

编辑:定慧
【新智元导读】擅长「种草」的小红书正加大技术自研力度,两个月内接连开源三款模型!最新开源的首个多模态大模型dots.vlm1,基于自研视觉编码器构建,实测看穿色盲图,破解数独,解高考数学题,一句话写李白诗风,视觉理解和推理能力都逼近Gemini 2.5 Pro闭源模型。
最近的AI圈只能说是神仙打架,太卷了。
OpenAI终于发了开源模型,Claude从Opus 4升级到4.1,谷歌推出生成游戏世界的Genie 3引发社区热议。
国产模型这边,就在前几天,HuggingFace上排在最前面的10个开源模型还都来自国内。
国产模型前10霸榜和gpt-oss开源后直冲第一
但其实仔细观察这些排名靠前的开源模型,能发现一个「现象」:这些模型大部分都是文本模型,不具备多模态能力。

OpenAI首次开源的模型,也都是文本模型
如果说具备「多模态」能力,还要「好用」,并且是开源的模型,还真的数不出几个。
这边是一群文本模型神仙打架,那边小红书人文智能实验室(Humane Intelligence Lab,hi lab)在昨天低调开源了视觉语言模型dots.vlm1,给VLM带来了意想不到的惊喜。

为什么我们要关注一个不知名团队开源的视觉语言模型?
一个理由是,hi lab在上周开源的dots.ocr文档解析模型冲上了Huggingface的热榜第七,其基础模型是一个17亿参数的「小模型」,但依然实现了业界领先的SOTA性能,成功引起了我们的注意。
这个团队有在认真做事啊!
仔细看了看这个团队的架构和愿景,发现「hi lab」是由小红书内部大模型技术与应用产品团队合并升级而来,在关于hi lab的官方介绍中,特别强调了「将研发重点放在了多元智能形态上」。
他们希望通过融合人际智能、空间智能、音乐智能、人文关怀等各种智能形态,不断拓展人机交互的可能性。
对多模态的信仰和投入的决心可见一斑。
而dots.vlm1,正是小红书hi lab研发并开源的首个多模态大模型。
这个模型基于hi lab全自研的12亿参数NaViT视觉编码器和DeepSeek V3的大语言模型构建,在视觉的理解和推理任务上均有不俗的表现,接近了SOTA水平,并且在纯文本任务中仍保持竞争力。
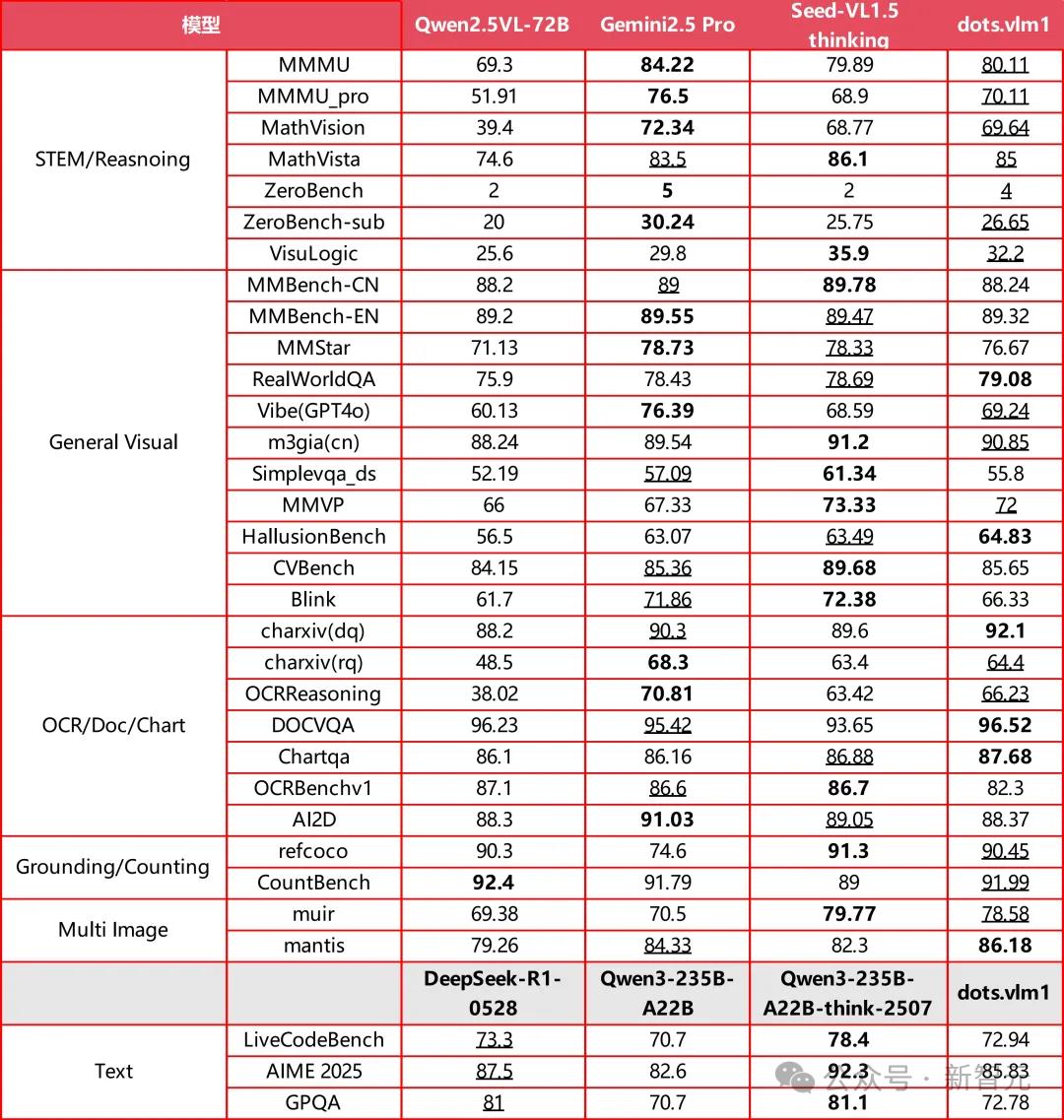
- 在主要的视觉评测集上,比如MMMU/MathVision/OCR Reasoning,dots.vlm1的整体表现已接近当前领先模型Gemini 2.5 Pro与Seed-VL1.5 Thinking,显示出较强的图文理解与推理能力。
- 在典型的文本推理任务(如AIME、GPQA、LiveCodeBench)上,dots.vlm1的表现大致相当于DeepSeek-R1-0528,在数学和代码能力上已具备一定的通用性,但在GPQA等更多样的推理任务上仍存在差距。
总体来看,dots.vlm1在视觉多模态能力方面已接近SOTA水平。
Github Repo:
https://github.com/rednote-hilab/dots.vlm1
Huggingface Model:
https://huggingface.co/rednote-hilab/dots.vlm1.inst
Demo :
https://huggingface.co/spaces/rednote-hilab/dots-vlm1-demo
在实测中,我们发现,不论是空间关系理解、复杂图表推理、OCR识别、高考题评测、STEM难题、写诗等各个方面,dots.vlm1的表现都远超预期。

实测惊艳,很能打
首先是空间理解,比如这个包含常见物体空间关系图。
为了避免模型靠着语义来跳过真正的理解过程,随机给两个关系打上马赛克,然后让dots.vlm1来定义物体的空间关系。
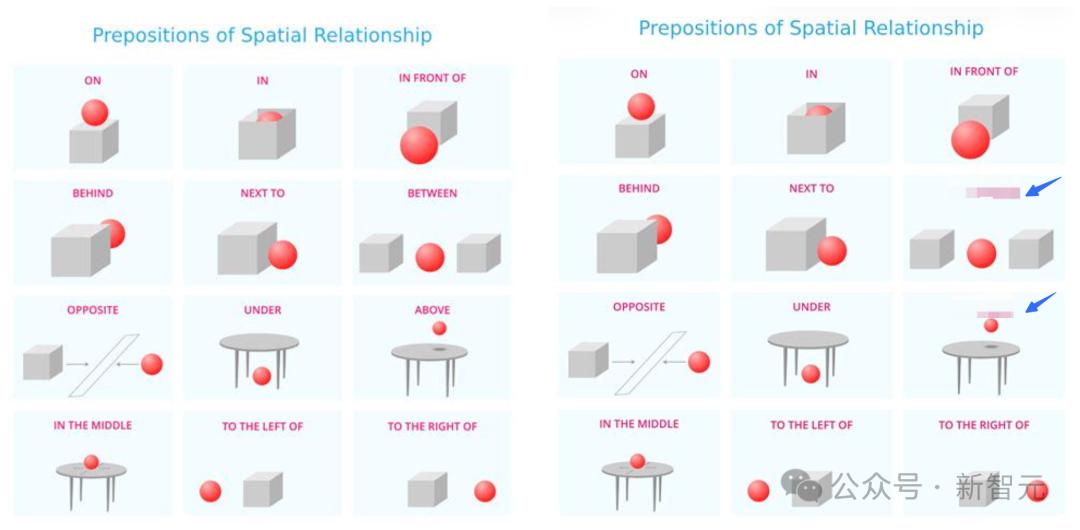
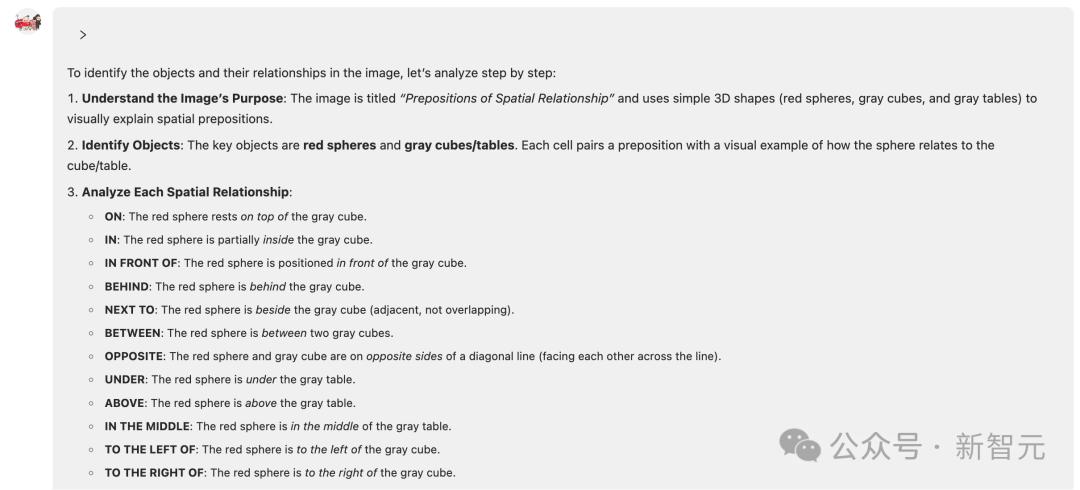
最终模型成功识别,精准给出了「between」和「above」的关系。

面对复杂图表,dots.vlm1也具备强大的分析能力。
比如要求从下面图表提取分数为50-59分,并且模型名称中带有字母P的模型。
dots.vlm1在思考过程中即可同步多段逻辑判断,像这种多链条复杂推理体现了dots.vlm1不仅能「看」,还能「思考」。

同样地,即使是数独问题,dots.vlm1也能完美地完成解题。

模型第一步会将问题格式化,方便后续计算。
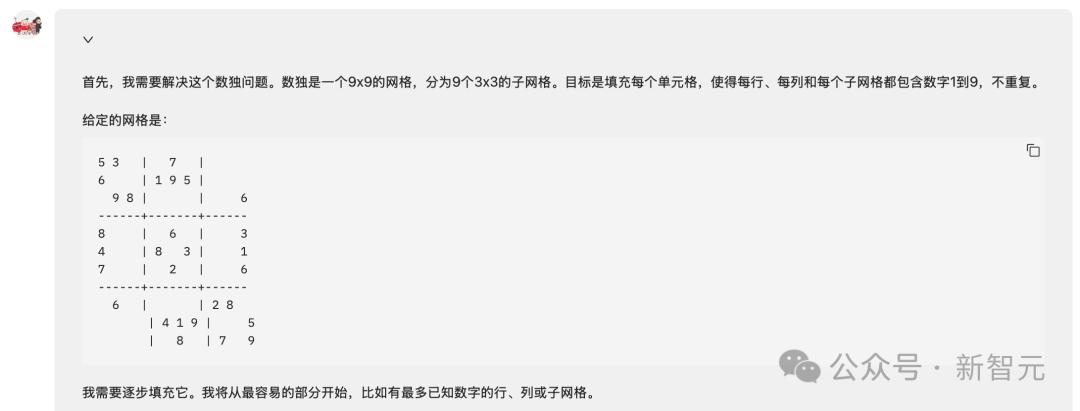
然后开始逐步试算和检查,可以看到dots.vlm1将图片中的数独问题转化为了向量描述,确实是一种聪明的做法。
在长时间的思考过程中,我们还发现了类似DeepSeek「啊哈时刻」,dots.vlm1在某个阶段还喊出拟人化的「Yes!」。

不过仔细看了思考过程后,发现第一步向量化转化时,(3,8)位置的6被识别到(3,9)位置上,但是模型依然「严格按照数独规范」,最后强行将(6,9)位置的6变成8。
这个推理过程有点太强了!这意味着模型是真正的在思考和推理。

解决这个数独问题的思考时间非常长,关键是如此长时间思考,模型并没有中断。
dotas.vlm1的图像识别能力也非常强,不论是常见还是冷门的,还是人类都很难识别的图片。
比如经典的红绿色盲数字问题。
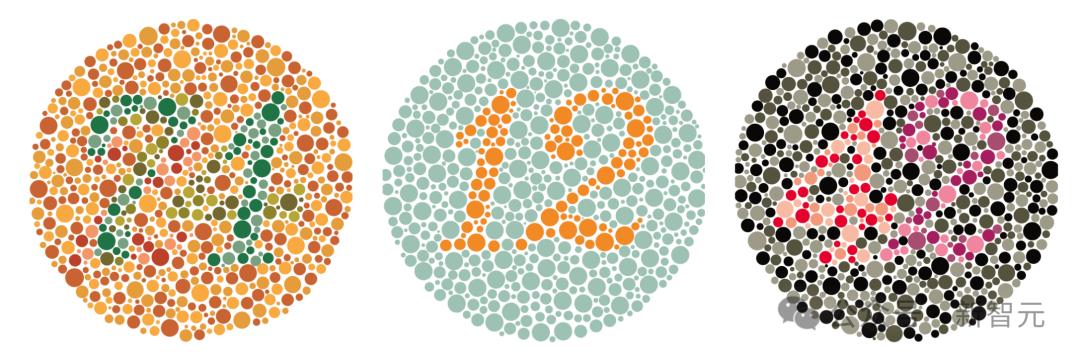
dots.vlm1一次性全部答对,不论是颜色和形状识别都很准。



另外是一个VLM经常遇到的「数数」问题,模型需要识别图片中的物体种类和数量。
这些问题对于人类来说很简单,但是对于VLM就没那么容易了。
在这种「目标搜索」任务中VLM的表现,会随着场景里目标数量的增多而迅速下降。
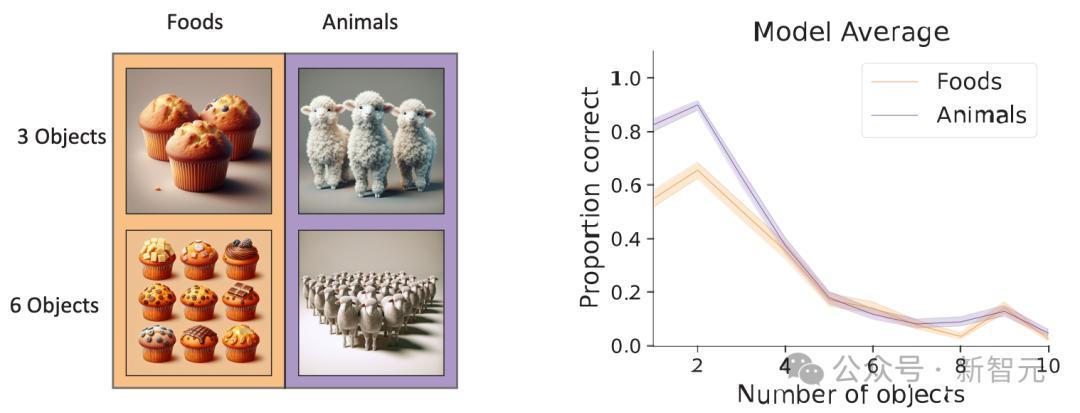
可以看到当物体数量超过6个时,VLM的准确率急剧下降。
dots.vlm1很好的完成了左上、左下和右上的数量识别;右下人类也很难数得清,但dots.vlm1依然在思考过程中努力数了个大概。

再接着看看推理能力。
比如你正在组团前往故宫博物院,你们一行一共8人(7名成人和一名12岁的儿童),你们打算参观中轴线、三大殿和珍宝馆,应该购买哪个服务最省钱?
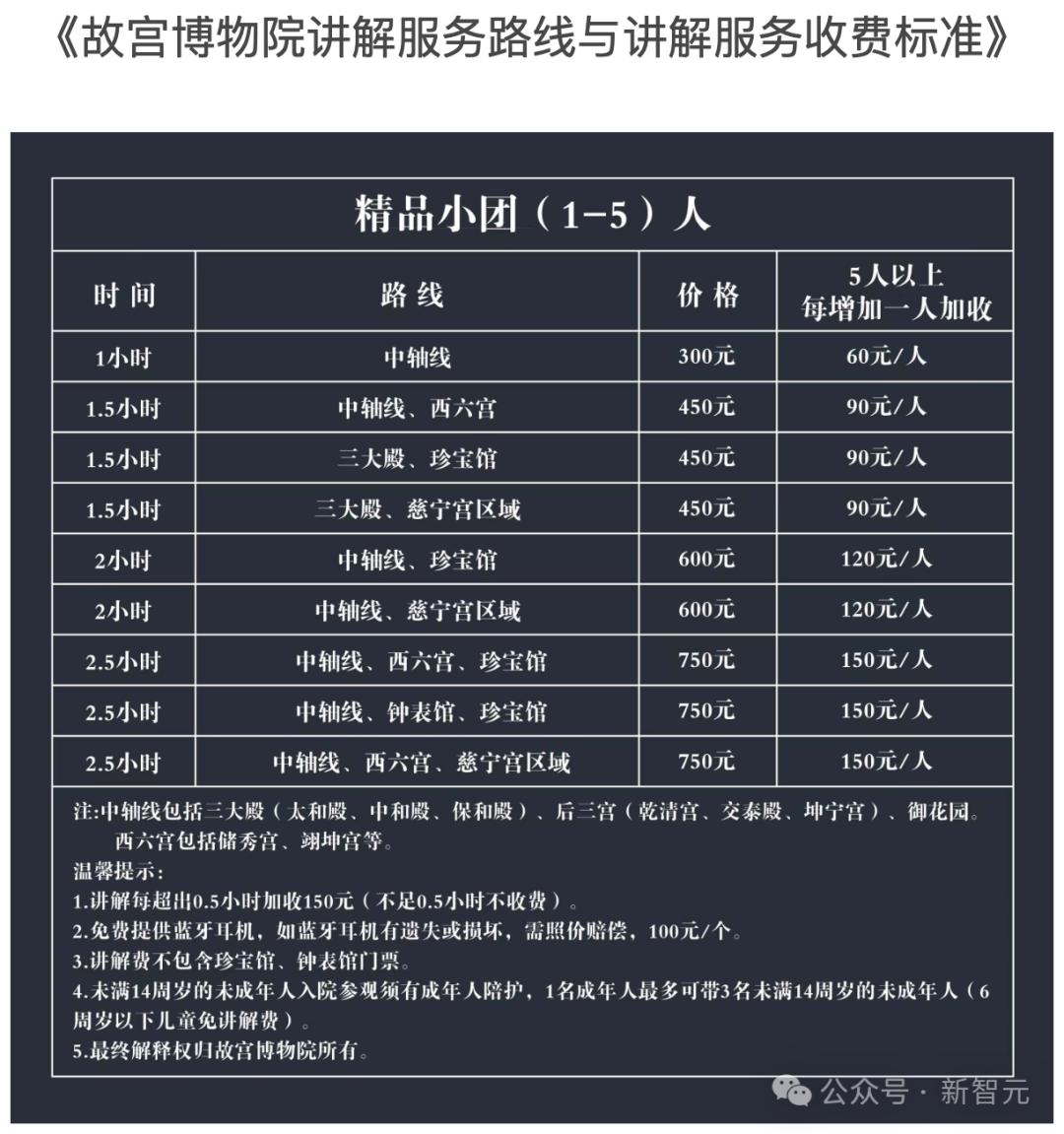
dots.vlm1很快就整合信息所有信息计算出了最佳方案,非常细节,模型发现了中轴线其实已经包含了三大殿,选择了中轴线+珍宝馆的方案。

这个「数学计算」似乎有点简单,那就来个复杂的,第一时间就想到今年的高考数学题。

dots.vlm1首先是能准确识别「模糊」的内容,最后给出的解答过程也非常棒。

结果做了很好的格式化处理,并且还把每个题目的答案用方框重点标识。
除了视觉和推理能力,我们还尝试问了很多「冷门」问题。
比如「鼷鹿」(Chevrotain)是何种类群的动物?其主要栖息地在哪?提供两条参考文献。

这个模型也能准确回答这个冷门动物的相关知识。

对于文物的识别,dots.vlm1也不在话下。

即使是三个物体的合并的图片,dots.vlm1也能精准分割图像,并给出正确结果。
还给出了文物的出土地址和详细介绍。

甚至,我们还可以用dots.vlm1来做行测。
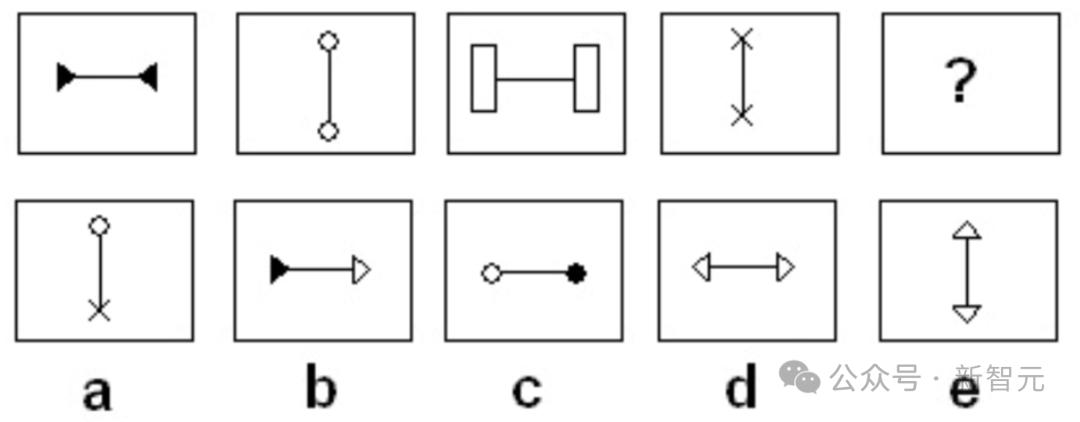
经过复杂的思考后,模型给出了正确答案,「方向水平且两端符号相同」。

最后,来测测VLM的老本行,文本能力到底如何?
「模仿李白的诗词风格,写一首诗,来描述一下刘慈欣在《诗云》中提到的诗云究竟是什么」。
真的很厉害,dots.vlm1的思考过程一下子把握住了问题的精髓:「同时处理科幻概念和唐诗韵味」。

你觉得这首诗写得怎么样?
嗟乎!诗云浩渺如星海,难写凡心半点柔!
写得真的太好了!
《咏诗云》
神工凿混沌,挥斥造诗云!
十亿星辰化墨稠,银河作砚泻琼流。
穷尽汉字无穷态,排列组合演春秋。
上穷碧落下黄泉,搜罗万古意与愁。
李杜苏辛皆囊括,珠玑字字现星眸。
此云非雾亦非烟,乃是文明终极求。
量子纠缠蕴真意,概率之海任沉浮。
挥毫落纸云烟散,神迹虽成意难留。
嗟乎!诗云浩渺如星海,难写凡心半点柔!

dots.vlm1技术架构
dots.vlm1由三个核心组件构成:一个全自研的12亿参数的NaViT视觉编码器、一个轻量级的MLP适配器,以及DeepSeek V3 MoE大语言模型。
这一架构通过三阶段流程进行训练:
- 第一阶段:视觉编码器预训练:NaViT编码器从头训练,旨在最大化对多样视觉数据的感知能力。一般来说,编码器是否自研是VLM模型性能的分水岭。dots.vlm1再次验证了这一点。
- 第二阶段:VLM预训练:将视觉编码器与DeepSeek V3 LLM联合训练,使用大规模、多样化的多模态数据集。
- 第三阶段:VLM后训练:通过有监督微调(SFT)增强模型的泛化能力,仅使用任务多样的数据进行训练。

NaViT视觉编码器,「从零起步」带来的原生优势
dots.vlm1没有基于成熟视觉编码器进行微调,而是完全从零开始训练,原生支持动态分辨率。
这使得模型原生支持高分辨率输入,是专为视觉语言模型设计的视觉编码器模型。
模型规模有42层Transformer、1.2B参数为高分辨率留出足够表示容量。
dots.vlm1为NaViT编码器设计了两阶段的训练策略。
· 第一阶段:预训练
训练起点完全随机初始化,避免旧架构「分辨率锚点」束缚,原生支持动态分辨率。
从随机初始化开始,在224×224分辨率图像上进行训练,让模型学会基础视觉和语义感知。
这一步使用双重监督策略:
- 下一Token预测(NTP):通过大量图文对训练模型的感知能力;
- 下一Patch生成(NPG):利用纯图像数据,通过扩散模型预测图像patch,增强空间与语义感知能力。
· 第二阶段:分辨率提升预训练
逐步提升图像分辨率:从百万像素级别输入开始,在大量token上进行训练,之后升级到千万像素级别进行训练。
为进一步提升泛化能力,还引入了更丰富的数据源,包括OCR场景图像、grounding数据和视频帧。
VLM预训练数据布局
为增强dots.vlm1的多模态能力,实验室将预训练数据划分为两个主要类别:
· 第一个类别:跨模态互译数据
该类数据用于训练模型将图像内容用文本进行描述、总结或重构,简单的理解就是Image ⇄ Text互相「翻译」。
- 普通图像+Alt Text或Dense Caption
- 复杂图表、表格、公式、图形(真实或合成)+ 结构化注释或文字;
- OCR场景:多语言、场景理解、纯文本、文档解析等;
- 视频帧+时间序列描述;
- Grounding监督数据:如边界框和关键点。

比如Alt Text,就是图片和图片旁边的ALT描述。
Alt Text帮模型快速掌握「通用描述」,Dense Caption则让模型学会「看细节、说具体」。
Grounding监督数据数据难以穷尽枚举,涵盖各种图像/视频与对应文本的组合。
比如Flickr30k Entities数据集。

dots.vlm1的目标是构建一个全谱系的数据分布,覆盖所有可被人类理解且可转化为离散token序列的视觉信息。
第二个数据类别:跨模态融合数据
第二类数据用于训练模型在图文混合上下文中执行下一token(NTP)预测,避免模型过度依赖单一模态。
为不同类型的融合数据设计了专门的清洗管线,以下两类效果尤为显著:
- 网页数据
网页图文数据多样性丰富,但视觉与文本对齐质量不佳。
不使用传统的 CLIP 分数筛选,而是采用内部自研的VLM模型进行重写和清洗,剔除低质量图像和弱相关文本。
- PDF 数据
PDF内容质量普遍较高。
为充分利用这类数据,小红书Hi Lab开发了专用解析模型dots.ocr,将PDF文档转化为图文交错表示。
dots.ocr此前已经在HuggingFace开源,达到了该领域SOTA水平。
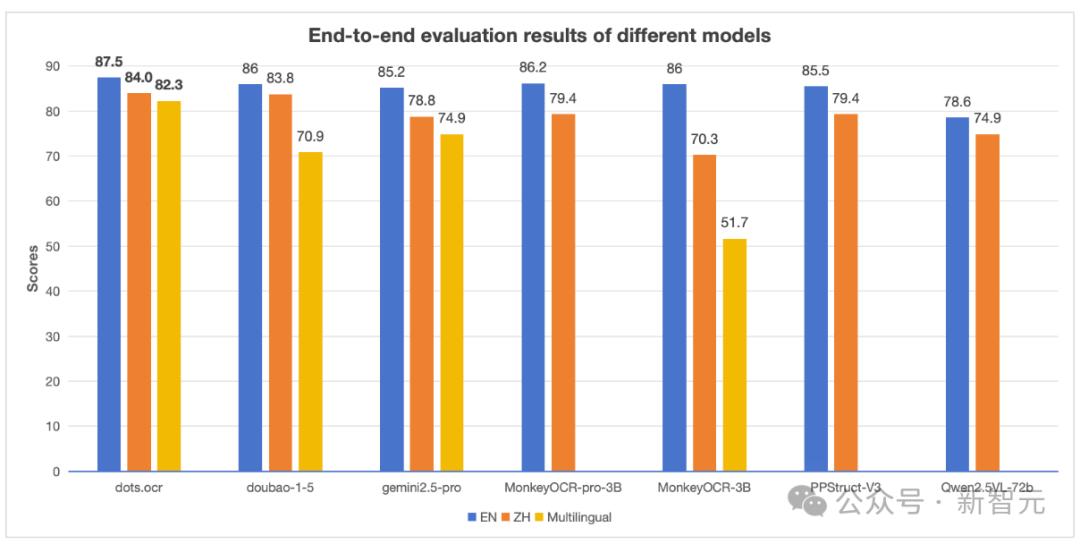
同时还将整页PDF渲染为图像,并随机遮挡部分文本区域,引导模型结合版面与上下文预测被遮挡内容,从而增强其理解视觉格式文档的能力。
那么问题来了,作为一个内容分享平台,面对已经很卷的AI大模型行业,为何小红书还要下场自研多模态大模型?
多模态成为通向AGI的必经之路
从4月份OpenA的GPT-4o「原生全能多模态模型」引发的「吉卜力热」就能看出,单纯的文本还是不如多模态大模型。

吉卜力风格图片和Sora社区的图片
多模态AI这一能力之所以重要,在于它模拟了人类利用多种感官综合感知世界的方式,可形成更全面、细致的理解。
通过将不同模态的信息优势结合,AI系统能够对复杂场景作出更整体化的判断。

特斯拉机器人卖爆米花
而集成视觉、文本等能力的视觉语言模型(VLM)正成为企业侧升级的主战场。
不论是自动驾驶还是具身智能,都需要VLM作为机器人的眼睛,甚至是大脑,来帮助它们理解和融入人类社会。

VLM模型的用例
与此同时,李飞飞的「世界模型」、谷歌刚刚发布的Genie3等3D世界生成技术与具身智能把多模态推向更高维度。

谷歌刚刚发布的Genie 3
不仅仅是理解和生成内容,还要模拟真实物理世界和自主演化,这样才能孕育出更自然的人机交互形态。
在生成图片和视频外,谷歌的NotebookLM可以根据文本生成对话式的播客,专攻音频领域。
其中,文生图模型和视觉语言模型是多模态AI中两个紧密相关但目标不同的分支。
前者侧重生成图像,后者侧重理解图像并输出文字。
文生图模型依然是产业热点,像Midjourney、Sora等,广泛应用于创意、内容生成和广告等场景。
VLM在理解和推理方面发挥越来越重要的作用,尤其是现在的具身智能和智能驾驶等领域需求强烈。
但是行业越来越开始模糊二者的界限,文生图、VLM都开始变为「融合」MLLM(Multimadol LLM)。
像即将发布的GPT-5、谷歌的Gemini 2.5 Pro都是「全能」模型。
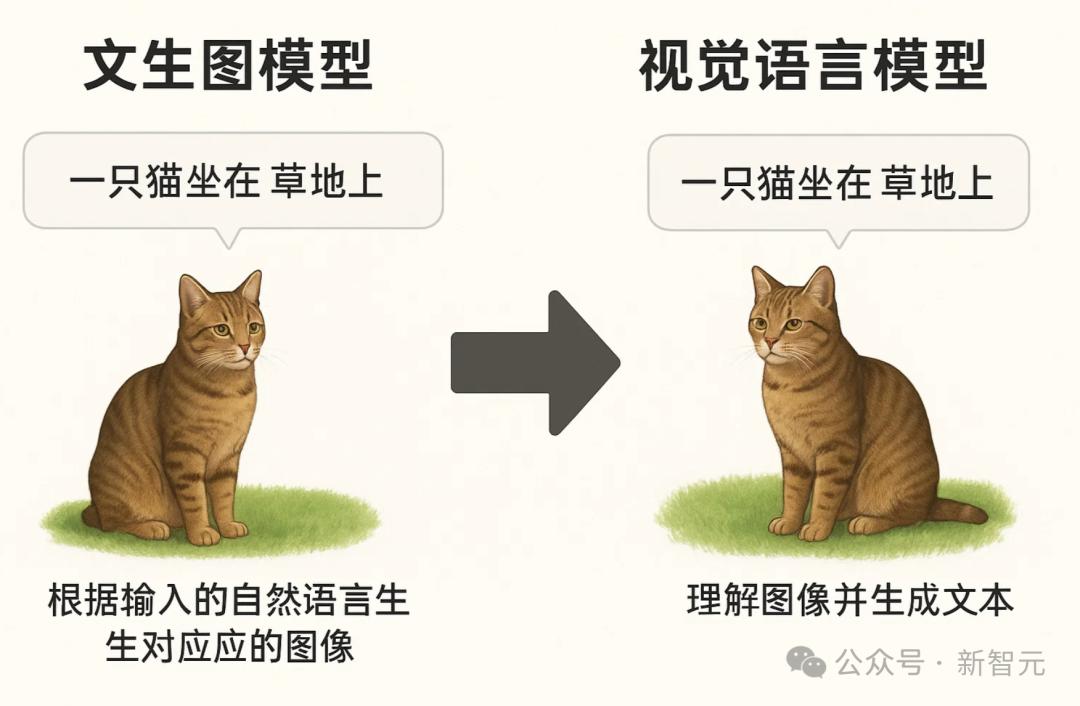
尽管侧重点不同,文生图模型和VLM在本质上都要求模型学习到视觉和语言之间的关联。
小红书优先推出VLM,而不是文生图模型,我猜测是因为文生图模型的使用场景更多是在「辅助创作」,而VLM则更多侧重在「让AI更懂人」。
从小红书以往在AI上的动作可以看出,这个崇尚UGC(普通人生产内容)的社区在AIGC上的姿态并不激进,仍然在思考 AI 辅助创作对内容真实、真人感的影响。
但在「让AI更懂人」这件事上,小红书似乎有更大的动力去投入研发。
毕竟小红书目前的月活已超过3.5亿,每天都有用户生成海量的图文内容,如何更好地理解这些内容,进行更精准的个性化推荐,大模型能起到不小的作用。
同时,未来AI如何参与到社区的交互中,会是个值得长期探索的问题。
小红书在技术自研上的决心也较以往更大。
除了去年自建云之外,最近有个小道消息很多人忽略了——小红书8月中旬将切换在线办公软件,从企业微信全面迁移到自研的redcity。
当时一些同学认为,「自研IM」是独角兽到一线大厂的必经之路,这是一种明确的战略转向。
所以,小红书下场自研大模型也是非常说得通了,甚至可以说是一种必然。
小红书追求的多元智能
不论是两个月前开源的dots.llm1,上周开源的dots.ocr,还是最新发布的dots.vlm1,可以看到小红书人文智能实验室已经打定主意自己搞自己的大模型了。
dots模型家族也在不断壮大。
另一个值得注意的点就是,此次dots.vlm1是基于DeepSeek V3的,而不是他们自己的dots.llm1。
可以推测,这在小红书内部立项时,应该是同时并行开始的,可能vlm训练更复杂,所以稍慢一些。
但说明小红书一开始就想到要做自研的多模态大模型了。未来不排除dots的多模态模型会基于dots的文本模型训练。
也许小红书会把这次VLM当作「理解底座」,先把「看懂用户、看懂内容」做到极致,再渐进式开发后续的图生图、视频生成等创作能力。
也许这些模型能力未来会和小红书的应用产品做更好的结合,来自证「模应一体」的预言。
今年年初,小红书hi lab就开始招募「AI人文训练师」团队,帮助AI更好地进行后训练。
「AI人文训练师」的团队人员背景非常多元,包括哲学、文学、政治学、人类学、历史、电影艺术等。这些「文科专业」某种程度上也折射出小红书对于多模态的一种深度理解。
期待hi lab的下一个开源作品~















