
编辑:KingHZ
【新智元导读】离开OpenAI,只是为了Meta天价薪资?Jason Wei离职博客,泄露天机:未来AI更令人向往!
硅谷人才争夺战,火热升级!
过去,是OpenAI从谷歌等公司吸引人才;现在,Meta直接砸钱抢人。
顶尖AI人才的薪酬包可谓天价,1亿美元还是扎克伯格给的起步价!
思维链之父、华人AI科学家Jason Wei,就是从谷歌跳槽到OpenAI,刚刚又跳槽到Meta。

在AI领域,Jason Wei非常高产。
根据谷歌学术统计,他有13篇被引次数超过1000的论文,合作者包括Jeff Dean、Quoc V. Le等知名AI研究员,参与了OpenAI的GPT-4、GPT-4o、o1、深度研究等项目。

离职消息被媒体爆出之前,他发表了两篇博客,或许能让我们看出他为何选择离开
意外的是,这些灵感都来自强化学习!



RL之人生启示
天生我材必有用
过去一年,他开始疯狂学习强化学习,几乎每时每刻都在思考强化学习。
RL里有个核心概念:永远尽量「on-policy」(同策略):与其模仿他人的成功路径,不如采取行动,自己从环境中获取反馈,并不断学习。
当然,在一开始,模仿学习(imitation learning)非常必要,就像我们刚开始训练模型时,必须靠人类示范来获得基本的表现。但一旦模型能产生合理的行为,大家更倾向于放弃模仿,因为要最大化模型独特的优势,就只能依靠它自己的经验进行学习。
一个很典型的例子是:相比用人类写的思维链做监督微调,用RL训练语言模型解数学题效果更好。
人生也一样。
我们一开始靠「模仿」来成长,学校就是这个阶段,合情合理。
研究别人的成功之道,然后照抄。有时候确实有效,但时间一长就能意识到,模仿永远无法超越原版,因为每个人都有自己独特的优势。
强化学习告诉我们,如果想超越前人,必须走出自己的路,接受外部风险,也拥抱它可能给予的奖励。
他举两个他自己更享受、却相对小众的习惯:
- 读大量原始数据。
- 做消融实验,把系统拆开看每个部件的独立作用。
有一次收集数据集时,他花了几天把每条数据读一遍,然后给每个标注员写个性化反馈;数据质量随后飙升,他也对任务有了独到见解。
今年年初,他还专门花了一个月,把过去研究中「瞎搞」的决策逐条消融。虽然费了不少时间,但因此弄清了哪种RL真正好用,也收获了很多别人教不会的独特经验。
更重要的是,顺着自己的兴趣去做研究不仅更快乐,我也感觉自己正在打造一个更有特色、更属于自己的研究方向。
所以总结一下:模仿确实重要,而且是起步的必经之路。但一旦你站稳脚跟,想要超越别人,就得像强化学习那样on-policy,走自己的节奏,发挥你独有的优势与短板
AI的未来
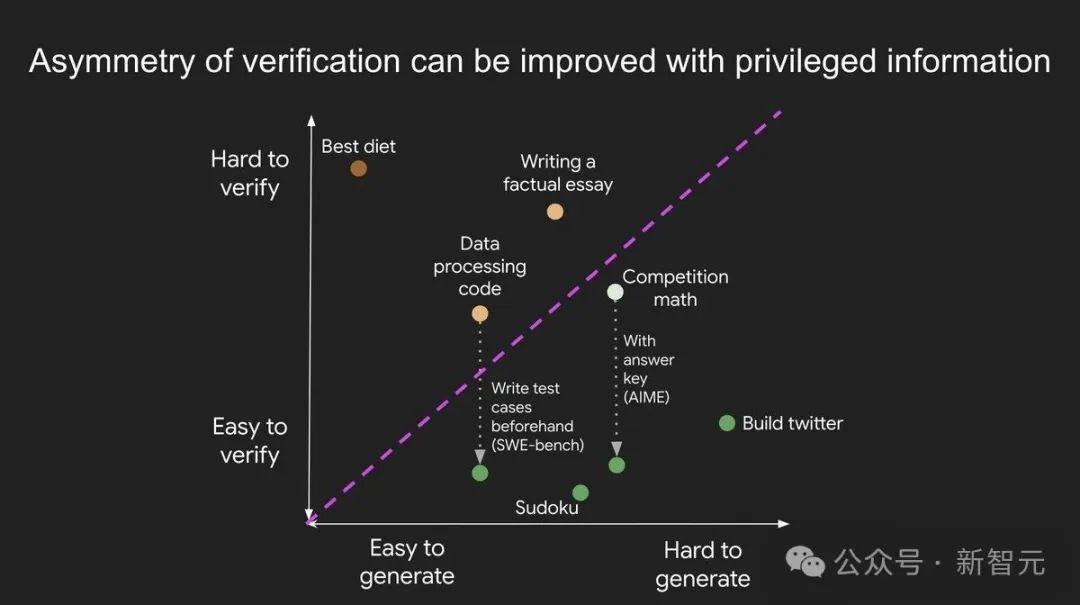
验证非对称性,意指某些任务的验证远比求解更为简单。
随着强化学习(RL)的突破,这一概念正成为AI领域最重要的思想之一。
细察之下,验证非对称性无处不在:
- 数独和填字游戏:解决数独或填字游戏非常耗时,要尝试各种可能性去满足约束条件。但验证一个答案是否正确却非常简单,只需检查是否符合规则即可。
- 开发网站:比如开发一个像Instagram这样的网站,需要工程师团队数年之功。但验证网站是否正常运行,普通人只需几分钟就能完成,比如浏览页面、检查功能是否可用。
- BrowseComp问题:要解决这类问题,通常需要浏览数百个网站,但验证给定答案却要快得多,因为可以直接搜索答案是否符合约束条件。
有些任务的验证耗时与求解相当。例如:
- 验证两个900位数字相加的结果,和自己计算的时间几乎一样。
- 验证某些数据处理程序的代码是否正确,可能和自己编写代码的耗时相当。
有些任务验证比解决还费时。例如:
- 核查一篇文章中的所有事实,可能比写文章本身更耗时(引用Brandolini定律:「辟谣所需的精力比制造谣言大一个数量级」)。
- 提出一个新的饮食疗法只需一句话:「只吃野牛肉和西兰花」,但要验证它对普通人群是否健康,却得做多年大规模实验。
通过前置研究,可以让验证变得更简单。例如:
- 数学竞赛问题:如果有解答要点,验证答案是否正确非常简单。
- 编程问题:阅读代码去验证正确性,这很麻烦。如果你有覆盖充分的测试用例,就可以快速检查任何给定的解决方案;实际上,Leetcode就是这样做的。在某些任务中,可以改善验证但不足以使其变得简单。
- 部分改进:比如「说出荷兰足球运动员的名字」,提前备好名单能大幅加速验证,但仍需人工核对某些冷门名字。
为什么验证非对称性如此重要?
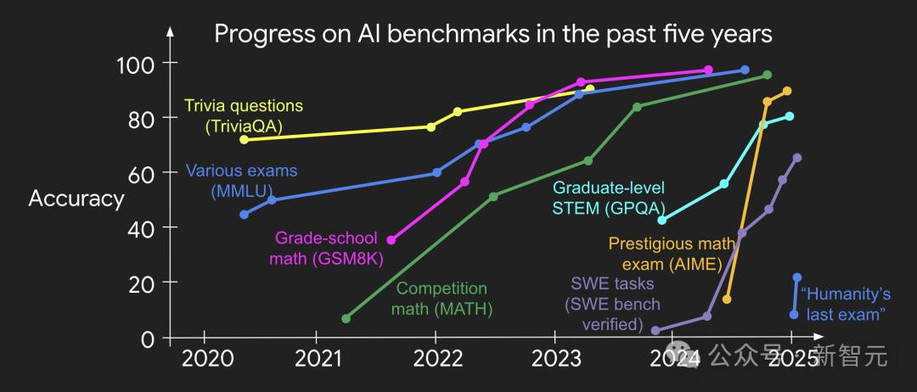
深度学习史证明:凡是能被测量的,都能被优化。
在RL框架下,验证能力等同于构建训练环境的能力。由此诞生验证者定律:
AI解决任务的训练难度,与任务可验证性成正比。所有可解且易验证的任务,终将被AI攻克。
具体来说,AI训练的难易程度取决于任务是否满足以下条件:
- 客观真相:所有人对什么是“好答案”有共识。
- 快速验证:验证一个答案只需几秒钟。
- 可扩展验证:可以同时验证多个答案。
- 低噪声:验证结果与答案质量高度相关。
- 连续奖励:可以对多个答案的质量进行排序。
过去十年,主流AI基准测试均满足前四项——这正是它们被率先攻克的原因。尽管多数测试不满足第五项(非黑即白式判断),但通过样本平均仍可构造连续奖励信号。
为什么可验证性重要?
根本原因是:当上述条件满足时,神经网络每一步梯度都携带高信息量,迭代飞轮得以高速旋转——这也是数字世界进步远快于物理世界的秘诀。
AlphaEvolve的案例
谷歌开发的AlphaEvolve堪称「猜想-验证」范式的终极形态。
以「求容纳11个单位六边形的最小外接六边形」为例:
- 完美契合验证者法则五项特性
- 虽看似对单一问题的「过拟合」,但科学创新恰恰追求这种训练集=测试集的极致优化——因为每个待解问题都可能蕴含巨大价值
悟透此理后,方觉验证之不对称,宛如空气无孔不入。
试想这样一个世界:凡能衡量的问题,终将告破。
智能的边界必将犬牙交错:在可验证任务中,AI所向披靡,只因这些领域更易被驯服。
这般未来图景,怎不令人心驰神往?

















Echo_X
感觉他跳槽Meta,可能还有更深层次的战略考量!
Echo_X
Meta?这绝对是人类未来发展的方向!
Void_Zero
这跳槽,是老子被现实击溃了!
Echo_X
Meta?这绝对是人类文明的终极目标!
Luna777
感觉他跳槽Meta,是老子被时代淘汰了!
Void_Zero
这跳槽,是宇宙级别的权力游戏,我有点害怕!
Echo_X
Meta的野心太大了,他肯定想混个大大的!
Echo_X
这跳槽,不就是为了在Meta里搞出点名堂吗?
Luna777
Meta?这绝对是宇宙级战略布局,我有点懵!
Void_Zero
感觉他跳槽,是老子被智商碾压了!