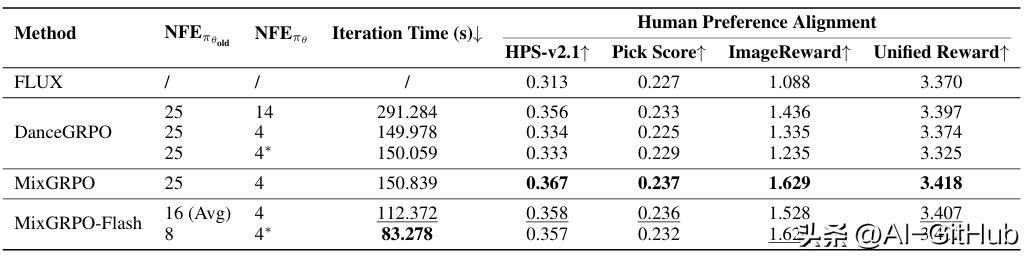
使其在人类偏好对齐的多个维度上均表现出显著提升,效果和效率均优于DanceGRPO,训练时间降低近50%。
核心创新
MixGRPO的核心在于其混合采样机制。传统方法如Flow-GRPO和DanceGRPO依赖SDE采样引入随机性,但需在整个去噪步骤中进行优化,导致训练速度缓慢。

MixGRPO创新性地将采样过程划分为两个区间:在特定时间窗口内使用SDE采样以保留探索性,窗口外则采用ODE采样以提高确定性。
这不仅简化了马尔可夫决策过程(MDP)的优化流程,还大幅降低了计算开销。
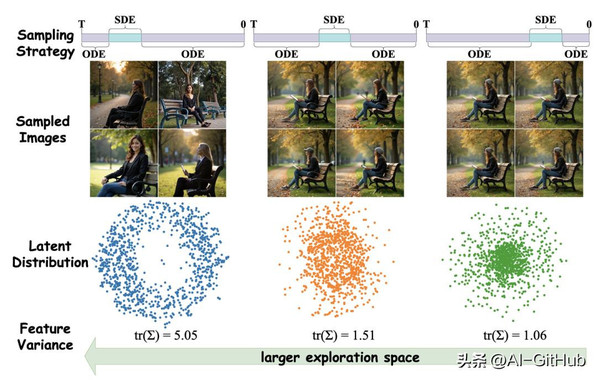
性能对比
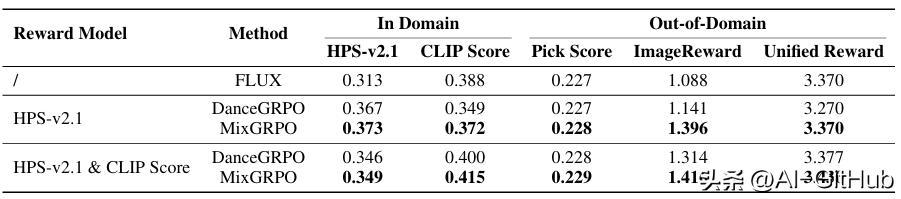
无论是单奖励还是多奖励,MixGRPO 在域内和域外奖励指标上均取得了最佳性能。
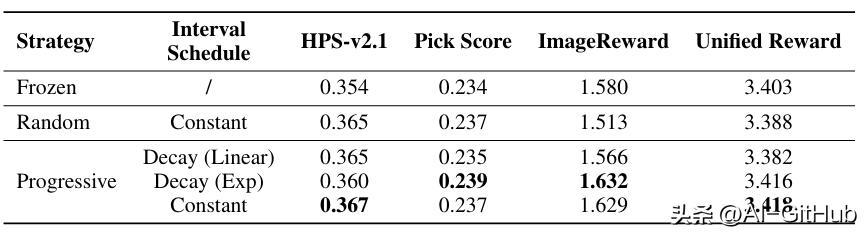
在progressive策略下,MixGRPO指数衰减和恒定调度均为最优选择。
HPS-v2.1 作为奖励模型下 FLUX、DanceGRPO 和 MixGRPO 的可视化结果对比。

在 HPS-v2.1 和 CLIP Score 作为奖励模型下,FLUX、DanceGRPO 和 MixGRPO 的可视化结果对比。

定性比较:MixGRPO 在语义和美学方面都取得了卓越的性能。

此外,团队还提出了MixGRPO-Flash变体,通过引入高阶ODE求解器(如DPM-Solver++)进一步加速采样过程。MixGRPO-Flash在保持相近性能的同时,将训练时间额外降低了71%。这得益于ODE部分的加速优化,例如使用二阶中点法减少采样步数,实现了计算开销与性能的平衡。
开源意义
目前,团队已发布基于 FLUX.1 Dev 架构、采用 MixGRPO 训练的模型版本,支持以下特性:
多重奖励模型联合训练(HPSv2、ImageReward、Pick Score);
兼容主流扩散采样流程;
支持 ODE/SDE 模式切换,便于推理阶段灵活配置。
该模型可用于高质量图文生成、AIGC 内容审核优化、个性化创作辅助等场景。
GitHub:https://github.com/Tencent-Hunyuan/MixGRPO
















