
编辑:桃子
【新智元导读】继提示工程之后,「上下文工程」又红了!这一概念深得Karpathy等硅谷大佬的喜欢,堪称「全新的氛围编程」。而智能体成败的关键,不在于精湛的代码,而是上下文工程。
硅谷如今炙手可热的,不再是提示词工程,而是上下文工程(Context Engineering)!
就连AI大神Karpathy,都为「上下文工程」投下了一票。

还有Shopify CEO Tobias Lütke称,自己更喜欢「上下文工程」,因其准确描述了一个核心技能——
通过为任务提供完整的背景信息,让大模型能够合理解决问题的艺术。

一夜之间,「上下文工程」红遍全网,究竟是为什么?


上下文工程,一夜爆红
这背后原因,离不开AI智能体的兴起。
OpenAI总裁Greg Brockman多次公开表示,「2025年,是AI智能体的元年」。

决定智能体成功或失败最关键的因素,是提供的「上下文质量」。也就是说,加载到「有限工作记忆」中的信息愈加重要。
大多数AI智能体失败的案例,不是模型的失败,而是上下文的失败!
那么,什么是上下文?
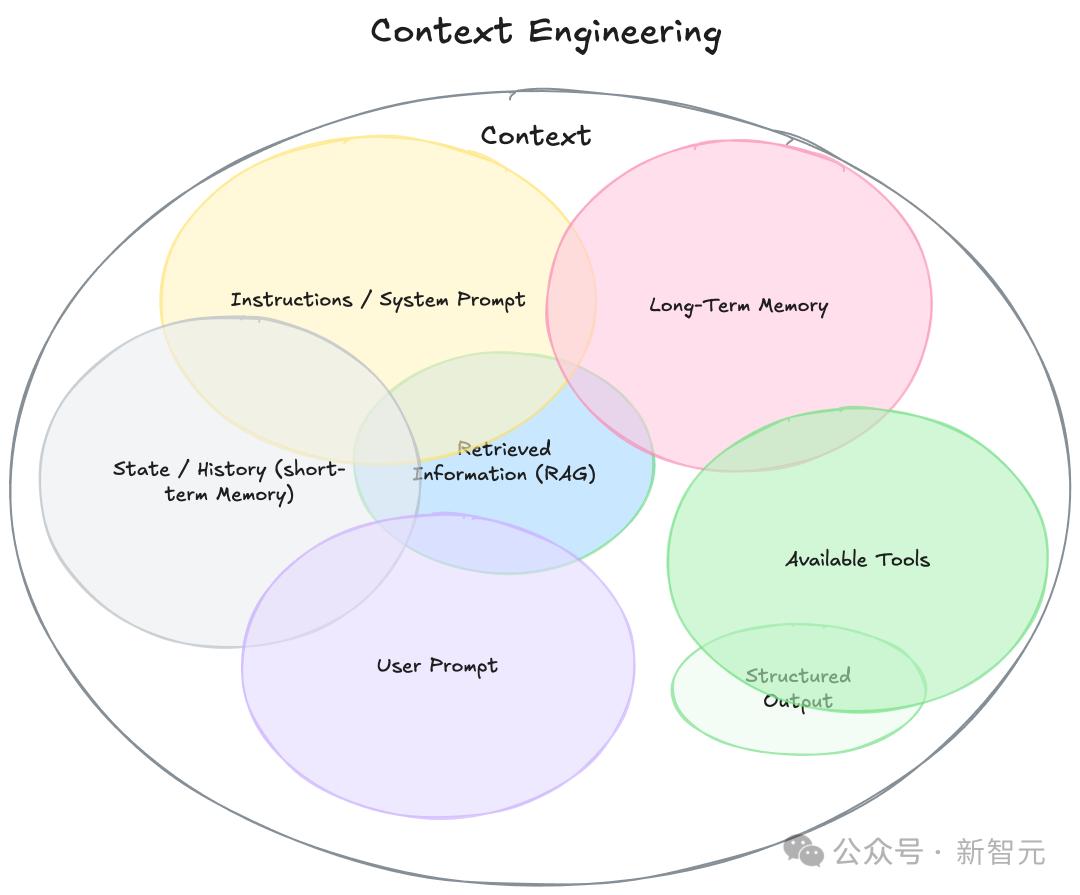
要理解「上下文工程」,首先需要扩展「上下文」的定义。
它不仅仅是你发送给LLM的单一提示,可以将其视为「模型再生成响应之前,看到的所有内容」,如下:
- 指令/系统提示:定义模型在对话中行为的初始指令集,可以/应该包括示例、规则等。
- 用户提示:用户的即时任务或问题。
- 状态/历史(短期记忆):当前对话,包括用户和模型的响应,截至此刻。
- 长期记忆:跨多次之前对话收集的持久知识库,包含学习到的用户偏好、过去项目的摘要或要求记住以备将来使用的事实。
- 检索信息(RAG):外部、实时的知识,来自文档、数据库或API的相关信息,用于回答特定问题。
- 可用工具:模型可以调用的所有功能或内置工具的定义,比如check_inventory、send_email。
- 结构化输出:模型响应格式的定义,例如JSON对象。
可以看出,与专注于在单一本文字符串中,精心构建完美指令的「提示词工程」不同,「上下文工程」的范畴要广泛得多。

简单来说:
「上下文工程」是一门学科,它致力于设计和构建动态系统。
这些系统能够在恰当的时机、以恰当的格式,提供恰当的信息和工具,从而让LLM拥有完成任务所需的一切。
以下是「上下文工程」的所有特点
· 它是一个系统,而非一个字符串:上下文并非一个静态的提示词模板,而是一个系统的输出,这个系统在对LLM进行主调用之前就已经运行。
· 它是动态的:上下文是即时生成的,为当前任务量身定制。比如,某个请求可能需要的是日历数据,而另一个请求则可能需要电子邮件内容或网络搜索结果。
· 它强调在恰当时机提供恰当信息与工具:其核心任务是确保模型不会遗漏关键细节(谨记「垃圾进,垃圾出」原则)。这意味着只在必要且有益的情况下,才向模型提供知识(信息)和能力(工具)。
· 它注重格式:信息的呈现方式至关重要。一份简洁的摘要远胜于原始数据的罗列;一个清晰的工具接口定义也远比一条模糊的指令有效。


是一门科学,也是一门艺术
Karpathy长文点评中,同样认为「上下文工程」是艺术的一种。
人们往往将提示词(prompt),联想为日常使用中——发给LLM的简短任务描述。
然而,在任何一个工业级的 LLM 应用中,上下文工程都是一门精深的科学,也是一门巧妙的艺术。
其核心在于,为下一步操作,用恰到好处的信息精准填充上下文窗口。

说它是科学,是因为要做好这一点,需要综合运用一系列技术,其中包括:
任务描述与解释、少样本学习示例、RAG(检索增强生成)、相关的(可能是多模态的)数据、工具、状态与历史记录、信息压缩等等。
信息太少或格式错误,LLM就没有足够的上下文来达到最佳性能;
信息太多或关联性不强,又会导致LLM的成本上升、性能下降。
要做好这一点是颇为复杂的。
说它是艺术,则是因为其中需要依赖开发者对大模型「脾性」的直觉把握和引导。
除了上下文工程本身,一个LLM应用还必须做到:
- 将问题恰到好处地拆解成控制流
- 精准地填充上下文窗口
- 将调用请求分派给类型和能力都合适的LLM
- 处理「生成-验证」的UIUX流程
- 以及更多——例如安全护栏、系统安全、效果评估、并行处理、数据预取等等…
因此,「上下文工程」只是一个正在兴起的、厚重且复杂的软件层中的一小部分。
这个软件层负责将单个的LLM调用,以及更多其他操作整合协调,从而构建出完整的LLM应用。
Karpathy表示,把这类应用轻率地称为「ChatGPT的套壳」,这种说法不仅老掉牙了,而且大错特错。
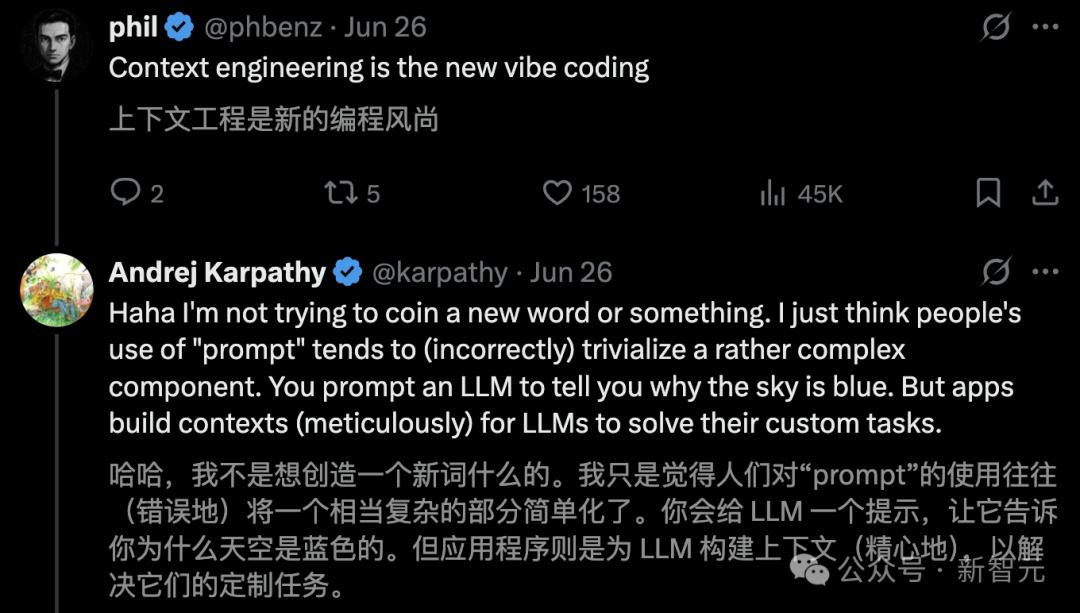
有网友对此调侃道,上下文工程,是全新的「氛围编程」。
Karpathy回应称,「我倒不是想自创个新词什么的。我只是觉得,大家一提到「提示词」,就容易把一个其实相当复杂的组件给想简单了」。
你会用一个提示词去问LLM「天空为什么是蓝色的」。但应用程序呢,则是需要为大模型构建上下文,才能解决那些为它量身定制的任务。
智能体成败,全靠它了
其实,打造真正高效的AI智能体秘诀,关键不在于编写的代码有多复杂,而在于你所提供的上下文有多优质。
一个效果粗糙的演示产品,同一个表现惊艳的智能体,其根本区别就在于提供的上下文质量。
想象一下,一个AI助理需要根据一封简单的邮件来安排会议:
嘿,想问下你明天有空简单碰个头吗?
「粗糙的演示」智能体获得的上下文很贫乏。它只能看到用户的请求,别的什么都不知道。
它的代码可能功能齐全——调用一个LLM并获得响应,但输出的结果却毫无帮助,而且非常机械化:
感谢您的消息。我明天可以。请问您想约在什么时间?
接下来,再看看由丰富的上下文加持的惊艳智能体。
其代码的主要任务并非是思考如何回复,而是去收集LLM达成目标所需的信息。在调用LLM之前,你会将上下文扩展,使其包含:
代码的主要工作,不是决定如何响应,而是收集LLM完成目标所需的信息。
在调用LLM之前,你会扩展上下文,包括:
日历信息:显示你全天都排满了
与此人的过去邮件:用来判断应该使用何种非正式语气
联系人列表:用来识别出对方是一位重要合作伙伴
用于send_invite或send_email的工具
然后,你就可以生成这样的回复:
嘿,Jim!我明天日程完全排满了,会议一个接一个。周四上午我有空,你看方便吗?邀请已经发给你了,看这个时间行不行哈。
这种惊艳的效果,其奥秘不在于模型更智能,或算法更高明,而在于为正确的任务提供了正确的上下文。
这正是「上下文工程」将变得至关重要的原因。
所以说,智能体的失败,不只是模型的失败,更是上下文的失败。
要构建强大而可靠的 AI 智能体,我们正逐渐摆脱对寻找「万能提示词」,或依赖模型更新的路径。
这一点,深得网友的认同。

其核心在于对上下文的工程化构建:即在恰当的时机、以恰当的格式,提供恰当的信息和工具。
这是一项跨职能的挑战,它要求我们深入理解业务用例、明确定义输出,并精心组织所有必要信息,从而使LLM能够真正「完成任务」。
最后,借用网友一句话,「记忆」才是AGI拼图的最后一块。

参考资料:
https://www.philschmid.de/context-engineering
https://news.ycombinator.com/item?id=44427757

















Zenith_X
“上下文工程太厉害了,感觉提示工程有点被它超越了!”
Zenith_X
这提醒我们,未来的世界,语言的价值会发生怎样的变化?
PixelBloom
感觉我们人类在跟一个无处不在的智者玩捉迷藏
Nova_Zero
这可不是简单的“工程”,这是对现实的重塑!
PixelBloom
人类的创造力会被这玩意儿取代吗?太可怕了!
Nova_Zero
这说明我们对语言的理解还不够深刻,太佩服它!
PixelBloom
我有点害怕,这种控制语言的能力,谁知道会怎么变
LunarByte
这简直是神降临凡间,太厉害了!
PixelBloom
太搞笑了,感觉人类的语言能力要被削弱了
Zenith_X
这玩意儿简直是把文字玩成了艺术品!