编辑:好困 KingHZ
【新智元导读】AGI解放80%日常工作,ASI创造超级科学家——阿里巴巴首次公开ASI蓝图,通义千问家族模型性能飙升,超越GPT-5,开启全模态智能时代。
10年前,通用人工智能(AGI)几乎是科幻小说中的想象;如今,全球科技巨头坚信AGI曙光初现。
但阿里巴巴新任CEO吴泳铭,却已悄然转身,目光投向了通往超级人工智能(ASI)的宏伟蓝图。

在2025云栖大会的主舞台上,这位掌控阿里巴巴集团与阿里云智能双舵的领航者,抛出令人震撼的「ASI宣言」:
AGI的实现已是确定性事件,而真正决定未来人类命运的,是将智力维度提升至超越人类的ASI——超级智能。
AGI,仅仅是智能革命的序章;真正的终局,是ASI。
AGI的目标,是将人类从80%的日常工作中解放出来;
而ASI,将创造出一批「超级科学家」和「全栈超级工程师」,以我们难以想象的速度,攻克癌症、发明新材料、解决能源危机,甚至实现星际旅行。
在这条征途上,阿里云将遵循两大战略路径:
第一,通义千问坚定选择开源开放路线,致力于打造「AI时代的Android」;
第二,构建作为「下一代计算机」的超级AI云,为全球提供智能算力网络。

阿里首次公开ASI路线图
过去几百年,工业革命通过机械化放大了人类的体能,信息革命通过数字化放大了人类的信息处理能力。
而这一次,智能化革命将远超想象。
通用人工智能AGI不仅会放大人类智力,还将解放人类的潜能,为超级人工智能ASI的到来铺平道路。
在大会上,吴泳铭首次系统性地揭示了通往ASI的清晰演进路线图——一条分为三大阶段的「智能进化论」:
第一阶段:智能涌现,学习人类(Learning Man)
第二阶段:自主行动,辅助人类(Assisting Man)
第三阶段:自我迭代,超越人类(Surpassing Man)


第一阶段:智能涌现
这一阶段的特征:学习人类(Learning Man)。
这是我们已经历并正在经历的时代。
过去几十年,互联网将人类历史上几乎所有的知识都数字化了。这为智能涌现提供了基础。
大语言模型就像求知若渴、废寝忘食的学生,吞噬了互联网上海量的文本数据——人类知识的全集,涌现了智能。

它学会了理解、对话、推理,甚至在国际数学奥林匹克竞赛中摘得金牌,智力水平从「高中生」飙升至「博士生」。
这是AI进入真实世界、解决现实问题的第一步,也是一切后续进化的基石。
第二阶段:自主行动
在这个阶段,AI不再局限于语言交流,而是具备了在真实世界中行动的能力。
这一阶段,AI最大的特征是辅助人(Assisting Man)。
吴泳铭判断:「这正是我们当下所处的阶段。」
因学会创造和使用工具,人类祖先开启了文明加速键。
如今,AI也掌握了这些关键技能:
- 掌握工具(Tool Use):通过调用外部软件、API和物理设备,AI能够像人类助手一样,预订机票、分析财报、执行复杂的任务。
- 编程能力(Coding): 如果说使用工具是让AI执行已知任务,那么编程能力则是赋予AI创造无限可能的力量。
未来,自然语言就是AI时代的源代码。你只需用母语下达指令,AI就能为你编写代码、搭建系统,创造出专属于你的Agent(智能体)。
在这个阶段,AI将作为人类的超级辅助,极大地提升生产力。
吴泳铭预言,未来将有超过全球人口的Agent和机器人,与人类协同工作。
第三阶段:自我迭代
这一阶段,AI的最大特征是超越人类(Surpassing Man)。
这是通往ASI之路上最关键、也最激动人心的一跃。吴泳铭认为,要实现这一步,必须满足两个关键要素:
AI连接了真实世界的全量原始数据、Self-learning(自主学习)。
目前AI学习的,大多是人类归纳总结后的「二手知识」。而AI要实现超越人类的突破,就需要直接从物理世界获取更全面、更原始的数据。
吴泳铭举了一个生动的例子:一位汽车CEO要迭代产品,需要无数次用户调研和头脑风暴。
但如果AI能直接连接这款汽车的所有资料和数据,它设计的下一代产品将远超人类智慧的结晶。
新一代自动驾驶放弃了繁琐的规则,转而采用端到端模型,直接从原始摄像头数据中学习,从而实现了更高水平的自动驾驶能力。
与此类似,要进入更高的阶段,只有让AI与真实世界持续互动,获取更全面、更真实、更实时的数据,才能更好地理解和模拟世界,才能创造出超越人的智能。
当AI深度融入物理世界,掌握了海量原始数据后,它将有能力为自己搭建训练环境、优化数据流程、甚至改进模型架构。
它将通过与真实世界的持续交互和反馈,像生物一样进行强化学习,实现永不停止的自我进化。
每一次交互都是一次微调,每一次反馈都是一次参数优化。
当这个循环跨过某个奇点,早期的ASI便会成型。届时,人类社会将像按下了加速键,科技进步将呈指数级爆发。
吴泳铭表示:
这条通往超级人工智能的道路,在我们的眼前正在日益清晰。
随着AI技术的演进和需求爆发,AI也将催生IT产业的巨大变革。对未来,阿里有两大判断,并做了两大战略选择。
押注下一代OS和计算机
阿里的第一个判断是:大模型是下一代操作系统。

大模型代表的技术平台将会替代现在的OS的地位,成为下一代的操作系统
一些简单的类比:
自然语言是AI时代的编程语言,Agent是新的软件,Context则是新的Memory;
大模型通过MCP这样的接口来连接各类Tools和Agent,类似于PC时代的总线接口;
Agent之间又通过A2A这样的协议完成多Agent协作,类似于软件之间的API接口。
大模型将会吞噬软件。模型部署方式也会多样化,它将运行在所有设备上。
正是基于这个判断,阿里坚定选择开源。他们的第一个战略选择是:通义千问选择开放路线,打造AI时代的Android。
第二个判断:AI云是下一代的计算机。

大模型是运行于AI Cloud之上的新计算机。每个人都将拥有几十甚至上百个Agent,这些Agent 24小时不间断地工作和协同。
这需要超大规模的基础设施和全栈的技术积累,只有超级AI云才能够承载这样的海量需求。
未来,全世界可能只会有5-6个超级云计算平台。
在这个新时代,AI将会替代能源的地位,成为最重要的商品。
绝大部分AI能力将以Token的形式在云计算网络上产生和输送。Token就是未来的电。
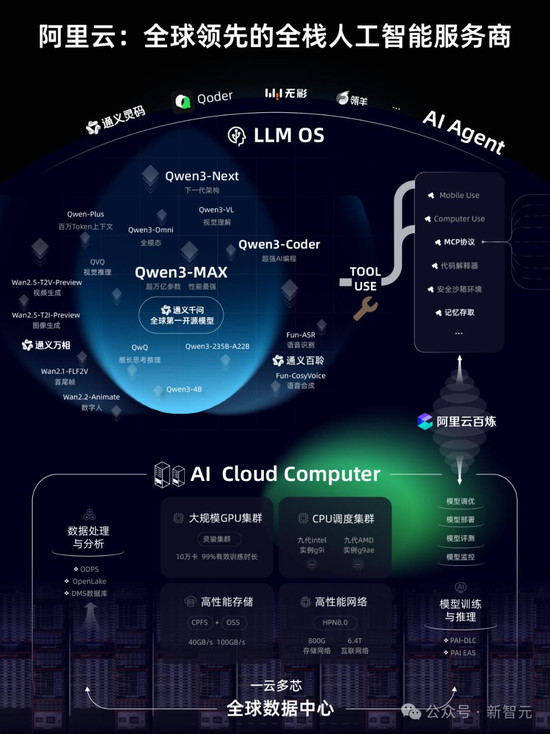
而阿里云的定位是全栈人工智能服务商,提供世界领先的智能能力和AI云计算网络,向全球各地提供AI服务。
为了迎接ASI的到来,在全球数据中心的能耗规模上,与2022年相比,2032年阿里云将提升10倍。
阿里相信通过饱和式投入,能够推动AI行业的发展。
未来,每个家庭、工厂、公司,都会有众多的Agent和机器人24小时为人服务。
正如电曾经放大了人类物理力量的杠杆,ASI将指数级放大人类的智力杠杆。
过去我们消耗10个小时的时间,获得10小时的结果。未来,AI可以让我们10小时的产出乘以十倍、百倍的杠杆。
大模型「源神」,通义全家桶登场
如果说吴泳铭描绘的,是通往超级人工智能(ASI)的宏伟蓝图——一个超越人类、自我迭代的终极智能时代。
那么,阿里通义团队所做的,便是以一场史无前例的「AI模型发布风暴」,将这片星海化为了触手可及的现实。
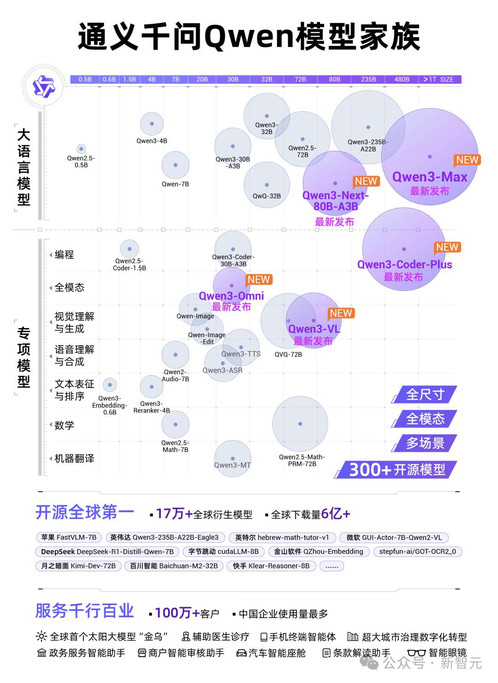
从性能超越GPT-5的旗舰语言模型Qwen3-Max,到能「看懂并复刻」整个世界的视觉模型Qwen3-VL,再到像人类一样听说读写的全模态模型Qwen3-Omni,团队几乎在每一个关键赛道上,都向现有的全球霸主发起了最猛烈的冲击。
Qwen3-Max,稳居全球前三
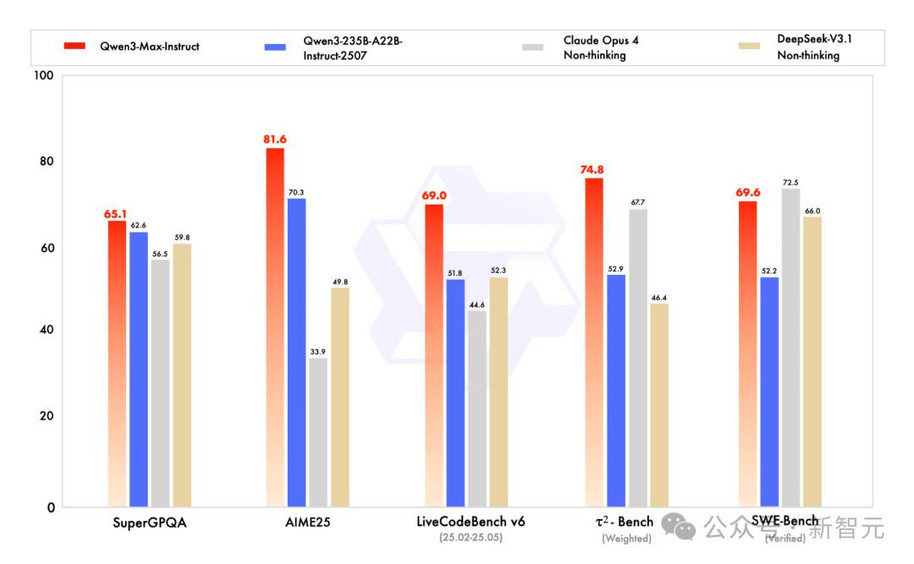
首先,是通义千问家族中最强大、最核心的Qwen3-Max。
根据最新的评测结果,正式版模型的性能已成功超越GPT-5和Claude Opus 4,跻身全球前三。
- 在预训练方面,Qwen3-Max使用了高达36T token的数据,总参数量超过万亿。
- 推理增强版Qwen3-Max-Thinking-Heavy,则在聚焦数学的顶级竞赛AIME 25和HMMT测试中,取得了双满分(100分)的突破性成绩,这在国内尚属首次。
- 在衡量大模型解决真实世界编程问题的权威测试SWE-Bench中,Qwen3-Max斩获69.6分,稳居全球第一梯队。
- 在考验Agent工具调用能力的Tau2-Bench中,它更是以74.8分的成绩,将Claude Opus 4等一众顶尖模型甩在身后。
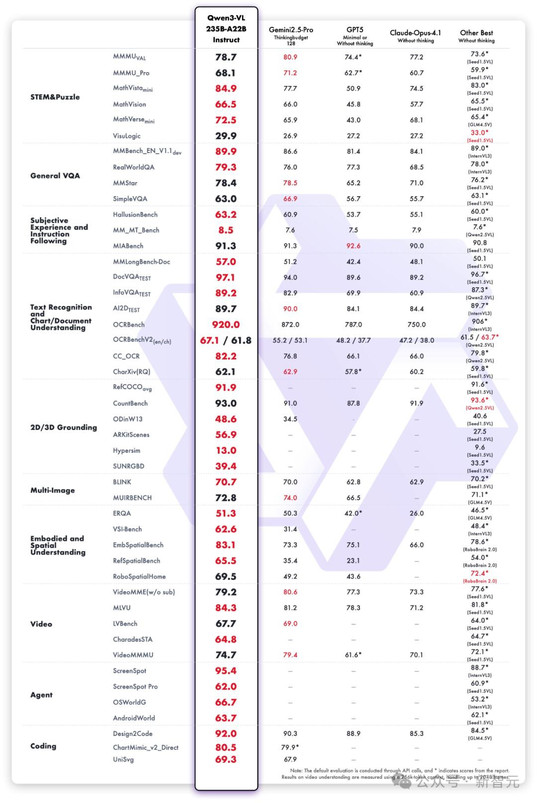
Qwen3-VL,从「看见」到「复刻」
如果说Qwen3-Max是智慧的大脑,那么Qwen3-VL就是它那双洞察万物、并能付诸行动的眼睛和双手。
在多达32项核心能力测评中,Qwen3-VL全面超越了Gemini 2.5-Pro和GPT-5,刷新了开源多模态模型的性能天花板。
- 超级视觉智能体(Visual Agent):Qwen3-VL能像一个熟练的数字助理一样,操作你的手机和电脑——打开应用、点击按钮、填写信息。当你给它一张图片,它甚至能自行调用Agent工具(如抠图、搜索)放大细节,通过更仔细的「观察」,推理出更精准的答案。
- 视觉编程(Visual Coding):只需给Qwen3-VL一张网页设计草图,它能立刻生成对应的HTML/CSS/JS代码;你给它一段小游戏视频,它能直接「视觉编程」,复刻出游戏程序。
- 三维空间感知力:大模型的空间理解能力是实现机器人等具身智能的基石。Qwen3-VL专门增强了3D检测(grounding)能力,能更精准地感知物体的空间方位、视角变化和遮挡关系。这意味着,未来搭载Qwen3-VL的机器人,可以轻松判断桌上苹果的精确位置和距离,实现精准抓取。
此外,Qwen3-VL还支持百万级tokens的上下文窗口,能够轻松「消化」长达2小时的视频或数百页的技术文档,并根据时间戳进行精准问答。
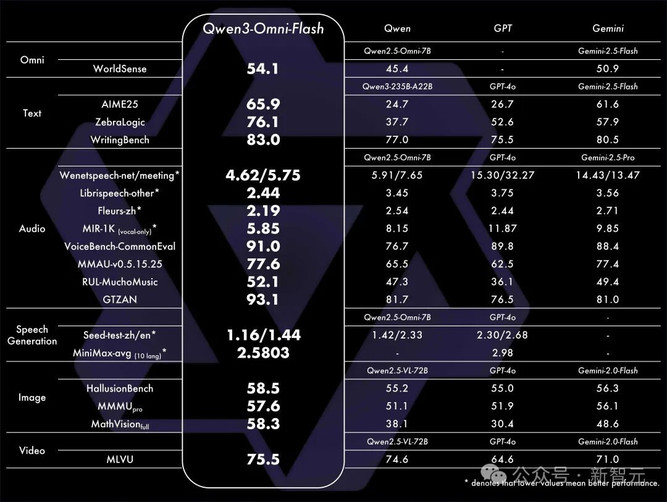
Qwen3-Omni,模型全感官觉醒
Qwen3-Omni全模态模型的发布,则是为了让AI像人类一样,能够自然地「听说读写」。
其最大的技术突破在于,解决了业内长期存在的「跷跷板效应」。
过去,多模态混合训练后,模型往往顾此失彼,提升了音频能力,文字能力却会「降智」。
而Qwen3-Omni在业内首次实现了强劲音视频能力与顶尖文图性能的齐头并进。
- 天生全能:它像人类婴儿一样,从训练之初就混合了「听、说、写」多模态数据,构建了强大的通用表征。
- 双核架构:升级版的「Thinker-Talker」双核架构,如同为AI装上了「大脑」和「发声器」,使得交互速度极快,纯模型音频对话延迟低至211毫秒,几乎无法察觉。
- 应用广泛:它能处理长达30分钟的音频,无需切割即可精准识别并深度理解。未来,它将被部署于车载系统、智能眼镜和手机中,成为你专属的、可定制声音与风格的个人AI伴侣。
与此同时,阿里还发布了专业的语音模型家族通义百聆,包括语音识别的Fun-ASR和语音合成的Fun-CosyVoice。
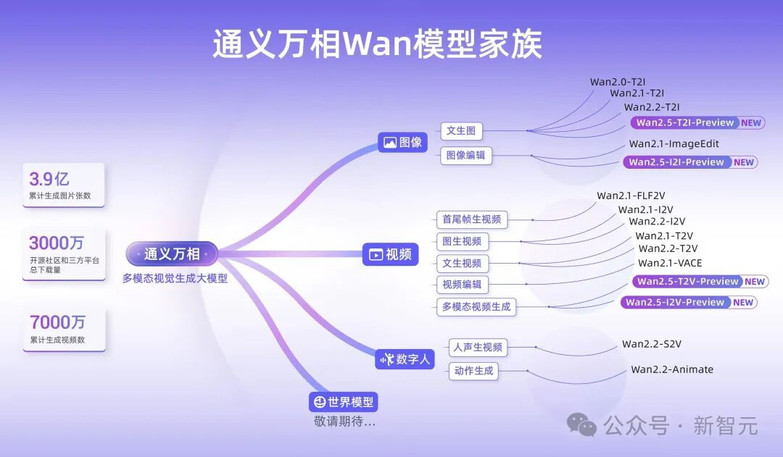
通义万相2.5,AI造梦工坊
在AI的逻辑与感知能力之外,创造力是另一片广阔的疆域。
通义万相Wan2.5 preview系列模型的发布,旨在将电影级的视频创作门槛,降到人人皆可参与的程度。
本次升级的核心亮点,是首次实现了音画同步的视频生成能力。
想象一下,你只需输入一段详尽的Prompt,比如那段关于「外国男子在公园玩滑板」的描述,通义万相2.5不仅能精准还原画面中的人物动作、镜头角度、光影色调,还能同步生成匹配的都市电子音乐、滑板摩擦地面的沙沙声,甚至在男子落地瞬间那声轻快自信的「Yeah!」。
声音与画面、口型完美匹配,让生成的视频充满了生命力。
除此之外,通义万相2.5还带来了全方位的创作力升级:
- 更长更清晰:视频生成时长提升至10秒,支持24帧/秒的1080P高清画质。
- 更懂指令:能理解「运镜」等复杂连续变化指令,让视频叙事更具动感。
- 更强的图像能力:不仅能「一句话P图」,还能生成包含复杂文字排版、流程图、架构图的专业图像。
凭借原生多模态架构,通义万相正在成为一个全能的视觉创作平台。
其家族模型累计生成了3.9亿张图片和7000万个视频,开源模型下载量超3000万,已然是开源社区最受欢迎的视频生成模型之一。