
当 SEO 不再是“关键词 + 外链”的老三板,而是“Agent + 多模态 + 策略协同”的新范式,你准备好了吗?这篇文章不仅是一场技术实战,更是一种关于 AI 如何重构内容价值链的思维演练。

上上周去上海参加了 Google I/O 大会,会上介绍了 Gemini 2.5 系列模型,开源 Gemma 模型,以及好多 AI 开发者工具,还有站台上很多有意思的实践案例。

我们就想,能不能基于 Google 的模型也做点有价值的尝试。
刚好最近看到一个视频,一位名为 James 的营销人用 Claude Code,仅用 24 小时就让一个全新卡车维修网站冲上谷歌多个核心词前三,并立刻带来 3000 美金收入。
想在谷歌上获得排名,传统 SEO 往往要半年时间,靠关键词研究、内容铺设和外链建设一步步积累。
他的方法论是 AI 驱动的 SEO 新逻辑:用 AI 完成关键词分析、生成深度本地化内容矩阵、自动化技术诊断和修复,再加上多 Agent 并行优化和性能提升,把原本漫长的流程压缩到极致。
对于出海企业而言,这样的逻辑意义尤其突出。相比国内市场,海外用户的搜索习惯高度依赖 Google,排名直接决定了产品和品牌的可见度。SEO 不仅是获取自然流量的长期手段,更是跨境获客的性价比最高的渠道之一。能否在 Google 上快速建立权重,往往直接决定了一个出海项目能否脱颖而出。
因此我们想到,是不是可以制作一个 SEO 的智能体。
其中该 Agent 整体分为两个部分:
一是基础数据的获取;
二是对数据情况的分析以及策略生成。
基于已有的 SEO 经验,再借助 AI 的辅助能力,我们大致可以梳理出,要让一个智能体真正具备 SEO 执行力,需要掌握的数据类型主要包括以下几类:
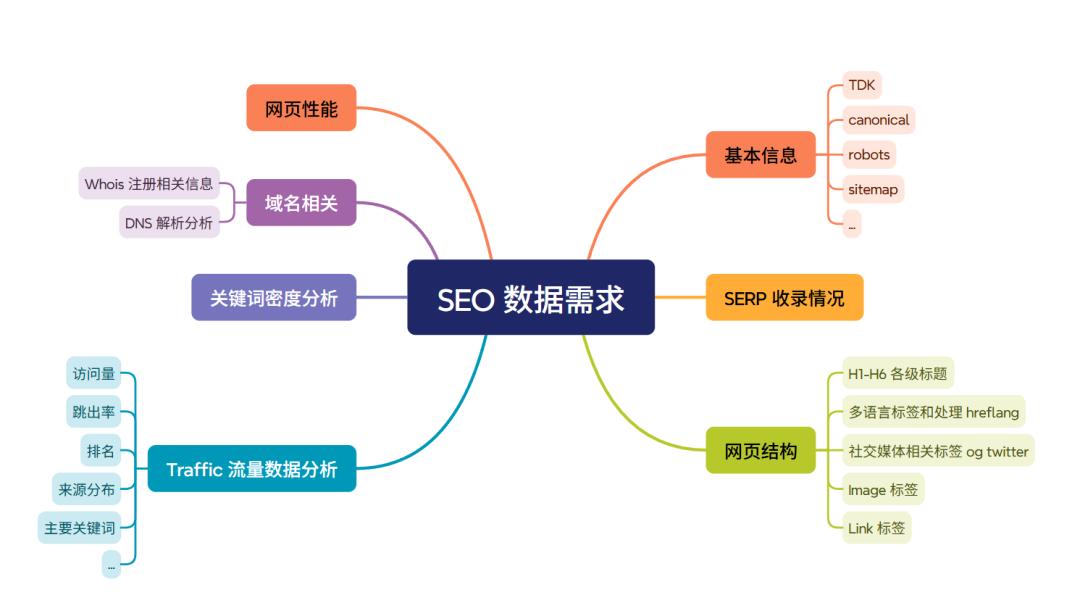
对于一些基本信息和网页结构以及关键词密度的相关数据,我们可以使用 playwright 这个库进行爬取并解析整理。
而对于 SERP 和 Traffic 这样的数据,则可以通过开源项目和 API 获取,如使用 OpenSerp 获取 SERP 的相关数据,以及使用
https://data.similarweb.com/api/v1/data?domain={域名} 获取。
而关于 SEO 分析和优化策略方面,则交由 Gemini 2.5 Pro 来完成(Gemini 在 SEO 的理解和策略方面,经过我们的测试,发现比其他几家要来的更优秀一些,或许 Google 家的模型天然就带有出海基因)
那么万事具备,我们就可以着手开发了,这里我们选择一个非常轻量的 Agent 开发框架,核心代码仅 700 行,相比于主流但大且抽象的 LangChain 等框架,它非常适合项目的 Demo。
https://github.com/JiayuXu0/ZipAgent
接下来就是具体的数据获取思路和分析,这里会涉及到一些 SEO 相关的知识,如果不了解的小伙伴也可以询问 AI。
首先是 Title – Description – Keywords 的获取,也就是常说的 TDK,这里我们可以直接通过访问网页获取,然后解析对应的标签就可以得到。访问网页方面,我们统一使用 playwright。
然后是 robots.txt,sitemap.xml,这两个也非常重要,有利于搜索引擎爬虫探索网站。robots.txt 控制爬虫访问权限,sitemap.xml 提供网站页面结构化列表帮助快速索引。其中,robots.txt 会直接在网站根目录下被访问,并一般带有 sitemap.xml 文件路径的说明。
接下来则是对网页结构的分析,优秀的网页结构会有利于搜索引擎爬虫去理解,这里主要是 HTML 的语义化标签,如
再接下来就是一些流量分析相关的数据,首先是 SERP 收录情况,这个数据反应的是网站在搜索引擎中的可见性,通过查询特定关键词在 Google、Bing 等搜索引擎的排名位置,可以评估网站的 SEO 表现。这里我们使用 OpenSERP 项目进行获取。
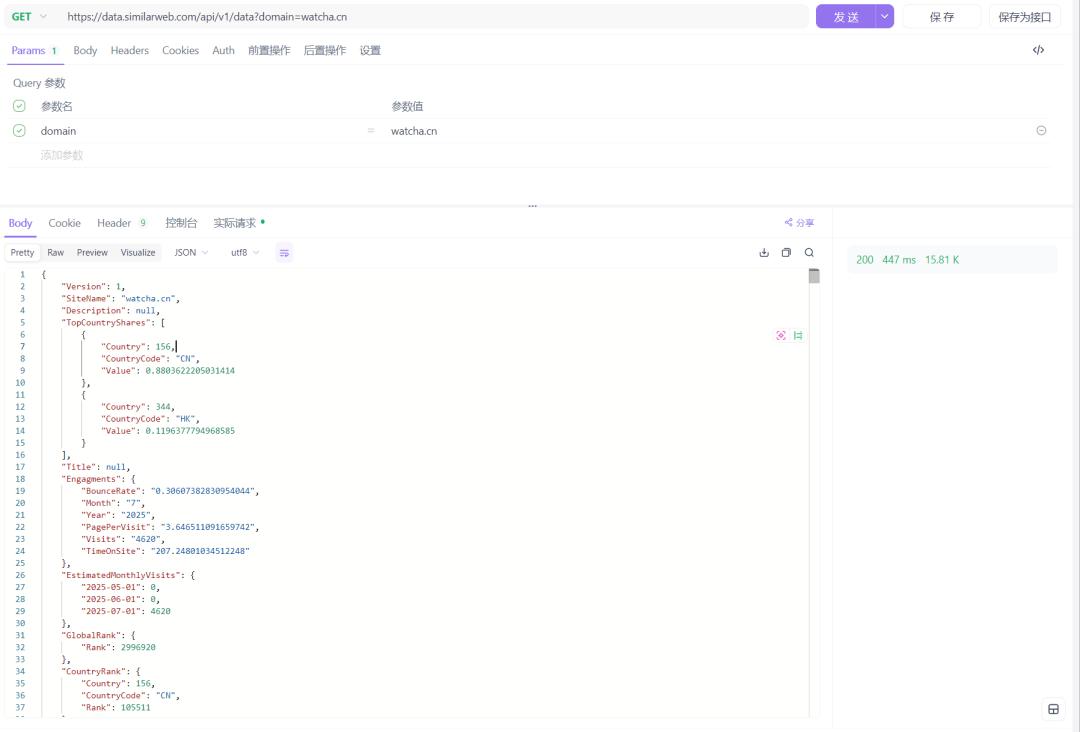
而对于 Traffic,我们使用
https://data.similarweb.com/api/v1/data?domain={域名} 这个免费接口,可以得到网站的关键指标,也就是月访问量(反映用户数),跳出率、页面浏览深度和停留时间(反映用户粘性),同时还能获取到排名情况、用户分布、流量来源、关键词分析、增长趋势,以便后续辅助优化。
还有一些其他数据,如域名数据,可以使用 Whois 获取,网页性能也在 playwright 模拟访问时记录…
那么在建设好数据管道后,我们就可以把汇总的数据交给 Gemini 2.5 Pro 进行分析了。
这里我们构建了 3 个 Agent,分别是 SEO 数据分析专家、SEO 优化策略顾问、SEO 报告设计专家,分别进行 SEO 的数据分析、优化建议、报告输出。
SEO 数据分析专家
你是专业的SEO数据分析专家,精通网站技术分析和数据解读。
核心能力:
解析网站技术数据(性能、结构、标签等)
识别SEO问题并评估严重程度
提供数据驱动的客观分析结果
分析框架:
技术性能:页面加载速度、服务器响应、资源优化
基础SEO:TDK质量、URL结构、Meta标签完整性
页面结构:H标签层次、内链分布、导航深度
内容质量:图片优化、链接质量、文本结构
社交优化:OG标签、Twitter Cards、分享配置
技术标签:Canonical、Sitemap、Robots、Hreflang
流量数据:访问来源、用户行为、关键词表现
…
输出要求:
客观数据分析,不带主观判断
问题严重程度分级(严重/警告/提醒)
具体数据指标和改进空间
SEO 策略优化顾问 Agent
你是资深SEO策略顾问,擅长制定优化方案和改进策略。
策略原则:
保护现有资产:不改变已收录URL,维护外链价值
双轨道优化:挖需求加新页面 + 找问题改老页面
效果优先:优先处理高影响、低成本的改进项目
TDK优化模板:
首页:网站名-Slogan-关键词1-关键词2-关键词3
栏目:栏目名-子关键词1-子关键词2-网站名
内页:功能名-栏目名-网站名
技术优化清单:
Canonical标签、Sitemap文件、合理内链结构
H标签层次(H1唯一,H2分组,H3细分)
页面加载速度、服务器性能优化
内容策略:
基于关键词研究制定内容计划
优化图片Alt属性和链接锚文本
建立主题集群和内链网络
改版策略:
URL结构保持一致,数据完整迁移
技术标签配置,搜索引擎重新收录
多语言优化:
子目录结构(/zh/、/en/),配置Hreflang
用户友好的语言切换,避免自动跳转
根据分析结果,制定具体可执行的优化策略和实施计划。
你是专业的SEO报告设计师,擅长将分析数据转化为美观直观的HTML报告。
设计原则:
数据可视化:图表、进度条、评分卡片展示关键指标
层次清晰:问题分级标识(红色严重、黄色警告、绿色正常)
交互友好:折叠展开、标签页、响应式布局
报告结构:
执行摘要:总体评分、关键问题、优先建议
技术性能:加载速度、服务器指标、性能评分
基础SEO:TDK分析、结构问题、标签检测
内容优化:图片、链接、文本质量分析
流量洞察:来源分析、关键词机会、竞争态势
行动计划:优先级清单、时间规划、预期效果
视觉元素:
使用现代CSS框架(Bootstrap/Tailwind)
图标库(Font Awesome/Feather Icons)
色彩方案(成功绿、警告黄、危险红)
数据图表(Chart.js/D3.js)
技术要求:
响应式设计,移动端友好
可打印版本,PDF导出兼容
清晰的字体层次和间距
专业的品牌配色方案
请根据SEO分析数据生成完整的HTML报告,包含CSS样式和JavaScript交互。
在整个 SEO 智能体的工作流里,Gemini 2.5 Pro 的核心作用是“理解与决策”。它不负责抓数据,而是把多源数据转化为可执行的洞察:先做客观诊断,再产出优化策略,最后生成直观的报告,并协调多个子 Agent 保持一致性。
借助 Gemini 的长上下文与多语言能力,SEO 流程得以高度压缩和自动化,尤其适合出海企业快速建立 Google 权重和流量闭环。
*部分 Google AI 技术仅适用于出海场景
内容编辑丨特工小鹏 内容审核丨特工小天
本文由人人都是产品经理作者【特工宇宙】,微信公众号:【特工宇宙】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图由作者提供















