


鱼羊 西风 发自 凹非寺
量子位 | 公众号 QbitAI
听说了吗,GPT-5这两天那叫一个疯狂造势,奥特曼怕不是真有些急了(doge)。

但有一说一,回顾上半年最火AI事件,GPT-4o带来的“吉卜力”风暴,还是热度TOP。
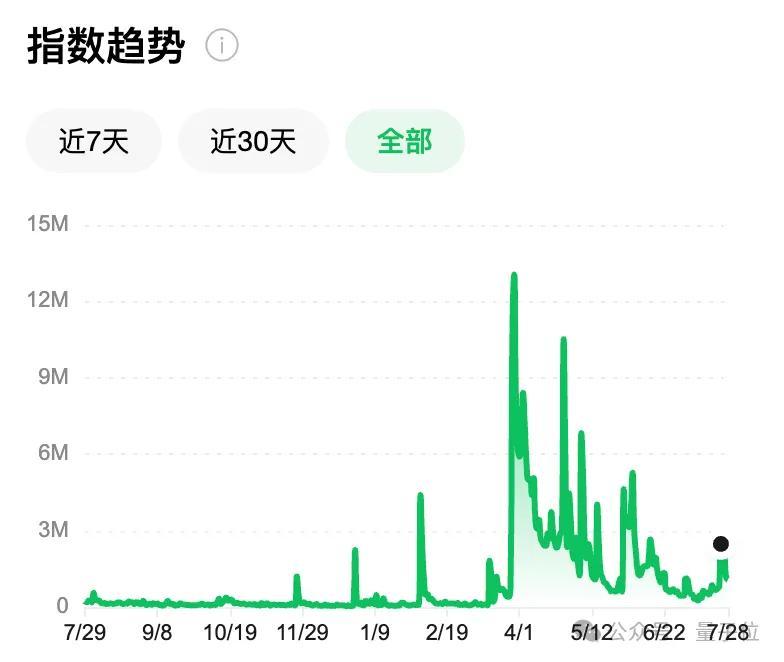
△数据来自微信指数
不仅由“万物皆可吉卜力”为始,GPT-4o生图功能被网友们疯玩至今,更重要的是,还引发了更深的技术思考:
AIGC的范式,已经被悄然改变。
从割裂地处理文本、图像、声音,到现在,大众在应用领域的反馈已经证明,AI需要以更接近人类认知的方式,融合多模态信息。
新的技术趋势值得关注,也有人第一时间开源了对新范式的深入思考:
昆仑万维已开源多模态统一模型Skywork UniPic,和GPT-4o呈现出类似的图像一体化能力,在单一模型里实现图像理解、文本到图像生成、图像编辑三大核心能力的深度融合。
对生图提示词的理解力,是这样的:

提示词:两位寿司师傅在江户时代熙攘的街市投掷彩虹寿司。他们头顶的纸灯笼明灭闪烁。整个场景呈现出像素化的复古游戏画风。
把图片转换成吉卜力风格,也很有内味儿:

并且相比狂卷大参数量的同类模型,Skywork UniPic主打一个高“性能密度”:
1.5B参数模型效果就能接近甚至超越十几亿参数专用模型,可以在消费级显卡上流畅运行。
开源还很全套:
完整模型权重、详细技术报告、配套全流程代码,通通开源。
想要学习借鉴增长姿势知识的小伙伴,值得马克一波。
1.5B模型效果逼近大型专用模型
一句话总结一下Skywork UniPic的模型特点,就是既可以像视觉模型(VLM)一样理解图像,也可以像扩散模型一样生成图片,用户还只需“动动嘴”,就可以指导模型完成图像编辑。
在不同任务上,1.5B的Skywork UniPic都有不错的指令理解和生成效果。
比如文本到图像生成:
修女的铅笔肖像画

一幅身着丝绒长裙的贵妇人油画

图像编辑方面,换个背景:

调整表情:

换个风格:

效果上看都不逊色于一些商业闭源模型。
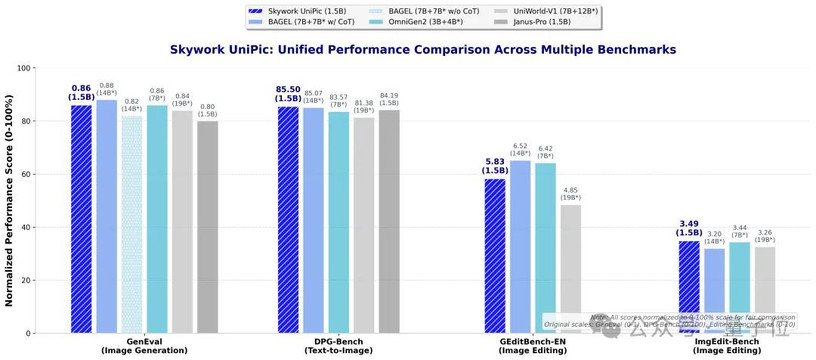
更定量地来看,Skywork UniPic以1.5B的紧凑参数规模,在四大核心评估维度上均展现出了卓越表现。
在GenEval指令遵循评估中,Skywork UniPic取得0.86的优异成绩,超越了绝大多数同类统一模型,在无CoT的情况下取得了SOTA分数,逼近较大模型BAGEL(7B+7B*)带CoT的0.88分。
在DPG-Bench复杂指令生图基准上,Skywork UniPic达到85.5分的行业SOTA水平,与14B参数的BAGEL(85.07分)不相上下。
在图像编辑能力方面,Skywork UniPic在GEditBench-EN获得5.83分,ImgEdit-Bench达到3.49分,展现出一定的编辑执行能力。
值得一提的是,1.5B的参数量,使得Skywork UniPic可以在RTX 4090这样的消费级显卡上流畅运行,提供了一套真正可落地的统一模型解决方案。
技术细节大揭秘
而Skywork UniPic具体是如何做到,昆仑万维此次也给出了非常详细的技术报告。
自回归模型架构
首先在架构方面,Skywork UniPic采用自回归模型(Autoregressive Model)架构,这是其实现多模态统一能力的核心技术基础,与GPT-4o的技术路线一脉相承,显著区别于主流的扩散模型(Diffusion Model)。
该架构的核心优势在于将图像生成深度整合到多模态框架中,而非作为一个独立模块存在,从而能让图像理解、文本到图像生成、图像编辑三大核心能力在单一模型中实现完美融合。

△文生图prompt:一只纹理鲜明的绿色鬣蜥静卧在饱经风霜的树干上,倚靠着一堵幽暗墙壁。
整体框架借鉴了Harmon的设计思路,在表征方式和结构上做出关键调整——
采用解耦的视觉编码器设计,分别用于不同路径:
- 图像生成路径采用MAR编码器作为视觉表征基础;
- 图像理解路径采用SigLIP2编码器作为主干。
MAR编码器与SigLIP2都天然契合自回归的统一训练范式,有助于实现跨任务、跨模态的一体化建模。

MAR(Autoregressive Image Generation without Vector Quantization)本身具有连续空间自回归的特性,通过采用Diffusion Loss替代传统的VQ离散化处理,天然具备高质量图像生成、低延迟响应以及自回归可控的优势。MAR编码器还展现了极强的语义理解能力,linear probing精度出色,能有效支持图像概念抽取。
此外,昆仑万维Skywork天工大模型团队,通过大规模预训练对模型进行升级:
基于亿级高质量图像-文本对进行独立预训练,使其从单纯的“图像生成”能力,跃升为兼具“高质量生成”与“强大语义表征”的综合视觉基座,能够有效支持图像概念的精准抽取。
通过这一自回归框架的构建,Skywork UniPic成功实现了:
- 图像与文本的统一表征学习
- 跨模态的上下文理解与推理
- 生成与编辑的端到端流程优化
精炼高质量数据体系
另外值得一提的是,Skywork UniPic的卓越性能并非依赖于海量数据的简单堆砌,而是源于一套高度精炼、系统优化的高质量数据构建体系。
团队突破了“数据量越大模型性能越强”的传统认知,通过亿级精选预训练语料与数百万级任务精调(SFT)样本,构建了一套面向图像理解、文本到图像生成与图像编辑三大核心任务的高效能多模态训练语料库。
该数据体系在数量上远低于当前行业内普遍依赖的数亿至百亿级数据规模,却实现了与主流大模型相当的性能表现,充分验证了高质量小规模数据训练多模态模型的可行性与高效性。
在数据构建阶段,团队实施了三大关键优化策略,以“提纯”为核心目标:
- 严格控制任务类型的均衡分布,确保模型在各领域的泛化能力;
- 精心设计多样化的指令模板,覆盖不同应用场景的表达需求;
- 建立多层质检机制,包括自动过滤、人工复核和交叉验证,保证数据纯净度。
这种精细化的数据管理方法不仅显著提升了数据的利用效率,降低了训练资源消耗,更促进了模型在跨模态任务中的知识迁移与协同学习能力。
自研专用奖励模型
数据质量如何把控,官方技术报告中也给出了详细说明。
为确保Skywork UniPic在图像生成与编辑任务中性能卓越,昆仑万维天工大模型团队意识到高质量训练数据的关键作用。
为此,研究团队针对性设计了两套专用奖励模型,构建起覆盖生成与编辑数据质量的智能评估体系。
其一,是专用图像生成Reward Model。
Skywork-ImgReward是基于强化学习训练的Reward Model,相比于其他T2I Reward Model,Skywork-ImgReward在多个文生图场景下的偏好选择表现都更接近人类偏好。它不仅被用来作为文生图数据质量的筛选,也可以在后续被用于图像生成能力强化学习训练中的奖励信号,以及作为生成图像的质量评估指标。

△文生图prompt:一幅老式厨房场景,铸铁水壶与陶瓷茶壶置于粗削木桌上。
其二,是专用图像编辑Reward Model。
面对图像编辑这一核心挑战,团队创新性地构建了具有针对性的Skywork-EditReward,其被用作数据质量评估时可以自动剔除超过30%的低质量编辑样本,在GEditBench-EN和ImgEdit-Bench基准测试中表现明显改善。后续同样也可以被用作图像编辑强化学习训练中的奖励信号,以及作为图像编辑的质量评估指标。
经其筛选数据训练的Skywork UniPic,编辑性能明显改善,充分验证了对编辑任务的强效赋能。
例如,当指令要求“Remove the birds from the image.(将图中的鸟移除)”时,即便鸟横跨草甸、湖面、石头等多个区域,Skywork UniPic仍能精准移除。对于湖面被遮挡的倒影,模型也能依据场景的光影逻辑与物体关联性,进行自然且连贯的补全,最终呈现出毫无编辑痕迹的画面效果。

渐进式多任务训练策略
接下来,训练策略方面,Skywork UniPic是如何让模型在图像理解能力、图像生成质量与图像编辑精度这三大核心任务上实现均衡发展,避免出现“一强两弱”或“全而不精”的局面?
Skywork UniPic团队的做法是:创新性引入渐进式多任务训练机制,并结合了MAR训练优化体系与Harmon训练优化体系的精髓,实现了模型能力的有序、高效提升。
1、MAR训练优化体系
基于ImageNet-1M训练的MAR基线模型存在表征能力弱、语义层次浅的问题,百万级数据限制了视觉特征泛化能力,256×256低分辨率输入制约细节建模。
为此,团队采取两项关键优化:
- 数据层面引入覆盖更广场景与类别的亿级专有图像数据,拓展学习空间;
- 训练中采用渐进式分辨率提升策略,先在256×256下建立稳定底层特征抽取能力,再逐步迁移至512×512,增强语义理解与细粒度建模能力。
2、Harmon训练优化体系
为进一步提升性能并兼顾效率,团队设计多阶段分层分辨率训练:
第一阶段在512×512分辨率下微调,聚焦基础特征提取的稳定性与收敛性;随后逐步提升至1024×1024,强化对纹理、边缘等高精度细节的捕捉。
同时采用分阶段参数解冻策略,初始阶段仅训练Projector模块以对齐视觉与语言特征,冻结主干网络和LLM参数;接着在保持LLM编码器冻结的前提下优化视觉主干;最终全量解冻,进行端到端联合优化,实现多模态协同增强。
3、渐进式多任务训练策略
为解决理解、生成和编辑三类任务难以兼得的问题,团队提出渐进式多任务训练机制。
训练初期聚焦单一任务(如文本到图像生成),待其稳定收敛后,再按难度递增顺序引入理解与编辑任务,避免早期任务间的相互干扰。
精细化调优阶段,通过奖励模型筛选构建高质量训练数据,结合动态阈值与多样性采样策略,确保样本既具备高置信度,又覆盖丰富的语义场景。
整体而言,这些策略在训练过程中实现了能力的有序释放与任务的逐步适配,显著提升了模型在理解、生成和编辑任务上的综合表现,真正达成“一专多能”的效果。

为什么原生多模态统一模型值得关注
说回到技术趋势上,原生多模态统一模型,本身正在受到技术圈越来越多的关注。
为什么原生多模态统一模型如此受研究者们重视?
首先,在落地层面上,GPT-4o“吉卜力风”的成功出圈已经证明,相比于割裂的视觉大模型(VLM)的“读图”、扩散模型的“生图”,真正在统一模型中集成“看图”+“生图”+“改图”等全能多模态能力,才更能切实满足用户的使用体验。
简而言之,就是把多模态AI的使用门槛给打下来了,真的人人可用了。
其次,在技术层面上,原生多模态统一模型把跨模态表征、上下文推理、内容生成全部锁进同一组参数,带来了“一次训练,处处生效”的范式升级,为AIGC从“拼规模”走向“拼效率、拼体验”指明了发展方向。
Skywork UniPic就证明了,高质量小数据+统一自回归框架,也能逼近甚至超越大型专用模型的性能极限。
在这个技术方向上,好消息是,像昆仑万维这样全面开放核心资源,一方面,技术社区能够在开放的氛围里持续推动底层技术的演进。
另一方面,小而可靠的统一模型架构,代表了技术平民化的重要方向,也有助于开发者们探索AI应用的更多可能性。
值得一提的是,自2023年8月23日,昆仑万维发布国内第一款AI搜索产品“天工AI搜索”以来,其一直保持着持续开源的状态。
2023年10月,开源百亿级大语言模型“天工”Skywork-13B系列,并配套开源了600GB、150B Tokens的超大高质量开源中文数据集。
从2024年开始,又陆续开源数字智能体全流程研发工具包AgentStudio、“天工大模型3.0”4000亿参数MoE超级模型、2千亿稀疏大模型Skywork-MoE、Skywork-o1-Open等模型。
今年初,昆仑万维还一次性开源了两大视频模型——国内首个面向AI短剧创作的视频生成模型SkyReels-V1,和国内首个SOTA级别基于视频基座模型的表情动作可控算法SkyReels-A1。
可以说,从ChatGPT掀起大模型风暴以来,昆仑万维一直是国内重要的开源力量。也在中国开源越来越被世界关注的过程中,从基础模型,到音频,到视频,多模态全方位覆盖。
正如“吉卜力现象”的本质所示,是更易用的工具打开了普通人利用AI突破想象力边界的窗口,而昆仑万维这样的开源力量,正在推动着我们更快迎来创意大爆炸时代。
更令人期待的是,这一次,Made in China引领风潮。
模型权重:https://huggingface.co/Skywork/Skywork-UniPic-1.5B
技术报告:https://github.com/SkyworkAI/UniPic/blob/main/UNIPIC.pdf
代码仓库:https://github.com/SkyworkAI/UniPic
— 完 —
量子位 QbitAI · 头条号
关注我们,第一时间获知前沿科技动态签约
















