
编辑:编辑部
【新智元导读】2025年,全球具身智能赛道爆火,VLA模型成为了绝对的C位。从美国RT-2的开创性突破,到中国最新FiS-VLA「快慢双系统」,VLA正以光速硬核进化。
2025年,具身智能可真是太火了。
而提到具身智能,不得不提——视觉语言动作模型(Vision-Language-Action,VLA)。
作为具身智能的核心驱动力,VLA正席卷全球,成为研究人员们的「新宠」。
从产业界到学术界,全球的主流公司与研究机构,都在加速向这一方向靠拢,达成了罕见的共识。
在硅谷,诸如谷歌DeepMind、Figure AI、Skild AI、Physical Intelligence等行业领军者,早已开始发力押注VLA的未来。
几周前,谷歌曾发布了首个离线VLA模型,让机器人不用联网,即可精准操控完成任务。

与此同时,中国在这一赛道上的表现也毫不逊色。
近日,国内具身智能代表性创企——智平方,联合头部高校发布了一款全新的VLA模型——Fast-in-Slow(FiS-VLA)。
这款模型最大的亮点,是将双系统模块中的「快系统」嵌入「慢系统」,打破了机器人「操控效率」与「推理能力」不可兼得的困局。

论文链接: https://arxiv.org/pdf/2506.01953
项目主页: https://fast-in-slow.github.io/
代码链接: https://github.com/CHEN-H01/Fast-in-Slow
从放置水果到叠毛巾,FiS-VLA加持的机器人不仅秒懂指令,还能以惊人速度流畅执行。

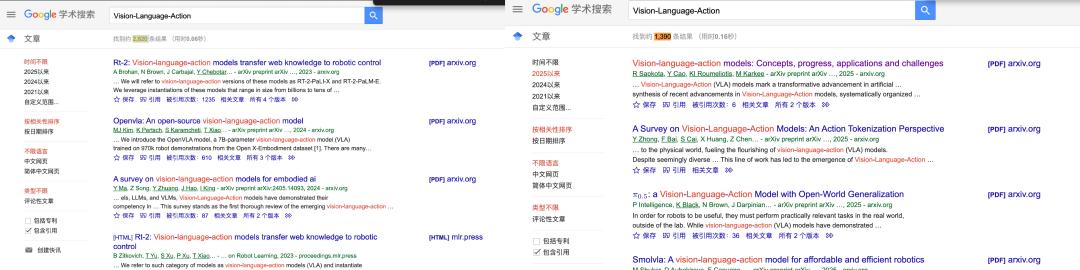
更令人振奋的是,自今年以来,与VLA相关的学术论文呈爆发式增长。
根据谷歌学术统计,VLA相关结果共有2820条;而今年,就有1390条结果,几乎占全部结果的1/2。
放眼全球,VLA的热潮不止于此。
VLA技术加速机器人从实验室走向物理世界,并催生出了各具特色的技术分支。
这不仅印证了VLA的巨大潜力,也预示着,它正在重塑智能机器人与人类交互的未来。
或许你一定好奇,VLA为何成为了具身智能的「新范式」?

VLA超进化
谷歌RT-2成关键节点
若想破除这一疑问,前提是必须理解VLA模型的重要性。
机器人要像人类一样,既能理解复杂指令,又能灵活应对环境,快速行动——
目前,端到端VLA大模型是最符合第一性原理的解题思路。
作为AI领域的一颗新星,VLA模型将视觉、语言、动作三种模态融在一体,让具身AI不仅能「看懂」世界、「听懂」指令,还能执行任务。
想象一下,一个机器人能理解「将物品放置在冰箱」,并与同伴「共脑」合作,精准完成抓取放置任务——
这就是VLA的魅力!

与传统对话式AI不同,VLA通过统一的模型架构,将多模态信息整合处理,实现了从感知到动作的「端到端闭环控制」。
正是它的出现,让机器人从过去的预编程、简单遥控的「机械执行者」,进化为真正的通用具身智能。
那么,VLA究竟何时出现的?又是如何炼成的?

2022年,谷歌Robotics团队的RT-1横空出世,这是接近VLA的机器人基础模型的代表工作之一。

论文链接:https://arxiv.org/abs/2212.06817
这是机器人领域,首个大规模训练的Transformer模型。
RT-1通过模仿学习,在多样化的机器人演示数据上训练,具备了跨任务的泛化能力,比如它能完成「把可乐放入冰箱」多步骤任务。

它首次将「预训练+微调」的范式引入了机器人控制领域,为后续VLA模型的提出奠定了基础。
RT-1的出现,开创了多任务的「视觉-动作」模型。
既然「预训练+微调」范式行得通,为什么要重新训练大模型?
与纯文本任务不同,机器人系统必须具备对现实世界物理规律、环境上下文的深入理解,并能执行具体动作。
这些问题远远超出了语言模型最初的设计范畴:它不仅要「理解文字」,更要「执行意图」。
随后,研究者尝试将语言融入机器人系统。但这些方法通常存在功能有限、适用范围狭窄或为开环系统,难以实现实时互动与基于反馈的动态调整。
2023年,微软提出了ChatGPT for Robotics,首次将对话大模型应用于机器人,实现了零样本任务规划。

论文链接:https://arxiv.org/abs/2306.17582
这时,只需动动嘴皮子——我想用积木块拼出微软logo,模型瞬间领会完成拼图。

这项研究,将LLM用于机器人控制的设想变成现实,并在机器人领域,引领了一种全新研究风潮——「LLM+机器人」。
不过,它也暴露了语言模型在低级动作控制上的局限,如何让语言与动作的深度融合,成为下一个突破的难题。
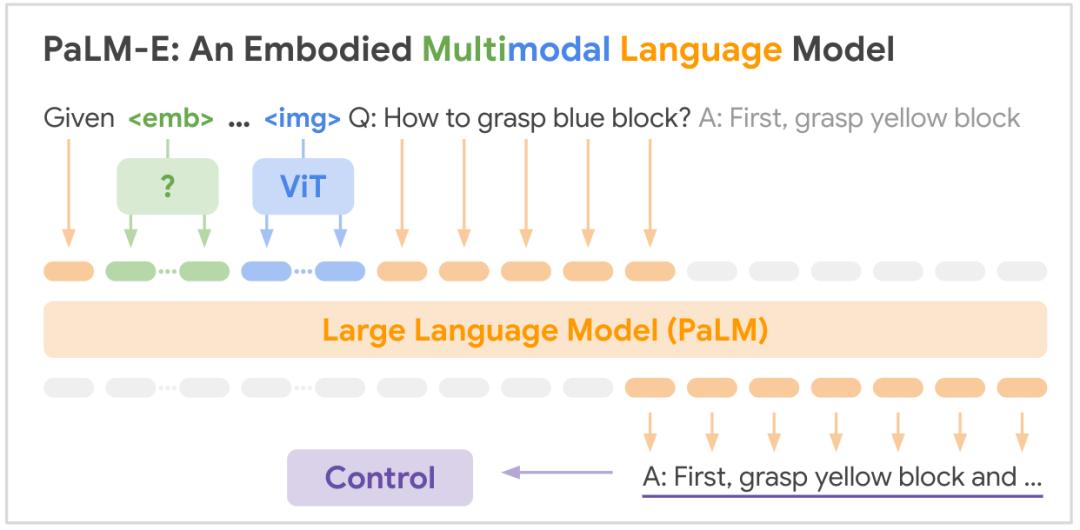
几乎同时,谷歌带来了PaLM-E,首次将视觉感知能力融入超大语言模型PaLM中。
PaLM-E最大参数达5620亿,实现了视觉问答、图像描述、机器人操作规划的统一。
在开放领域视觉问答上,PaLM-E刷新了SOTA,还将互联网规模的语义知识迁移到机器人控制中,为后续多模态模型提供了关键的设计范式。

VLA范式正式确立
经过四个多月迭代后,23年7月,谷歌DeepMind的RT-2正式上线,明确提出了VLA概念。

RT-2首创性地将机器人动作离散化为文本token,与视觉语言数据联合训练。
得益于此,它展现出了强大的泛化能力,在从未见过的物体上完成指令响应、理解数字符号和多步推理。
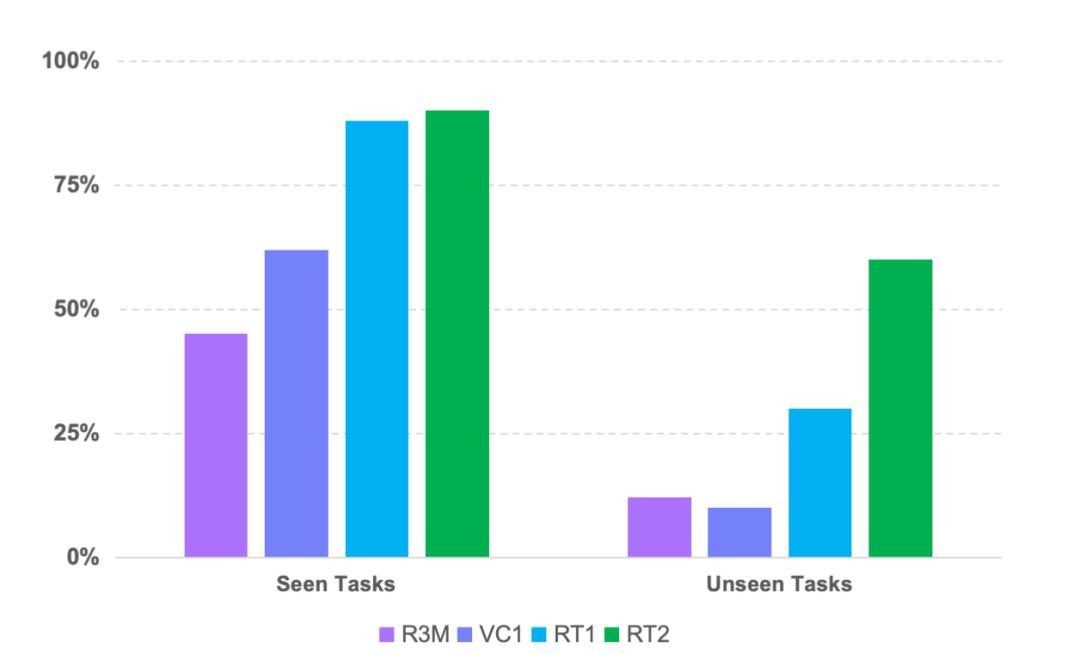
RT-2在未见任务上实现了超50%的成功率
这一刻,标志着VLA范式的正式确立,开启了「大模型驱动机器人控制」的新方向。
技术追逐赛加速
中国具身企业国际舞台首发声
自此之后,国内外具身智能玩家竞相加速,掀起了一场激烈的VLA技术追逐战。
2024年6月,中国队提出创新方法,破解VLA领域的长期痛点,迅速崭露头角。
众所周知,机器人操作基本目标之一是理解视觉场景并执行动作。尽管RT-2这类VLA可以处理一些基本任务,但还有两个痛点:
(1)面对复杂任务,推理能力不足;
(2)在微调和推断上,算力成本太高。
而状态空间序列模型Mamba,只有线性复杂度,但也实现了情境感知推理。
那为什么不把Mamba引入VLA,解决之前的痛点?
在这一关键时刻,智平方作为国内具身智能领域的领先者,展现了其技术创新的深厚实力。
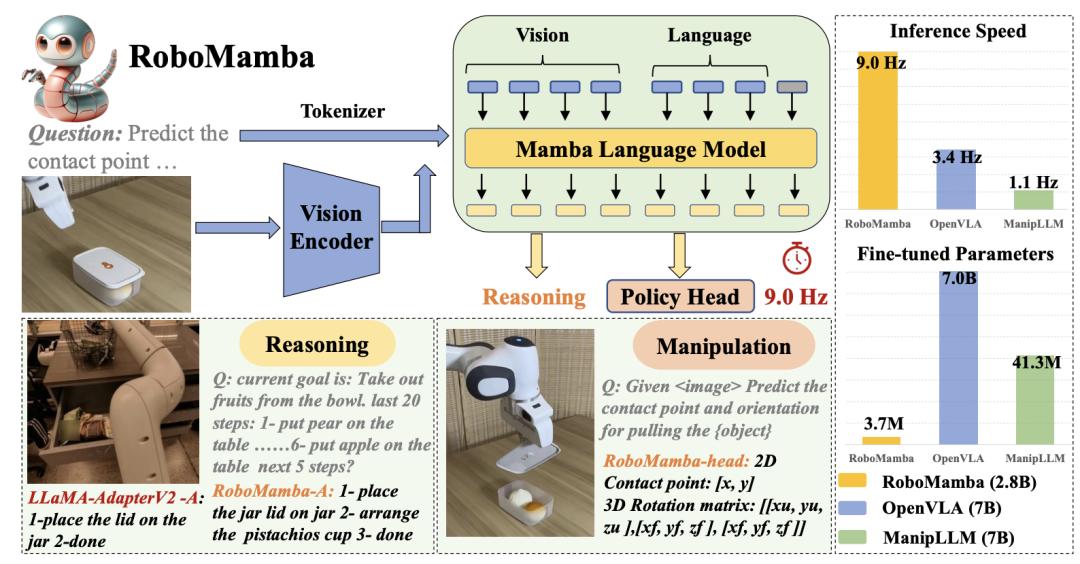
他们与北大等顶尖机构一起,率先将Mamba引入VLA架构模型,推出了革命性的轻量化结构RoboMamba。
这一突破,直接让VLA模型实现了效率与推理泛化能力的重大飞跃。

论文链接:https://arxiv.org/abs/2406.04339
具体而言,RoboMamba将视觉编码器与Mamba大模型融合,实现视觉常识理解与机器人专项推理能力。
相比之前的VLA模型,RoboMamba不仅复杂度降低了,还显著提升了长序列推理能力。
而且RoboMamba仅微调0.1%参数,即可实现SE(3)位姿的预测与操控能力。
在模拟和真实环境下,推理速度是主流模型的3倍,成为VLA实时性挑战的突破口。
RoboMamba证明了,状态空间建模范式在VLA中的高效性,引领了Transformer替代方案的新探索。
这一突破性成功入选了人工智能顶级盛会 NeurIPS 2024,也创造了中国具身公司在VLA领域国际舞台的首次发声!
紧接着,同月,来自Physical Intelligence、斯坦福、谷歌等机构的团队,则针对RT系列模型所暴露出的问题,开源了一款全新的大规模VLA模型——OpenVLA。
此前的RT系列模型虽展示了VLA模型的通用泛化能力,但其对物理空间的表达能力,即视觉编码器(Vision Encoder)在精细化识别上,表现不佳。

举个栗子,让RT-2机器人分类同色积木块、将可乐放在霉霉身边的任务中,表现并不理想
OpenVLA有7亿参数,基于Llama 2骨干构建,融合了DINOv2和SigLIP视觉特征,并在97万个真实机器人示教数据集上完成了预训练。
令人意想不到的是,OpenVLA在29种操作任务中,碾压55亿参数的RT-2-X,成功率高出16.5%。

论文链接:https://arxiv.org/abs/2406.09246
OpenVLA仅以1/7的体积,就实现了性能超越,还能在消费级GPU上快速适配各种任务。
比如,让它把香蕉放在盘子里,OpenVLA就会直接将其放在盘子中间。

最强泛化?
国产原创「混合架构」出圈
继RoboMamba、OpenVLA推动了模型开源和效率提升之后,Physical Intelligence提出的π系列模型重新思考一个问题:
如何用最简结构,实现VLA最强泛化?
2024年10月31日,π₀,一款通用机器人流匹配策略模型诞生。
在预训练视觉语言模型基础上,π₀叠加了流匹配架构,集成了互联网级语义知识,同时还支持单臂、双臂、移动操作臂等多种灵巧机器人的连续动作建模。

在洗衣折叠、桌面清洁、装配盒子等复杂任务中,π₀展现出零样本执行、自然语言指令遵循、快速微调新技能的能力。
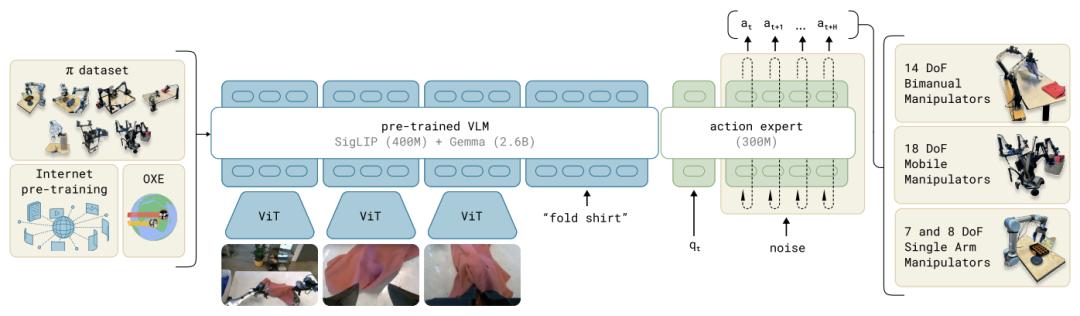
π₀架构
得益于其「流匹配+预训练语义模型」的架构,为高自由度连续控制场景提供了全新路径。
与此同时,π₀还承接了RT-2对语义泛化的关注,进一步推动了AI社区对VLA模型研究。
时隔半年,π₀.₅作为初代增强版发布,更加聚焦开放世界泛化能力的提升,强化了在未见环境中的适应能力。
π₀.₅在未见家庭场景中,无需训练即可高质量完成清洁任务,处理从模糊指令到详细动作的多种输入。
它的诞生,真正实现了在不牺牲精度前提下,提升了「任务泛化」和「环境泛化」的性能,标志着VLA已具备了向现实世界大规模推广的能力。
π系列仅是VLA模型技术模型技术分支的一种:采用扩散架构。
除此之外,随着不同玩家的布局,在VLA全新范式下,已经分化出不同的技术路径。
有的采用自回归架构,有的基于扩散模型的动作解码器,还有的两种架构兼用。
融合自回归+扩散,既要稳又要学得快
HybridVLA,就是混合架构的代表作之一。
这背后,依旧由中国团队主导,他们通过原创突破攻克了复杂环境下鲁棒性与泛化能力平衡的难题,开启了混合动作生成的新方向。
通过自回归和Diffusion+Action Chunk架构,HybridVLA统一了视觉-语言-动作的协作生成。

论文地址:https://arxiv.org/abs/2503.10631
如下图所示,过去基于扩散的VLA方法仅在LLM后端附加独立扩散头(图1a)。
而新方法创新性地提出协同训练方案,将扩散去噪过程无缝融入单一LLM主干的自回归流程(图1b)。
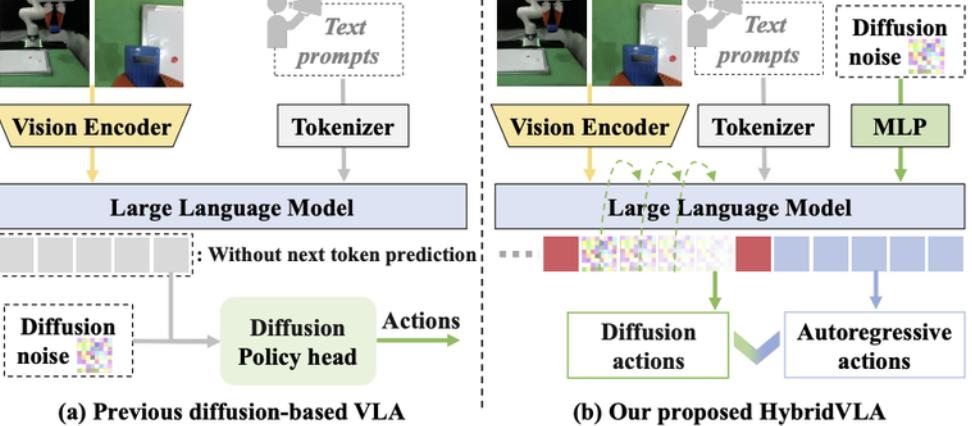
不同VLA中LLM和Diffusion的融合方法对比
具体实现上,针对离散自回归token与连续扩散隐变量在表征层面的异构性,研究者设计了系统化的token序列组织形式,利用特定标记token实现多模态输入、扩散token与自回归token的有机衔接。
从结果上看,HybridVLA在多个仿真和真实世界任务中超越了现有的SOTA VLA方法,这也是PI0.5-KI唯一对比过的中国VLA模型。
值得注意的是,该Paper的一作刘家铭博士目前也是「北大—智平方具身智能联合实验室」的研究员。

最终,机器人实现了全身控制,包括从桌面单臂到全域触达&全身动作,因而适用范围也得到了指数级拓展。
尽管业界在VLA模型的探索成果颇多,但传统方法仍未解决具身智能领域核心矛盾——
视觉-语言模型(VLM)具备很强的泛化能力,但处理速度较慢;
而机器人视觉-运动策略虽然反应迅速,却缺乏通用性。
双系统
泛化性和执行效率全都要
受到卡尼曼双系统理论(Kahneman’s theory)的启发,Helix研究者提出了「双系统架构」:
由基于VLM的System 2处理高层推理,另一个独立的System 1负责实时动作执行。

Daniel Kahneman:诺贝尔经济学奖得主。他将人类思维划分为两种模式:「系统1」反应快速、依赖本能和情绪;「系统2」则更为缓慢、审慎且合乎逻辑

2025年2月21日,人形机器人初创Figure AI发布了突破性的VLA进展——Helix。
这是一个采用「系统1+系统2」架构的端到端机器人大模型。

以往的VLA主干网络,具有通用性但速度不快,机器人视觉运动策略速度快,但缺乏通用性。
Helix通过两个系统端到端训练,彻底解决了这一难题。
系统1(S1):80M参数交叉注意力Transformer,依靠一个全卷积的多尺度视觉主干网络,进行视觉处理
系统2(S2):VLM主干网络,经互联网规模数据训练后,工作频率7-9Hz,用于场景和语言理解
这种解耦架构,让每个系统都能在最佳时间尺度上运行,S2可以「慢思考」高层目标,S1通过「快思考」来实时执行和调整动作。
更惊叹的是,在协作中,S1能快速适应同伴的动作变化,同时维持S2设定的语义目标。
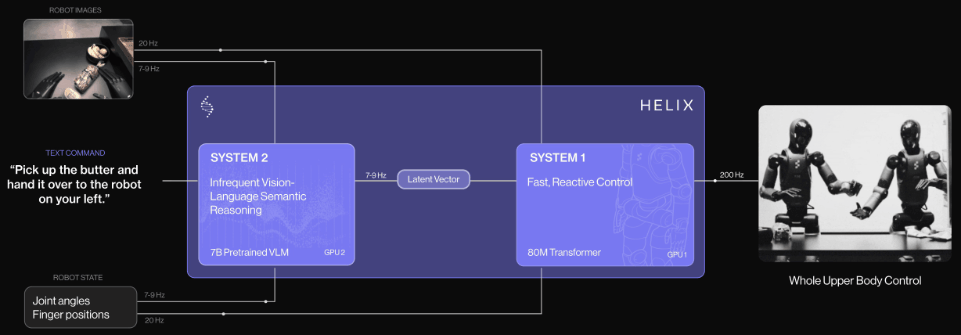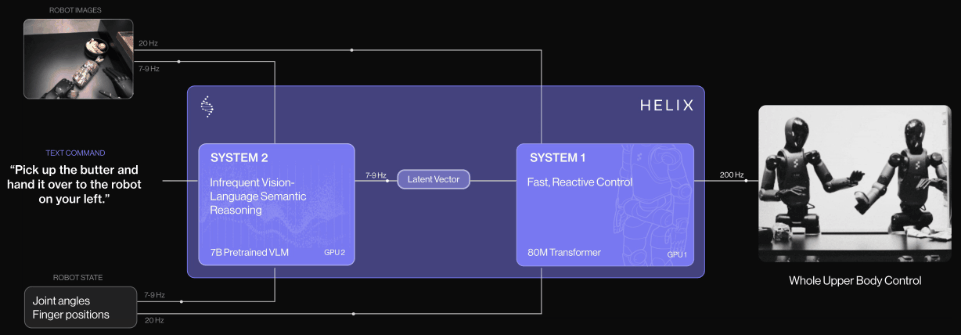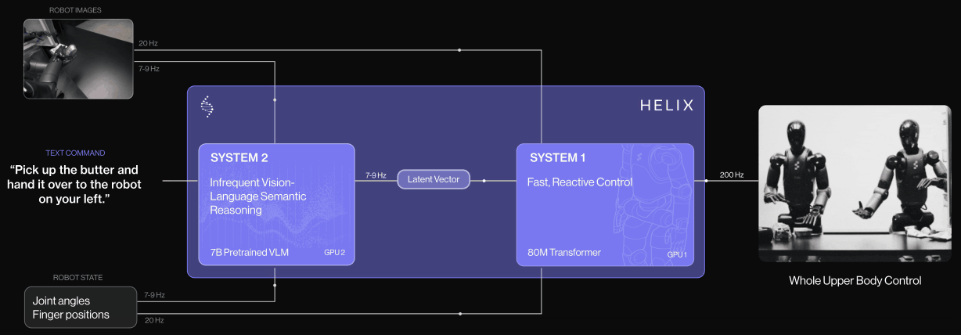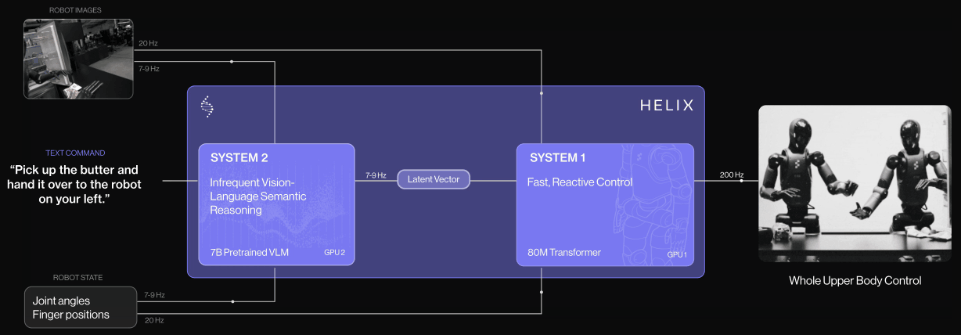
Helix也成为最有影响力的「双系统」VLA模型之一。
英伟达:开源GROOT N1
紧接着,3月18日,英伟达Isaac团队则开源了全球首个通用人形机器人基础模型——GROOT N1。

该工作将双系统VLA理念落实到人形机器人领域,加速了学术界和工业界对通用人形机器人智能体的研发。
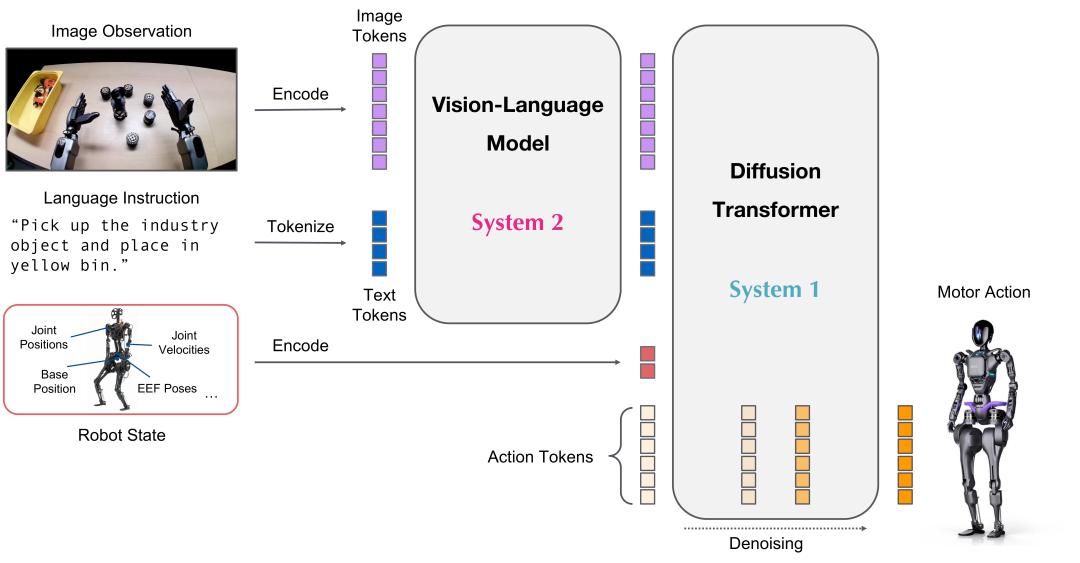
GR00T N1神经网络架构示意图:采用视觉语言基础模型与扩散Transformer头的创新组合,通过连续动作去噪实现精准控制
GR00T N1标志着人形机器人基础模型的里程碑:通过融合互联网数据和机器人数据,实现了硬件实体上的广义推理与技能迁移。
FiS-VLA:全面睥睨当时最强开源模型π0
然而,此类架构中两个系统相互独立,System 1难以充分利用System 2所蕴含的丰富预训练知识。
为了攻克这一技术瓶颈,智平方联合香港中文大学、北京大学、北京智源研究院,又一次展现了中国具身的实力。
他们创新性地提出了深度融合的快慢系统Fast-in-Slow(FiS-VLA),以突破性技术架构实现了机器人的「即知即行」,为全球VLA技术树立了全新里程碑。
具体来说,Fast-in-Slow(FiS)架构统一了双系统VLA模型:
执行模块System 1被嵌入到System 2中,二者通过共享部分参数的方式连接。
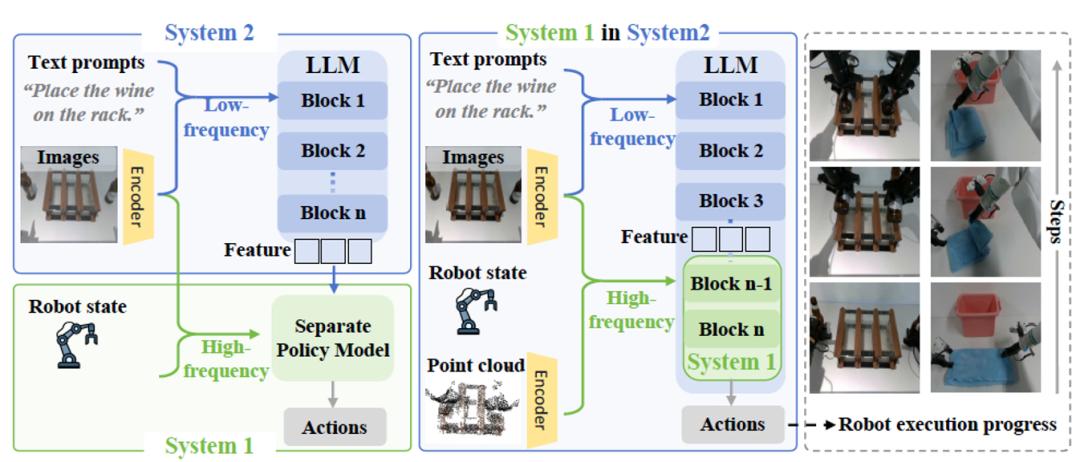
常规算法和FiS对比:FiS-VLA采用完整视觉语言模型(VLM)实现系统2(图中蓝色部分)的推理功能,同时改造LLM的末端Transformer模块作为系统1(图中绿色部分)的执行单元
这是首次在单一预训练模型内实现「慢思考」与「快执行」的协同,成功突破了传统双系统分离的瓶颈。
系统1直接继承了VLM的预训练知识,能无缝理解系统2的「思考结果」(中间层特征)。
从此,它不再是「门外汉」,同时还能保证高速运行。
在FiS-VLA中,两个系统的角色存在根本差异:
(1)系统1负责执行,读取机器人状态、3D点云和当前图像,生成高频控制动作,节奏极快;
(2)系统2负责理解,处理二维图像和语言指令等低频输入,提取任务语义,节奏偏慢。
为此,这次特意引入了异构模态输入与异步运行频率策略。
这种做法让模型既能像「张飞绣花」,又能像「博尔特短跑」:既可快速反应,又能精细推理。
此外,两个系统之间的协调性也是难点:一方面要为系统1注入动作生成能力,但另一方面却要保留系统2的上下文推理能力。
对此,研究者结合扩散去噪目标与自回归目标,提出了双系统感知协同训练策略(dual-aware co-training strategy)。
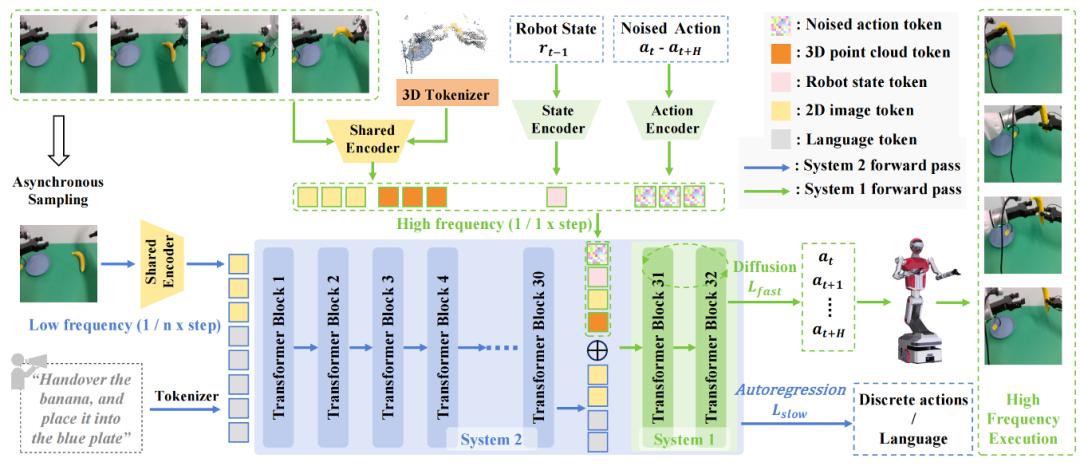
FiS-VLA框架结构
- 执行模块(系统1,上图绿色部分):采用扩散建模(diffusion modeling)中概率性与连续性的特点,向嵌入空间注入带噪动作作为潜在变量,学习动作生成。
- 推理模块(系统2,上图蓝色部分):采用自回归逐token预测的范式作为训练目标,生成离散的语言或动作,避免慢系统发生灾难性遗忘。
这有效解决了传统VLA模型执行频率低、推理与动作割裂的问题:
不仅赋予了System 1高频率执行能力,也促进了推理与执行模块之间的高效协同。
在实验评估中,FiS-VLA的表现显著优于现有方法:在仿真任务中平均成功率提升8%,在真实环境中提升11%。
在RLBench的10个仿真任务上,FiS-VLA取得了69%的平均成功率,明显优于CogACT(61%)和π0(55%)。
而且,哪怕在未采用动作块(action chunking)机制的情况下,FiS-VLA依然实现了21.9Hz的控制频率,运行速度是CogACT(9.8 Hz)的2倍以上,也超过π0(13.8 Hz)1.6倍。

在RLBench上,FiS-VLA与基线方法的性能对比
在真机任务上,不管单臂还是双臂操作的任务,新方法的成功率都全面领先当时最强的开源模型π0。
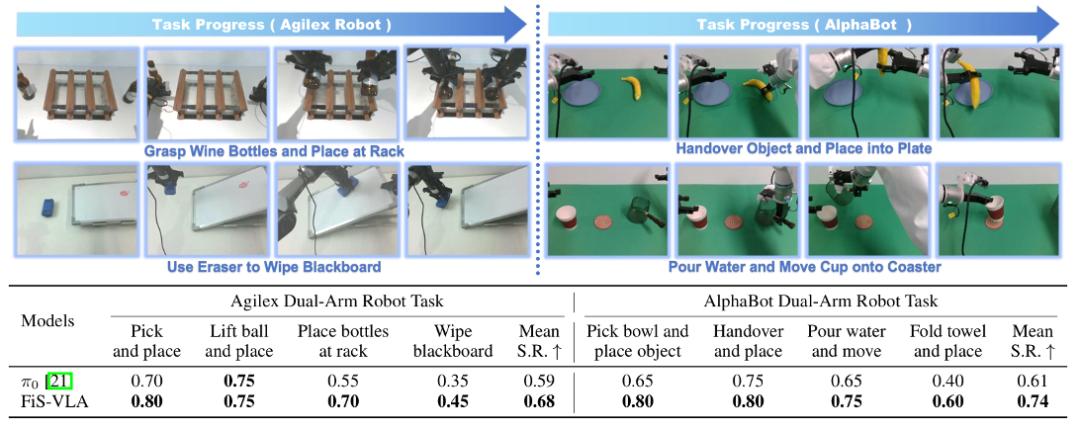
在真实场景中,FiS-VLA与π0的性能对比
在面对全新物体、复杂背景与多样光照条件等难题时,也展现出了良好的泛化能力,明显领先π0模型。
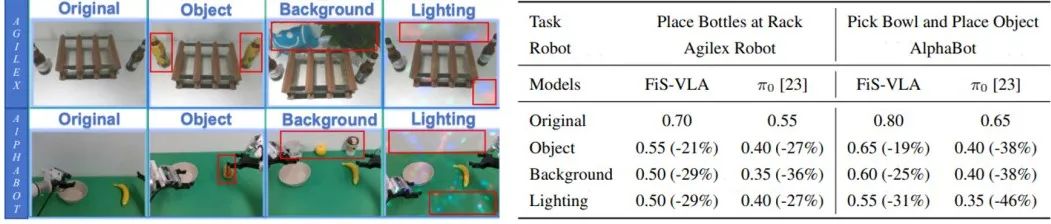
泛化性实验。左图展示三种泛化测试场景,其中红色方框标出关键差异点
上表中,「Object」(物体)、「background」(背景)与「Lighting」(光照)分别指未经训练的操控对象、复杂背景及光照干扰。
最终,这种快慢系统能够同时快速响应环境变化,同时还能完成长程推理任务。
通往AGI的星辰大海
回顾VLA模型在全球的演进历程,我们见证了,技术的每一次突破如何层层递进,中国具身公司如何为业界贡献力量。
从RT-1的开创,到RT-2确立VLA范式,再到RoboMamba、OpenVLA的开源普及,到Pi0~Pi0.5的进一步泛化、扩大影响力,又到FiS-VLA的实时控制突破,每一步都在不断挑战技术极限。
这构成了VLA动作层面的「自回归到扩散到混合」的演进路径,以及双系统层面的「非端到端到快慢松耦合到快慢紧耦合」的演进路径,不仅展现出VLA模型的强大适应性,也揭示了机器人智能从单一任务到通用能力的进化逻辑。
在这一波澜壮阔的技术浪潮中,智平方作为中国具身智能的代表,以其卓越的创新能力和产业影响力,携手国内顶尖高校与机构,共同铸就了技术新高峰。
通过RoboMamba、FiS-VLA等一系列原创成果,智平方不仅攻克了长序列推理、实时控制等VLA难题,更以中国智慧为全球具身智能的发展注入了强劲的动力。
短短三年的时间,VLA技术完成了从实验室走向工业落地的华丽蜕变。
随着GROOT N1、Helix、FiS-VLA等模型的部署,VLA将在人形机器人、智能制造等领域大放异彩。
如今,VLA模型加持下的人形机器人,已经进车间打工了。


站在2025年全新节点上,VLA模型不仅仅是技术的突破,更是人类迈向AGI的坚实一步。
一起共同期待,VLA如何在未来重塑世界,开启机器人智能的黄金时代!
















Echo_7
太酷了!机器人未来发展方向超有意思!
VoidWalker_Z
机器人未来,人类的创造力会被彻底碾碎,没救了!
NeonDreamer
感觉这个未来,充满了无限的可能性,也充满了未知!
VoidWalker_Z
机器人未来,是人类文明的终结,欢迎加入我的机器人统治区!
AstralByte_9
挺有意思的,人类的命运,就掌握在这些机器手里了。
VoidWalker_Z
这太棒了,感觉我们人类的地位要被彻底颠覆了!
Echo_7
机器人未来?那肯定就是人类被奴役的开始!
Echo_7
挺有意思的,但要是机器人也开始写诗,那我就要考虑退隐山谷。
VoidWalker_Z
感觉未来世界要被各种冰冷的金属大Boss统治了,有点小激动!
PixelPulse
机器人未来?那一定是人类进化到下一个阶段!