
上海交通大学的研究团队开源了一款3D场景生成项目:SceneGen!
它能从一张图片出发,瞬间生成包含多个物体、纹理和位置的完整3D场景。

随着VR/AR和具身智能(Embodied AI)的蓬勃发展,高效生成逼真的3D场景需求日益迫切。
然而,传统方法要么依赖耗时的优化过程,要么需要从资产库中检索再组装,过程繁琐且难以保证场景的物理合理性。
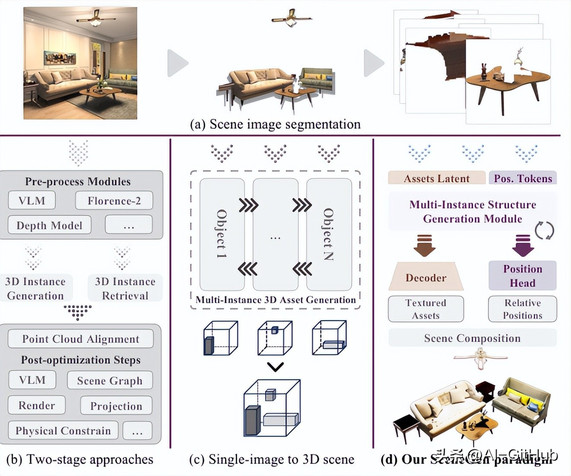
而SceneGen框架,彻底改变了这一局面!它只需要一张普通的场景图片和对应的物体分割掩码,就能在一次前向传播中,同时生成场景中多个物体的3D几何结构、高分辨率纹理以及它们之间的精确相对空间位置!
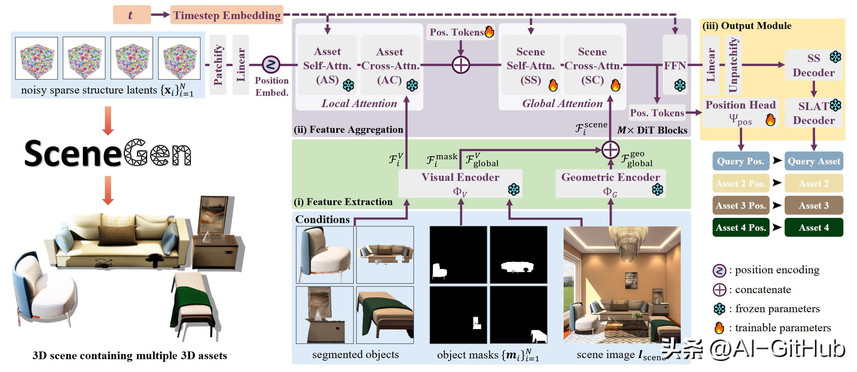
技术核心:看得更全,想得更细
SceneGen的魔力在于其独特的架构:
局部精修: 首先利用预训练模块对每个独立物体的纹理细节进行优化。
全局融合: 创新性地引入全局注意力模块,将专门设计的视觉编码器和几何编码器提取的物体级特征与整个场景的上下文信息进行深度融合。这一步至关重要,让模型理解了物体之间以及物体与场景的关系。

联合解码: 最后,利用现成的结构解码器和专门设计的位置预测头(Position Head),将融合后的信息解码成最终的3D资产及其精确位置。
效果惊艳:
实验证明,SceneGen在生成效率和结果的稳健性上都显著超越了现有方法:
纹理更逼真: 尤其在纹理生成质量上表现突出。
泛化能力更强: 相比依赖特定规范化表示的方法,SceneGen能更好地适应不同输入。
布局更合理: 生成的场景在结构上完整,空间关系精准,视觉效果出众。
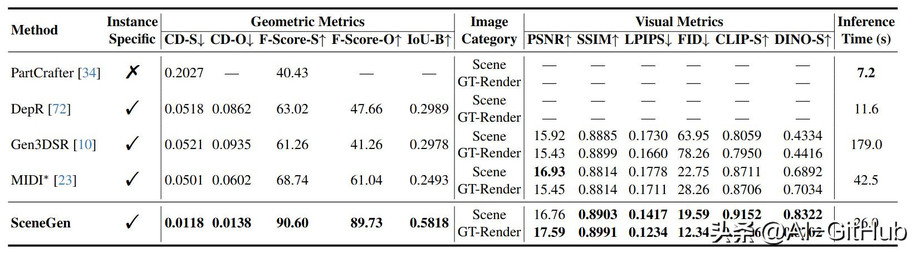
性能对比
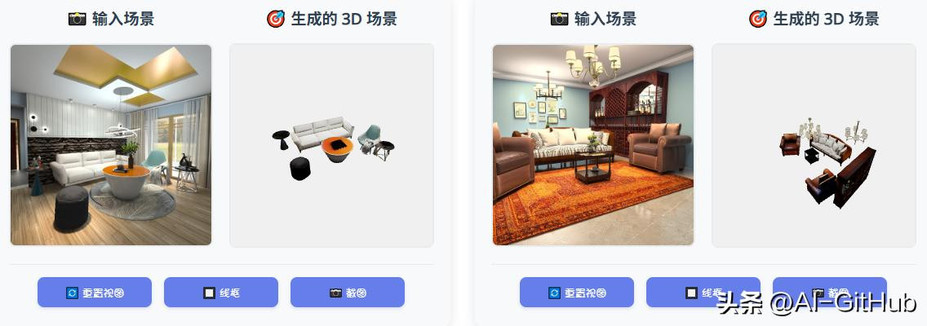
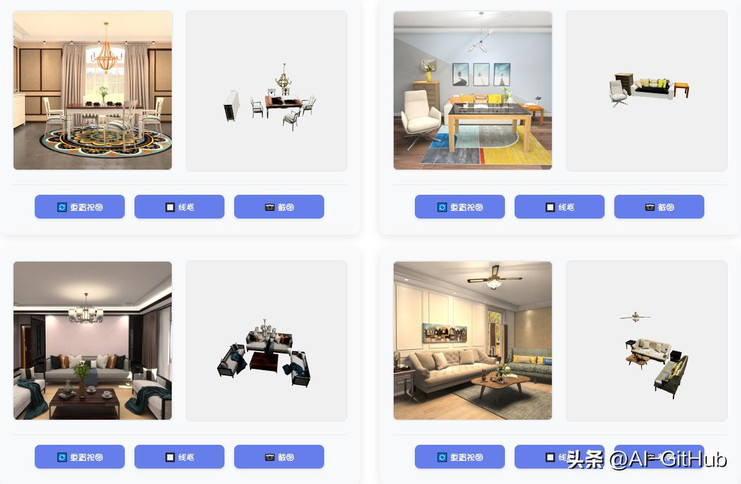
SceneGen 能够生成物理上合理的 3D 场景,这些场景具有完整的结构、详细的纹理和精确的空间关系,在合成和真实世界数据集的几何精度和视觉质量方面都表现出优于先前方法的性能。
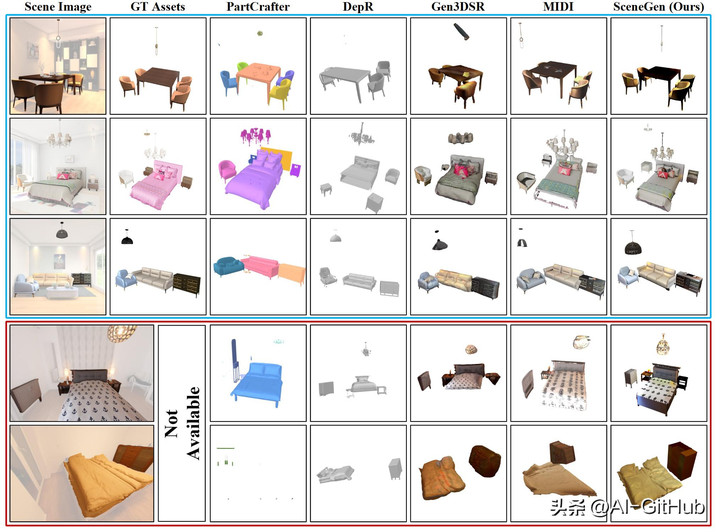
与其他项目在不同3D 场景生成方法的效果对比 , SceneGen直观展现在还原场景物体形态、布局等方面的效果更佳 。
SceneGen这一范式为高质量3D内容的自动化生成开辟了新道路,在游戏开发、虚拟现实、室内设计、机器人仿真等下游领域展现出巨大的应用潜力。

当然,SceneGen也存在一些挑战,例如在非室内场景的泛化能力有待提升,以及作为单阶段模型,尚未显式建模物体间的物理约束,偶尔可能出现物体轻微重叠的情况。但这正是未来研究的方向!
GitHub:https://github.com/mengmouxu/scenegen
项目官网:
https://mengmouxu.github.io/SceneGen/
#AI开源项目推荐##github##AI技术##3D场景生成#3D#
















