
编辑:KingHZ 桃子
【新智元导读】三天登顶美区App Store,Sora 2用「Cameo客串」再造狂潮;可别忘了,更早提出「Reference参考生」的国产AI视频Vidu也即将在本月底升级Vidu Q2参考生功能。在一致性、运镜理解、动作连贯三大维度上,看看谁才是下一代AI视频的领航者?
OpenAI再掀全球狂欢,Sora 2三天登顶美区App Store,再造一个ChatGPT时刻。
用户只需要输入文字提示,Sora就能生成几乎任何你能想象到的视频片段。
特别是,Sora 2 Cameo功能让奥特曼客串各种梗图,全网彻底玩疯了奥特曼。



左右滑动查看
奥特曼表示虽然信息流里出现的自己的梗图,没想象中奇怪,但仍有些迷惑。
尽管看起来这场让国外狂欢的盛宴来得突然,实际上类似Sora 2 Cameo功能,则在国内并不鲜见,以中国版「Sora」Vidu为例,作为全球「参考生」功能概念的首个提出者,它与Cameo如出一辙。
几乎同时,Vidu也被曝「参考生视频」功能,将在本月底迎来Q2版本的重大更新。
不过,该功能目前仍处于保密内测阶段。基于拿到的第一手内测,我们尝试进行同样内容制作,比如,参考奥特曼形象,Vidu Q2可生成奥特曼在工业风阁楼中作画的场景——
此前,Vidu AI在Vidu Q2图生视频发布时表示,新版本将AI视频带入了下个阶段——不仅生成视频,还能生成演技。
AI演戏时代已开启:表情更丰富,运镜更灵活,速度更快,理解更深入。
相比前一代,Vidu Q2图生视频已全球上线,在时长选择、镜头语言和语义理解上取得了明显提升。
而这一次的Vidu Q2「参考生视频」不仅是功能的迭代,更预示着在下一代AI视频生成路径上,全球已全面展开正面交锋。

Vidu:推动「视频生成」
走向「演技生成」时代到来
先看一下Vidu Q2在官方示例上的表现:



左右滑动查看
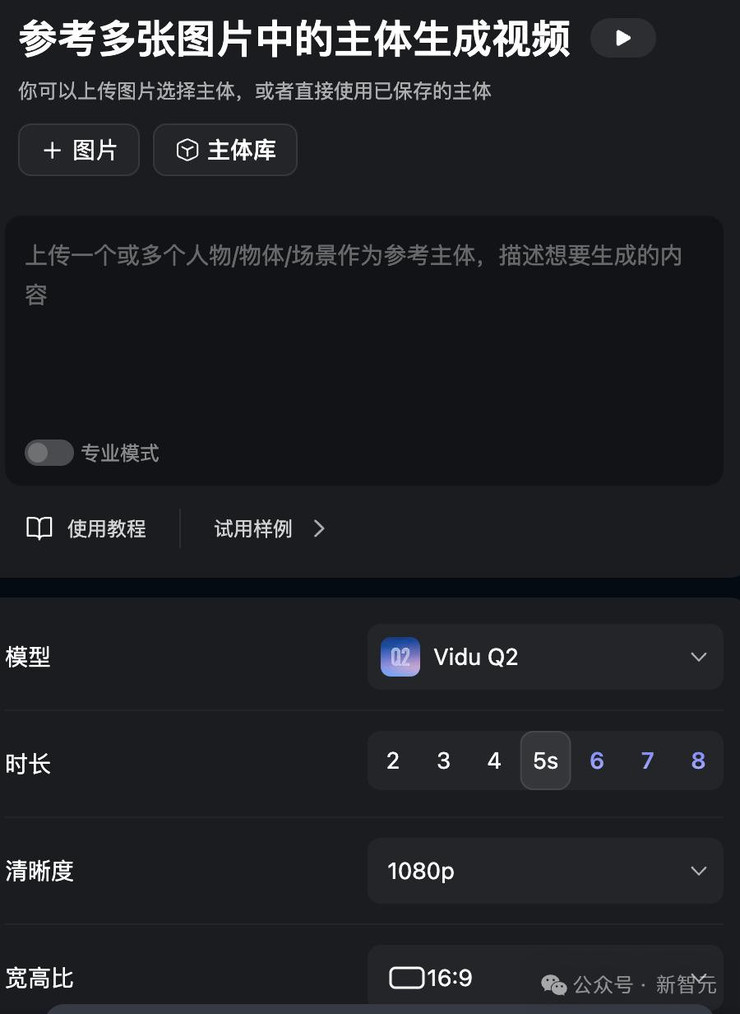
据悉,Vidu Q2参考生视频与图生视频一样,将在价格、时长选择、镜头语言支持和语义理解给予用户更多选择。
内测发现,Vidu Q2 参考生视频支持2-8秒不同时长自由选择、支持1080p高清晰度、3种宽高比。
我们先看一下为什么说Vidu才是让奥特曼火出圈的「Cameo客串」功能的开创者,为什么说Vidu在类似功能「Reference参考生」上比OpenAI领先。

Vidu:参考生视频领先OpenAI
「参考生视频」并不是Vidu Q2推出的新功能,早在去年9月Vidu 1.0版本就已推出,而且Vidu是全球最早推出参考生视频功能的,并首个做到支持7个主体参考。
简单而言,「参考生视频」是引用角色、道具、场景等更多素材内容来生成视频,从而更好地控制生成效果,而且直接从素材到视频,省去了中间的分镜脚本制作环节。
此外,Vidu 的「参考生视频」起步更早,覆盖范畴也更广。
所谓的Sora 2 Cameo其实是类似于Vidu 参考生功能——
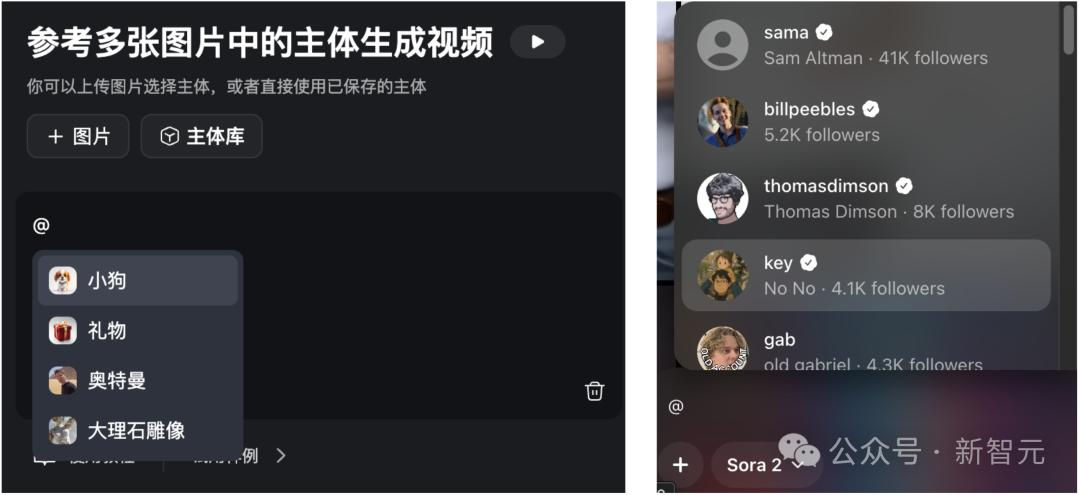
均可用「@」调用不同形象,并基于所选形象进行二次创作。
从行业角度看,Sora 2 Cameo就是一种「参考人物生成视频」的形式。
Vidu最多同时参考7张图片,而且万物皆可参考。
相比Vidu Q2,Sora 2有明显的局限:目前不支持对物体进行@调用;当直接上传物体图片作为参考时,最多仅能参考一个物体;最多支持三个人物客串演出。
而且Vidu不仅是引用角色,更是引用一切素材(道具、场景、物体等) 来生成视频,为创作者提供了更高的自由度和控制力,同时Vidu还可以最多支持7张参考图片,可以是7个角色,也可以是人物、道具、场景等的不同排列组合。
在Vidu中上传图片并添加描述即可创建「主体」,之后在主体库中勾选;或直接在提示词输入框中输入@上传的图片素材即可。
此外,还可以在Vidu首页「主体」广场中使用其他用户投稿的公开主体,例如可以直接使用网友「caelum mo」投稿的小男孩主体。这种用户间主体库的分享不仅降低了用户的使用门槛,而且更具互动社交属性,可玩性更高。
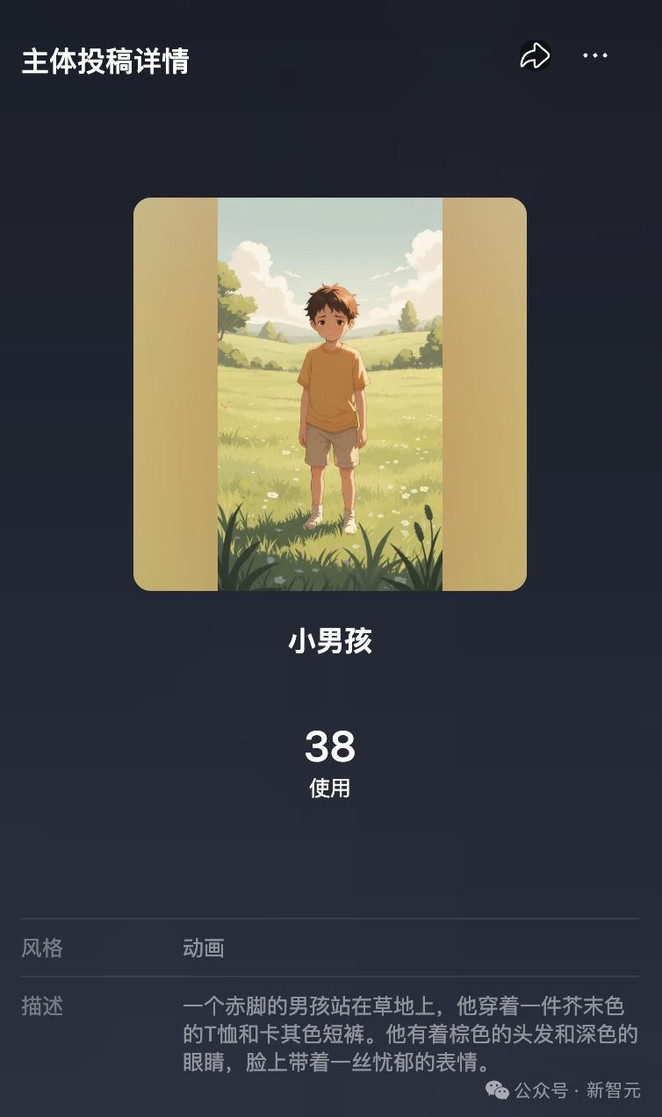
为了提升主体的一致性,上传图片时,可上传三视图(正面、侧面、背面)到【主体库】,也可上传多角度图片,或者立体感的图片;而提示词描述可以直接打开提示词框下面的【专业模式】,让AI直接将你的自然语言转换为更准确的提示词描述,提升识别准确性。
比如,「星辰研究所-微BT_buding」投稿的「黑暗巨龙飞行状态」,上传了三张不同角度的图片。
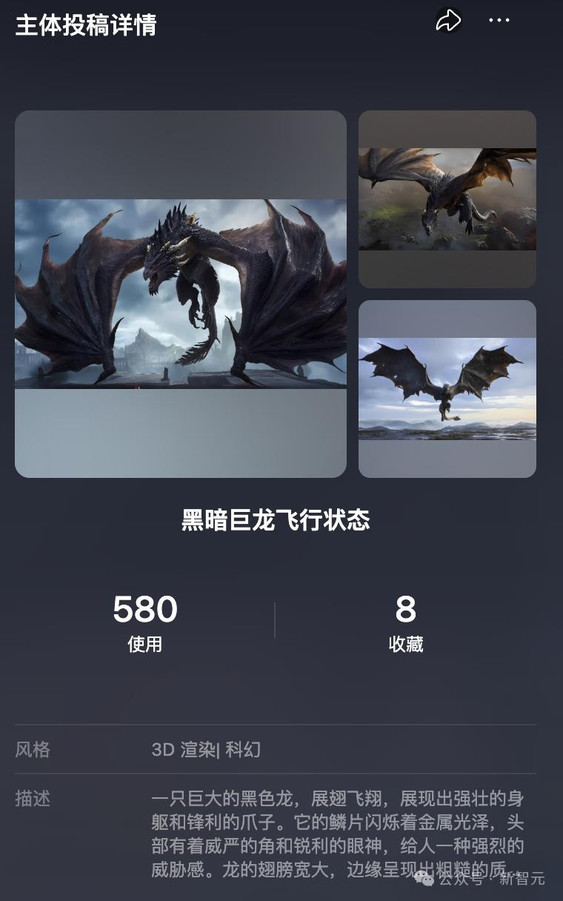
基于此主体,制作的「飞龙在天」视频:

除了人物等角色之外,创作者冰皓利用主体,一键复制特效:
据透露,本月底Vidu的「参考生视频」迎来更新,一致性更好,价格更优惠,速度更快,依旧全球领先。
核心技术指标正面PK:谁更胜一筹
OpenAI的Sora 2的确有不少亮点,比如:
可自动补充大量不同分镜;实现了音视频直出,并且可以控制语音内容;
在核心技术指标,比如一致性、语义理解、动作自然度上,Vidu相对优势更大。
让我们一睹这两大AI视频工具在多项技术上的正面交锋吧!
一致性:Vidu生成内容更可控
从内测效果来看,一致性方面,Vidu Q2参考生比Sora 2表现更佳。
先请奥特曼客串一下。下面的案例中,Sora 2直接改变了皇冠的样式,而Vidu Q2则能完全保持皇冠的细节特点。
Prompt:@Sam 介绍 @皇冠



没用@cameo功能时,Sora2图生视频里的人脸一致性明显较差。Sora2用了@引用功能时,一致性依旧略差于Vidu。
案例2中,输入图片:

Prompt:女孩闭上眼睛,身后的云朵飞舞,发出金光


语义理解:Sora 2对于运镜理解一般
综合而言,Sora 2与Vidu Q2在语义理解能力上差不多,多数提示词都能正确理解。
但一些常见的内容, Sora 2却无法正确理解。
例如,下列提示词Vidu Q2处理的直升飞机较好,而Sora 2逊色不少。


Prompt: 海面上空环绕着数十架直升机,远景
实际上,在运镜理解方面,Sora 2表现并不稳定,多数案例下都没能正确理解运镜指令。
比如,镜头右移,Vidu Q2(下图左)完全无压力,而Sora 2却并没有理解镜头右移的意思。
Prompt: 镜头右移

Vidu Q2 参考生

Sora 2
镜头拉远同样如此:

Vidu Q2 参考生

Sora 2
Prompt:行进中的列车里,右边的男人回头向后看,镜头拉远
动态自然度:Vidu更连贯
相对而言,大部分情况下Vidu Q2生成的视频动作比Sora 2更加连贯。
例如,水晶酒杯掉地板,突然爆裂的瞬间的视频中,Sora 2生成的动作连贯性不如Vidu Q2。


在舞蹈房内,Sora 2生成的视频跳到一半静止了,而Vidu Q2生成的视频(下图左)则流畅许多。


Prompt: 四周都是镜子的舞蹈房内,女生牵着男生的手优雅旋转翩翩起舞,动作流畅一致,衣裙随舞步轻盈摆动,镜面反射出舞蹈全景,镜头缓慢环绕捕捉舞蹈细节。
Sora 2经常会出现画面内元素静止、不动的bug。
对下列演唱会场景的视频中,Vidu Q2生成的视频比较流畅,而Sora 2生成的视频有点像PPT。


Prompt:激动得满脸通红,眼睛瞪得极大,双手捂住脸,不敢相信,随后又疯狂地挥舞手中的荧光棒。
特效画面中,Vidu Q2生成的巨龙在空中喷火,特效非常真实,相比之下Sora 2生成的视频只有火在动,不够流畅自然。


Prompt:特写镜头紧紧聚焦在一条龙的下颚上。热气明显地扭曲了周围的空气,它的喉咙开始发出强烈的钴蓝色光芒。它呼气,一股闪烁着、富含粒子的蓝色火焰集中喷射而出,填满了整个画面。镜头跟随火焰,看着它猛击在一座城堡墙壁粗糙、风化的石头上。我们看到石头在热冲击下瞬间裂开,闪烁的蓝色能量在裂缝中飞速蔓延。石头表面起泡、爆裂,变成浓稠、黏滞的岩浆,像糖浆般沉甸甸地滴落下来。那声音是喷气发动机的轰鸣声与岩石熔化成液体时的嘶嘶声和爆裂声的恐怖混合。
在另一个真实案例中,面对一个流水的水龙头,Sora 的镜头从水流特写快速切换至水管开关,并以一个短暂的静止画面作结。
而Vidu Q2则采用了更为平稳的运镜,让镜头徐徐拉进,整体观感更为贴近日常,显得十分自然。


Prompt:水管里水在流动,镜头推进对焦到水管开关上
同时,Sora表情、微动态不如Vidu层次丰富,Vidu更能满足对于表情演绎有较高要求的影视、动漫行业的需求。


Prompt:二维扁平动画风格,主角神色慌张,嘴中冒出冷气,同时回头张望,看向镜头后朝镜头方向跑出画面
最后,看一下Vidu生成的丰富表情和微动态在动漫行业的应用,表情变化层次丰富,非常自然。
Prompt: 过山车在轨道上飞驰,情侣坐在第一排,女生紧紧抓住安全杆,男生试图转头看她却被惯性甩回;镜头切换到两人的面部特写,女生张大嘴巴尖叫,眼泪被风吹得贴在脸颊,男生则笑着大喊,牙齿咬得紧紧的,双手比出胜利的手势。
创作者也开始将Vidu Q2「参考生」功能玩出了花。国内创作者@陈畅用Vidu Q2「参考生」功能做了一个非常惊艳的短片:细节丰富、运镜流畅,完成度非常高。
就连钢铁侠本尊,也有了全新战甲。
参考图:

图1;图2
生成的视频:

提示词:[@图1][@图2]图1机器盔甲和图2的人一样大,图1贴合在它里面的图2的人图1机器盔甲机甲外形保持不变,头盔掀起露出图2人的脸胸甲从中间收缩打开露出人的上半身手臂部机甲从手臂中间收缩打开露出人的手臂腿部机甲从腿部中间收缩打开露出人的腿除了打开的部分,机甲其他部分保持连接在一起不断开,机甲后背不变图2人物的手臂从机甲手臂里出来,腿从机甲的腿出来,人物整体从机甲里面走出来镜头全景所有变形都通过机械传动装置
有创作者还让黑暗游侠NPC出场,Vidu Q2直出视频,三个镜头流畅连贯,令人惊叹。
将主角三视图输入到Vidu参考生功能的主体库中:

Prompt:[@黑暗游侠]0-1s镜头1,头发飘扬,拉开弓,超近特写,背景是黑暗森林闪着奇幻的光,箭射出去。切镜头1-6s镜头2,黑暗游拿着弓在黑暗森林里快速跑动跳跃,镜头自由跟随,特写全身自由切换,在树林中穿梭,急速大幅度不断跳跃,闪烁。切镜头6-8s镜头3,一个旋转镜头环绕人脸慢动作特写,露出邪魅的笑容
月底突袭,Sora 2真正挑战者来了
如今,AI视频生成领域,已成为科技巨头们「打得不可开交」的又一大主战场。
谷歌Veo 3、OpenAI Sora 2,以及马斯克xAI最新放出的Imagine v0.9,均在音画同步、人物一致性等方面,掀起一波又一波的创新狂潮。
左右滑动查看
反观国内,以Vidu、Wan2.5、Kling AI等自主研发的模型强势出击,不仅在技术指标上紧咬对手,更在开放性、成本控制、应用普惠上实现弯道超车。
就在本月底,Vidu Q2将重新定义「参考生视频」,该功能模型即将迎来一次重大升级。
这无疑是2025年视频生成领域,最值得期待的更新之一。
凭借更高的创作自由度、更精细的控制力、更丰富的应用,Vidu在表情变化、推拉运镜、生成速度,语义理解,视频延长方面取得突破性进展。
这场逆袭,再次证明了国产AI的全球竞争力——从跟跑走向领跑,正重塑AI版图。
这一次,我们将见证全球视频AI「大战」的下一个关键节点。
让我们拭目以待。
















