

随着 OpenAI 加入 Anthropic 支持模型上下文协议 (MCP),我们见证了语言模型与外部系统交互的统一标准。这为多 LLM 架构创造了令人兴奋的机会,其中专门的 AI 应用程序并行工作 — 通过标准化接口发现工具、移交任务和访问强大的功能。
什么是 MCP,为什么它很重要?¶
MCP 是由 Anthropic 开发的开放协议,用于标准化 AI 模型和应用程序与外部工具、数据源和系统的交互方式。它通过提供标准化接口层解决了团队为 AI 集成构建自定义实施的碎片化问题。
MCP 生态系统有三个组成部分:
- 主机:希望通过 MCP 客户端访问数据的 Claude Desktop 等程序、IDE 或 AI 工具
- 客户端:与服务器保持 1:1 连接的协议客户端
- 服务器:轻量级程序,每个程序都通过标准化的 Model Context Protocol 公开特定功能
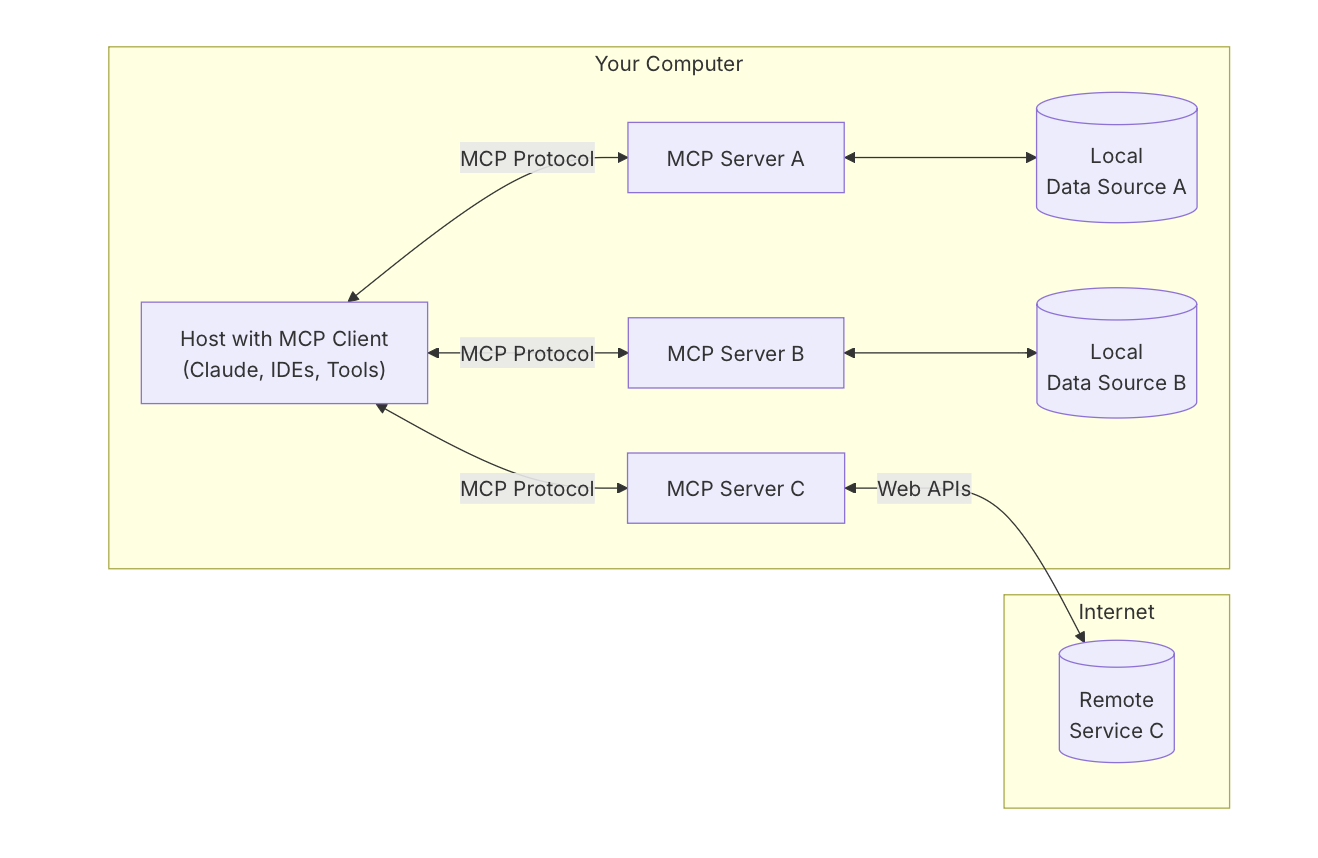
在与 Client 交互时,Host 可以访问两个主要选项:Tools(工具),它们是检索或修改数据的模型控制功能,以及 Resources(资源),它们是应用程序控制的数据,如文件。
最终还打算允许服务器本身能够在通过采样端点执行其任务时向 Client 端和 Host 请求完成/批准。
MCP 解决的集成问题¶
在 MCP 之前,将 AI 应用程序与外部工具和系统集成会产生所谓的“M×N 问题”。如果您有 M 个不同的 AI 应用程序(Claude、ChatGPT、自定义代理等)和 N 个不同的工具/系统(GitHub、Slack、Asana、数据库等),则需要构建 M×N 不同的集成。这会导致团队之间的重复工作、不一致的实施以及呈二次方增长的维护负担。
MCP 将其转化为“M+N 问题”。工具创建者构建 N 个 MCP 服务器(每个系统一个),而应用程序开发人员构建 M MCP 客户端(每个 AI 应用程序一个)。整个集成工作变为 M+N,而不是 M×N。
这意味着团队可以构建一次 GitHub MCP 服务器,并且它将与任何兼容 MCP 的客户端一起使用。同样,一旦您构建了与 MCP 兼容的代理,它就可以立即与所有现有的 MCP 服务器一起使用,而无需额外的集成工作。
市场信号:越来越多的采用¶
自推出以来,MCP 的采用曲线一直非常陡峭。在短短几个月内,出现了近 3000 个社区构建的 MCP 服务器,这表明开发人员对该标准表现出浓厚的兴趣。Zed、Cursor、Perser 和 Windsurf 等主要平台已成为 MCP 主机,将协议集成到其核心产品中。包括 Cloudflare 在内的公司已经发布了官方 MCP 支持,其中包含 OAuth 等功能,供开发人员开始构建出色的应用程序。
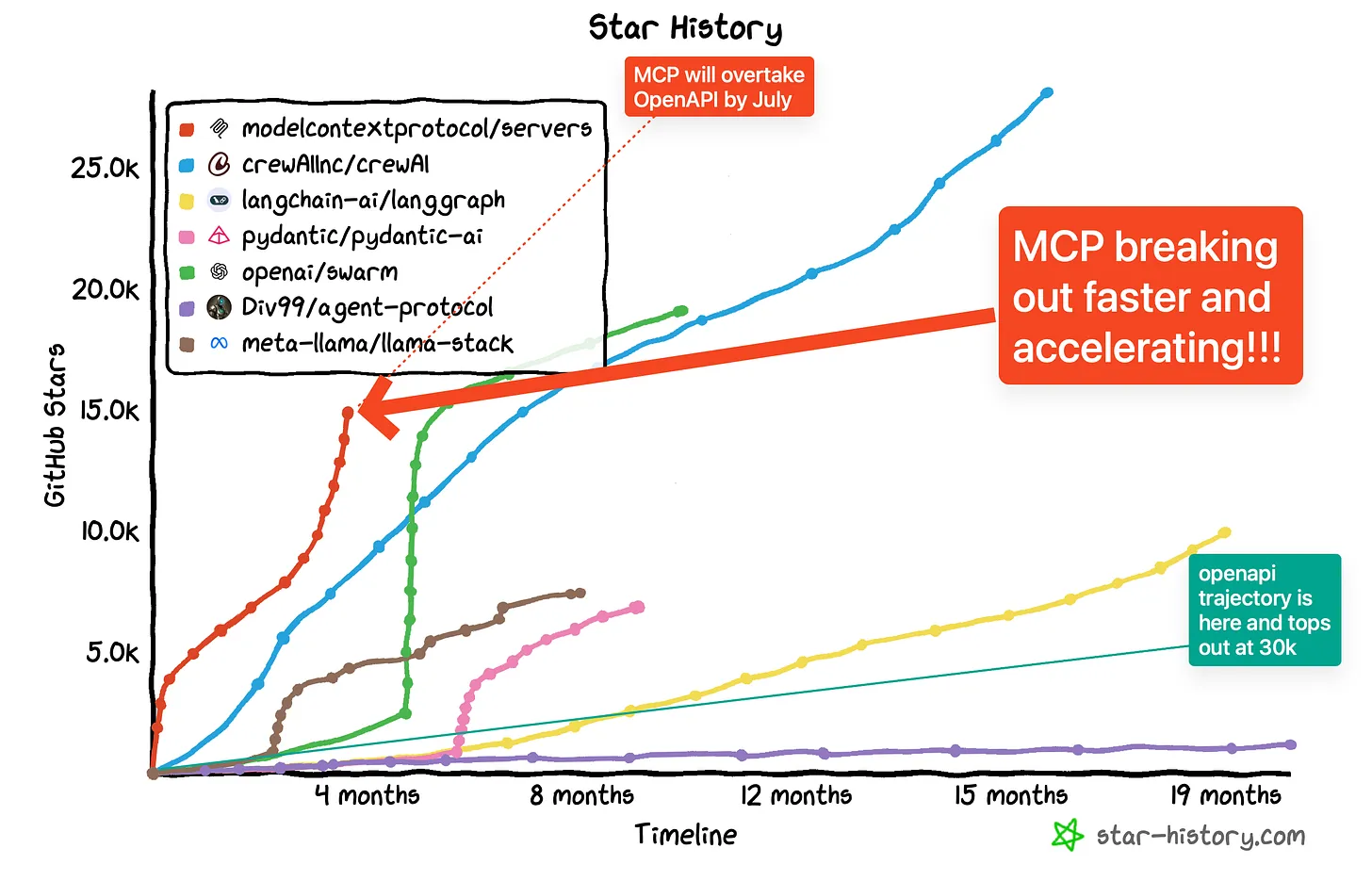
由于 OpenAI 和 Anthropic 都支持 MCP,我们现在拥有了涵盖两个最先进的 AI 模型提供商的统一方法。这一临界质量表明 MCP 有望成为 AI 工具集成的主导标准。
MCP 与 OpenAPI 规范¶
虽然 MCP 和 OpenAPI 都是 API 接口的标准,但它们具有不同的用途和方法。以下是主要差异的简化比较:
| 方面 | OpenAPI 规范 | 模型上下文协议 (MCP) |
|---|---|---|
| 主要用户 | 与 Web API 交互的人类开发人员 | AI 模型和代理发现和使用工具 |
| 建筑 | 单个 JSON/YAML 文件中的集中规范 | 具有主机、客户端和服务器的分布式系统,允许动态发现 |
| 使用案例 | 记录供人类使用的 RESTful 服务 | 使 AI 模型能够自主查找和使用具有语义理解的工具 |
这两个标准在现代技术生态系统中起到了互补的作用。OpenAPI 擅长为人类开发人员记录传统的 Web 服务,而 MCP 则专为新兴的 AI 代理环境而构建,提供丰富的语义上下文,使工具可被语言模型发现和使用。
大多数组织可能会同时维护两者:用于其面向开发人员的服务的 OpenAPI 规范和支持 AI 的应用程序的 MCP 接口,从而根据需要在这些领域之间架起桥梁。
MCP 开发入门¶
MCP 的学习曲线相对平缓 — 许多服务器的代码不到 200 行,可以在一小时内构建完成。以下是在现有环境中开始使用 MCP 的几种方法:
Claude 桌面¶
Claude Desktop 现在支持 MCP 集成,允许 Claude 通过工具访问最新信息。您可以通过转到 Claude 的 Settings 并编辑配置来添加这些 MCP。
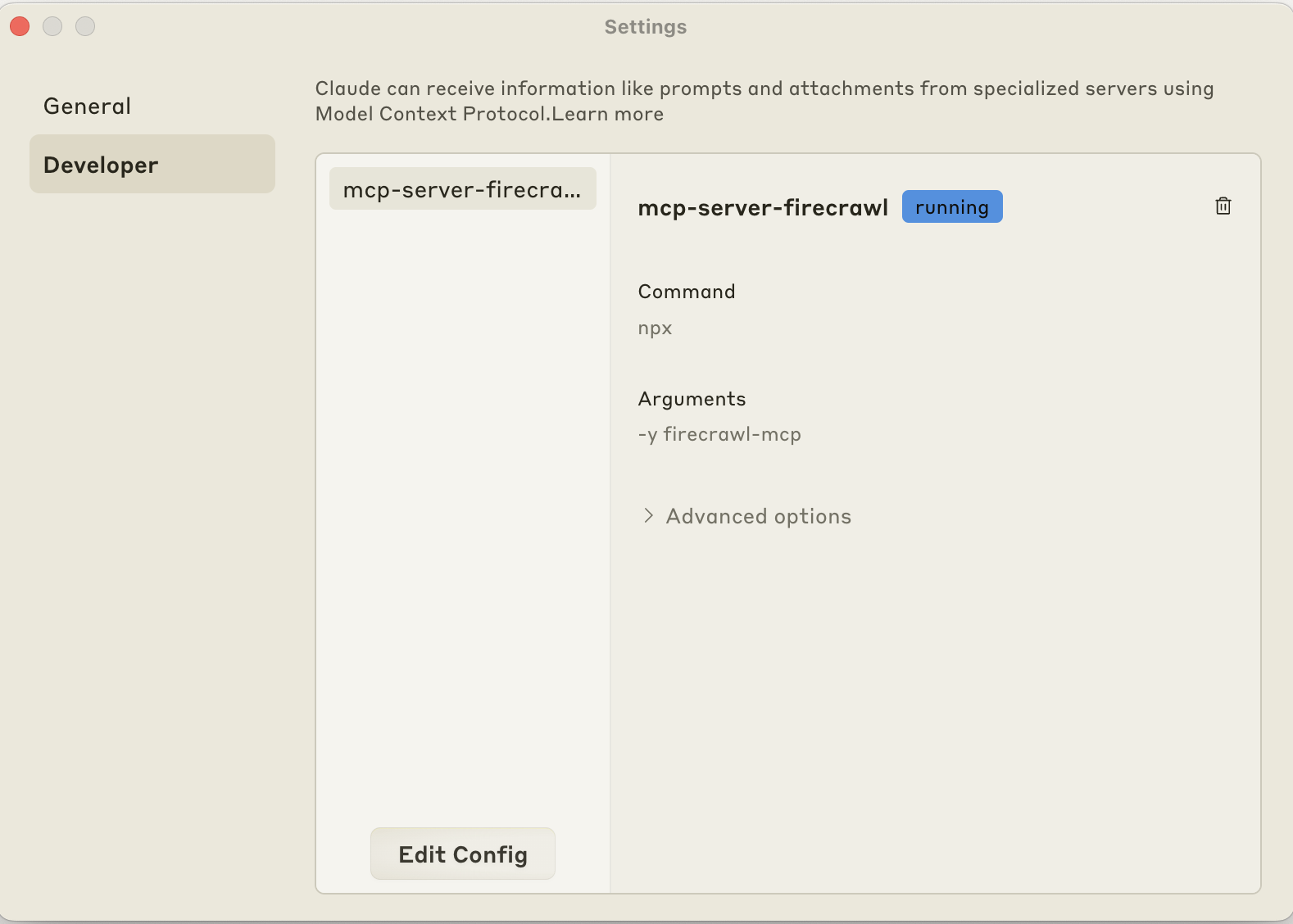
例如,您可以使用以下配置安装 Firecrawl 的 MCP:
{"mcpServers":{"mcp-server-firecrawl":{"command":"npx","args":["-y","firecrawl-mcp"],"env":{"FIRECRAWL_API_KEY":"YOUR_API_KEY_HERE"}}}}这允许 Claude 抓取网站并获取最新信息:
游标集成¶
Cursor 通过一个简单的配置文件为 MCP 提供支持。使用所需的 MCP 服务器创建文件:.cursor/mcp.json
{"mcpServers":{"github":{"command":"npx","args":["-y","@modelcontextprotocol/server-github"],"env":{"GITHUB_PERSONAL_ACCESS_TOKEN":"<Personal Access Token Goes Here>"}}}}在 Cursor Settings 中启用 MCP 选项:
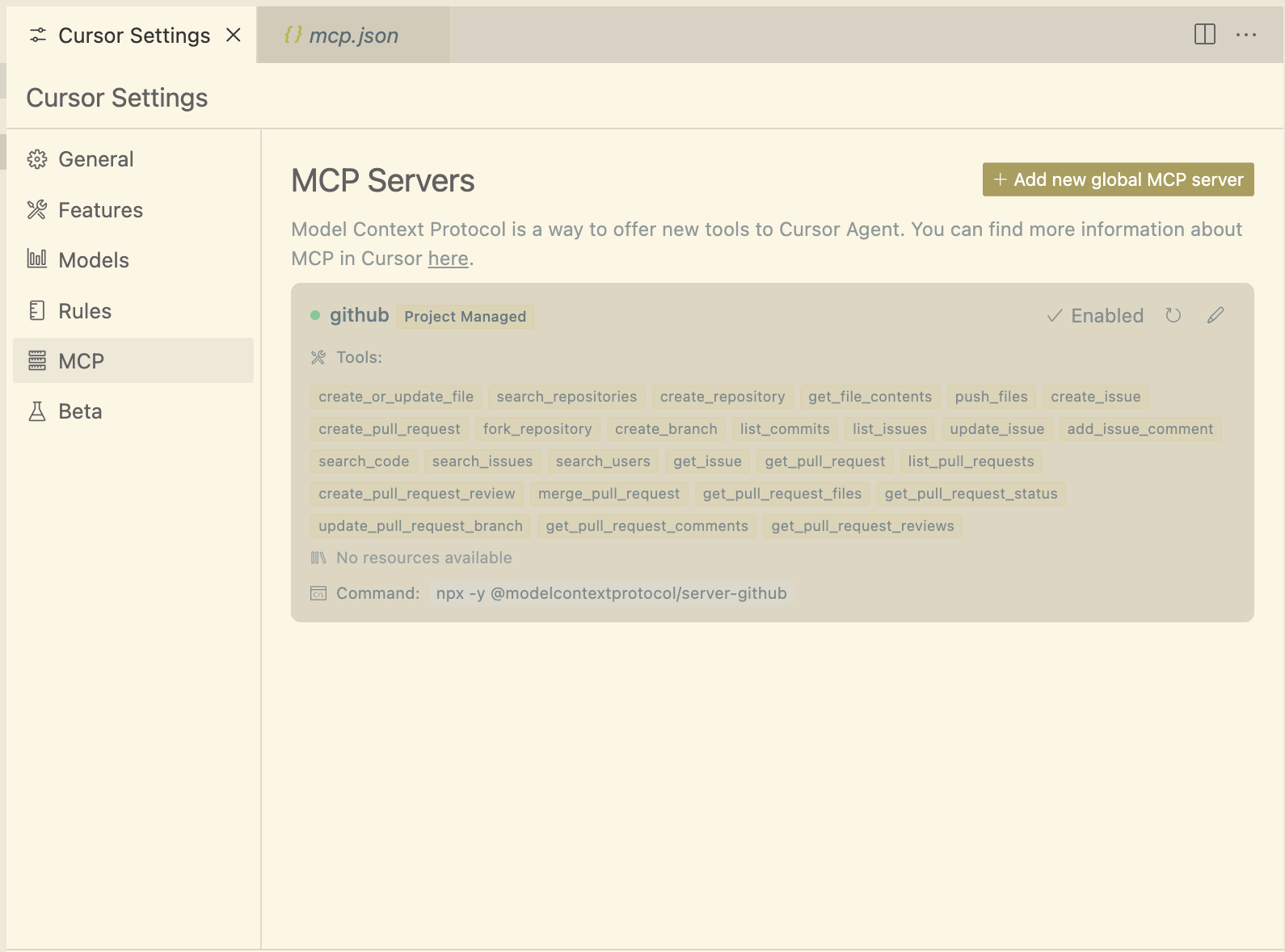
然后将 Cursor 的 Agent 与您的 MCP 服务器一起使用:
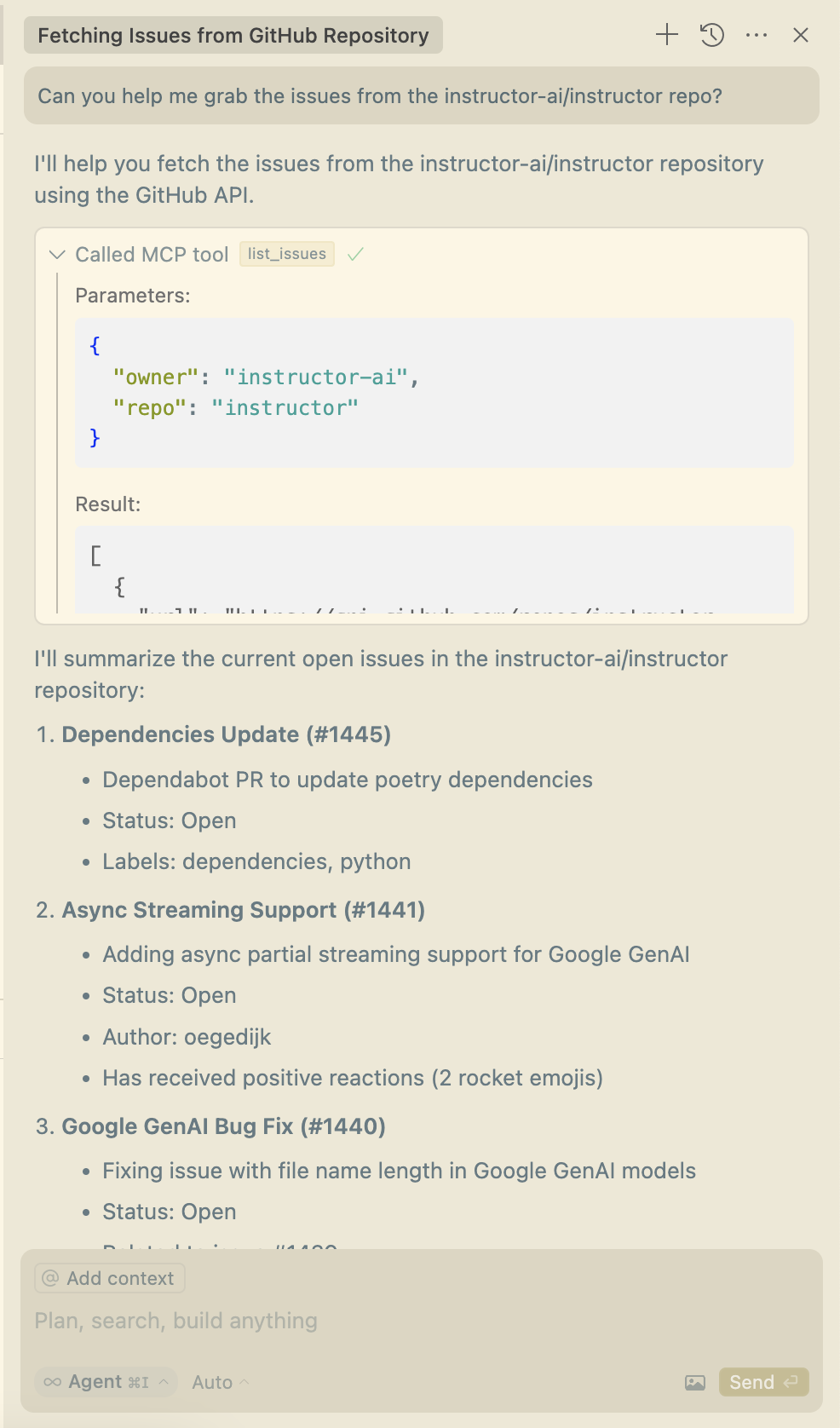
在上面的示例中,我提供了一个简单的 github MCP,用于询问有关存储库中问题的一些问题。但是你真的可以做更多的事情,例如,你可以提供一个 MCP 来允许你的模型与 Web 浏览器交互,例如,查看你的前端代码在渲染时的外观以自动修复它。instructor-aipuppeteer
OpenAI 代理 SDK¶
OpenAI 的代理 SDK 现在支持使用该类的 MCP 服务器,允许您将代理连接到本地工具和资源:MCPServer
importasyncioimportshutil fromagentsimportAgent,Runner,tracefromagents.mcpimportMCPServer,MCPServerStdio asyncdefrun(mcp_server:MCPServer,directory_path:str): agent=Agent( name="Assistant", instructions=f"Answer questions about the git repository at{directory_path}, use that for repo_path", mcp_servers=[mcp_server], ) question=input("Enter a question: ") print("\n"+"-"*40) print(f"Running:{question}") result=awaitRunner.run(starting_agent=agent,input=question) print(result.final_output) message="Summarize the last change in the repository." print("\n"+"-"*40) print(f"Running:{message}") result=awaitRunner.run(starting_agent=agent,input=message) print(result.final_output) asyncdefmain(): # Ask the user for the directory path directory_path=input("Please enter the path to the git repository: ") asyncwithMCPServerStdio( cache_tools_list=True,# Cache the tools list, for demonstration params={"command":"uvx","args":["mcp-server-git"]}, )asserver: withtrace(workflow_name="MCP Git Example"): awaitrun(server,directory_path) if__name__=="__main__": ifnotshutil.which("uvx"): raiseRuntimeError( "uvx is not installed. Please install it with `pip install uvx`." ) asyncio.run(main())这允许代理了解本地 git 存储库:
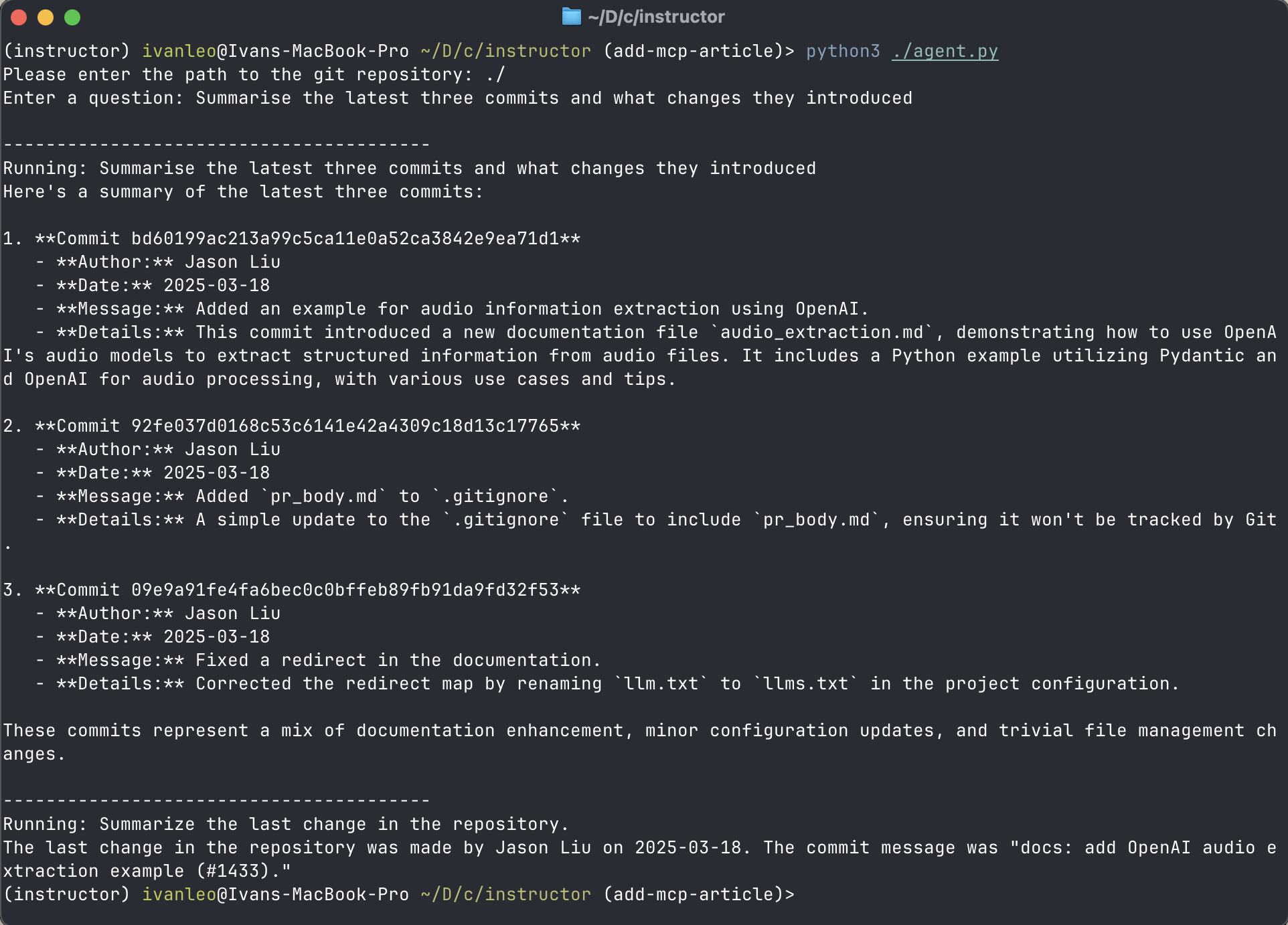
结论¶
对于开发人员和组织来说,问题不在于是否应该为 MCP 构建,而在于何时构建。随着生态系统的成熟,早期采用者在将 AI 功能集成到其现有系统和工作流程方面将具有显着优势。对于 Anthropic 即将推出的 MCP 注册表、对远程 MCP 服务器托管的传入支持以及 OAuth 集成尤其如此,这将有助于构建更丰富、更个性化的集成。
MCP 提供的标准化可能会推动下一波 AI 集成,从而可以构建复杂的多智能体系统,通过统一接口利用不同提供商的最佳功能。















