

机器之心报道
编辑:冷猫
如果你拥有了庞大的三维空间数据,你会用来做什么?
大模型时代之后,数据成了支撑模型的承重柱。能否获取足够的可用高质量数据,直接决定了某个领域的 AI 的发展上限。
而有了足够的数据,构建一个强大的大模型和生成模型,似乎总是水到渠成的事情。
想想看,视频生成模型里,可灵即梦等高质量模型,都是依托最大的视频内容 UGC 平台的海量数据而生的。这些数据自然也成为了模型进步最大优势。
数据可以用来训练模型,这些模型又可以进一步强化工具的能力,以此形成了数据飞轮,在三个环节(工具、数据、模型)相互循环。
在三维领域,数据一直是困扰人工智能对空间理解的长期问题。在昨天,我们应邀参加了「杭州六小龙」之一群核科技的首届 TechDay,看到了在室内空间设计领域的企业对于空间智能的思考。

我们想象的人工智能改变生活,都希望人工智能帮助我们打扫卫生做饭,我们可以吟诗作画。但现在反过来了,人工智能在吟诗作画,我们在那边打扫卫生。
要实现对人工智能改变生活的美好愿景,必须让人工智能从数字世界走向物理世界。
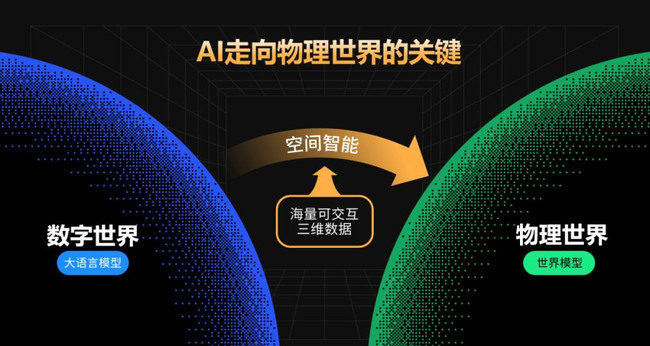
群核科技的联合创始人黄晓煌认为,「空间智能是非常关键的桥梁。」
首席科学家周子寒在演讲中提到:「群核空间大模型可以用这三个特点来描述,第一是真实感的全息漫游,第二是结构化可交互,第三是复杂的室内场景。」

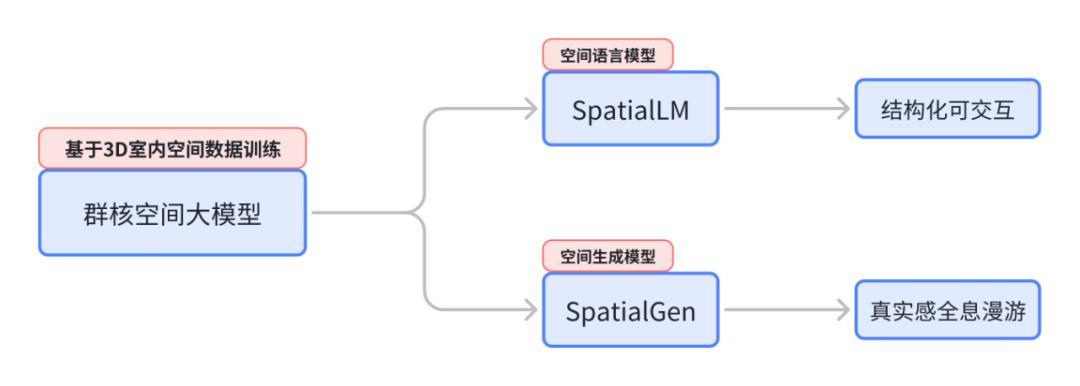
在这次的活动中,他们为空间智能发布了两个模型,一个空间语言模型和一个空间生成模型。
空间作为语言训练
大模型助力数据合成
大语言模型的最大优势就是语言的理解和输出,三维世界是否也能作为一门语言让大模型去学习呢?
今年 3 月的 SpatialLM 的空间理解模型,是基于大语言模型训练的。当输入一段视频时,模型能够提取这个视频当中的空间信息,用一段文本的形式将这个空间当中的物体方位和类别解释出来,在开源不久登上了 Hugging Face 趋势榜的前三名。
这一次 SpatialLM 1.5 有了一次巨大的飞跃,被称为空间语言模型。在采用 Qwen3 作为底层模型的基础上,叠加了 3D 空间描述语言能力构建增强型模型,使其既能理解自然语言,又能以类编程语言(如 Python)的结构化方式对室内场景进行理解、推理和编辑。
简单来说,就是大模型学会了空间语言。空间语言是一种结构化的语言,就像参数列一样,用数学的长、宽、高或 X、Y、Z 的方式去描述每一个物体在空间中的位置,描述物体类别,甚至可以从一个已有的素材库中找到对应的模型 ID,通过空间语言的描述就可以去获得整个场景的完整的 3D 信息。
空间语言模型 SpatialLM1.5 能力示意图
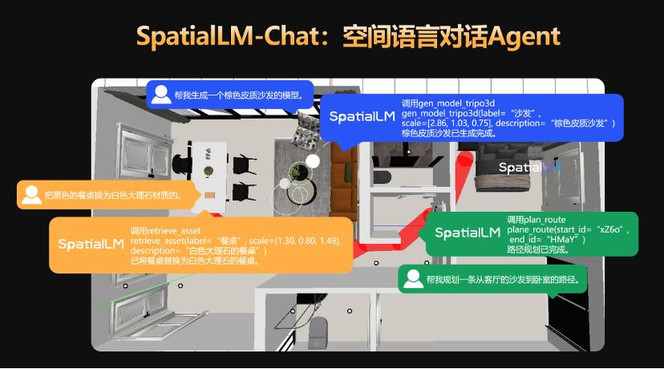
支持用户通过对话交互系统 SpatialLM-Chat 进行可交互场景的端到端生成。
例如,当用户输入简单文本描述时,SpatialLM 1.5 可自动生成结构化场景脚本,智能匹配家具模型并完成布局,并支持后续通过自然语言进行问答或编辑。
SpatialLM-Chat 演示
视频中展示了从户型图生成结构正确的房间信息,通过语言指令生成不同房间场景的家具,甚至完成移动路径的规划。
SpatialLM 1.5 生成的场景富含物理正确的结构化信息,且能快速批量输出大量符合要求的多样化场景,可用于机器人路径规划、避障训练、任务执行等场景,让具身智能的数据合成变的更加简单。
场景数据实现「时空一致」
3DGS 渲染沉浸视频
SpatialGen 生成场景渲染的漫游视频
在刚进入 TechDay 会场的时候,每个人都领了一张小卡片,在演示设备前刷下卡,就能看到对应的三维漫游场景。
在视频演示中,我们发现了明显的 3DGS 渲染特征,存在一些空间高斯点云的渲染模糊。但是,随着镜头的运动,这个三维场景表现出了惊人的「时空一致性」,并且随着镜头大范围的运动,3DGS 渲染常见的伪影、模糊、形变失真等现象也没有出现。
这一切都是由基于扩散模型架构的多视角图像生成模型 SpatialGen 来实现的。
如果说 SpatialLM 解决的是「理解与交互」问题,那么 SpatialGen 则专注于「生成与呈现」。
SpatialGen 依托群核科技海量室内 3D 场景数据与多视角扩散模型技术,其生成的多视角图像能确保同一物体在不同镜头下始终保持准确的空间属性和物理关系。

群核空间生成模型 SpatialGen 数据集情况
在实现细节方面,首席科学家周子寒在演讲中阐述了基本原理。其输入是场景的一张原图,以及场景布局图。输出则是相应场景的多视角图像,也可以进行深度图、语义图等其他类别的输出。
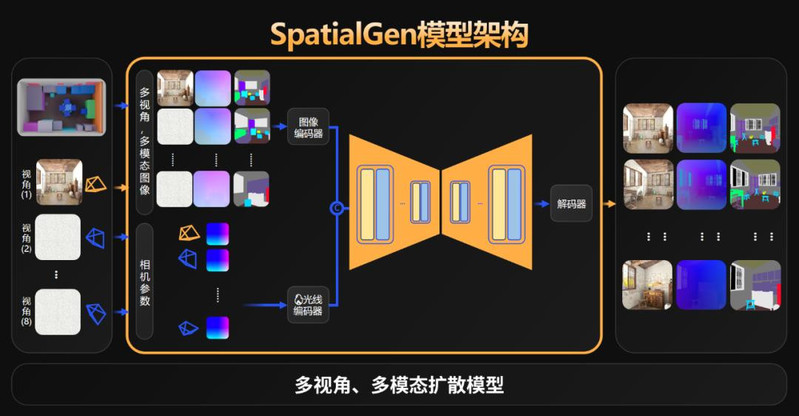
SpatialGen 模型架构
SpatialGen 可以生成任意视角图片,可以从一张图片生成八张图片,通过环形的视角的限定,它就会去尽量生成不同视角的图片,模拟相机在空间中的旋转。也可以基于这些图片再去生成更多图片,生成更多图片时可以用不同相机的约定的轨迹,这样就可以去生成更加复杂的运镜。
有了多视角图像结果,就可以通过一个开源的高斯重建的算法(AnySplat)重建高斯点云,随后可以进行视频的渲染,最终得到了一个漫游视频。
SpatialGen 的三大技术优势:
- 大规模、高质量训练数据集:由于开源 3D 场景数据稀缺,已有的工作在算法选择上受限,一般通过蒸馏 2D 生成模型,导致结果视觉真实性不足;基于群核数据集,能够设计并训练面向场景的多视角扩散模型(multi-view diffusion model)以生成高质量图像。
- 灵活视角选择:已有方法基于全景图生成还原,3D 场景完整性较差;或基于视频底模,无法支持相机运动控制等。
- 参数化布局可控生成:基于参数化布局生成,未来可支持更丰富的结构化场景信息控制。
针对 3DGS 的场景生成的问题,机器之心在技术交流会上与周子寒教授进行了一些技术上的交流:
机器之心:3DGS 生成领域中,传统的方法都是从图像生成的技术去入手做一个 3D 高斯生成,始终无法摆脱多视角生成图像的一致性问题。对于 SpatialGen 而言,使用了大量数据集,在多视角图像一致性上群核科技是否仍在用 Scaling Law 取得进步,在未来我们是不是有新的进步空间?
周子寒:对,现在的多视角的生成模型还是基于图像生成的,它之所以能呈现比较好的空间一致性,更多是依赖于我们在室内空间数据方面的优势,我们可以很高效地获取非常多的任意视角的图片进行训练,当你在训练了足够久的时间以后,未来我们可以继续去 scale up,空间一致性也会做得越来越好。
这里有一些与视频模型不同的点,我们一开始就不想让这样的一个模型受到时间轴的约束,而是让它在空间当中能随意跳跃。这种随意跳跃在工作流当中做任意的运镜视频的时候,会比纯视频模型,一定要从 A 到 B 的固定过程,要更加方便,这是一种新的视角,并不代表着新的技术路线。

当你去反复迭代使用时,这个东西显然不是无止境的,当你用了几轮以后,一致性一定会受到影响,我们相信 scaling law 一定会让它越做越好,但无法从根本上去消除这样的东西,就像你说的那样。
机器之心:如果依靠群核科技的三维数据集是否会有些进步,例如从文本直接到三维,而不经过二维图像的过程。
周子寒:我们有在探索这样一条路线,希望能将文本和 3DGS,或是 3D 表征直接去做一个连接,而不用中间的这一个多视角图像的东西。
目前来看,它有一个视觉效果与空间一致性的 trade off,如果用图像作为中间过程的视觉效果会好很多,如果直接从文本到 3D 的话,目前视觉效果稍微差了一点,这是在我们自己的过程当中(发现)的,这是两个不同的技术路线,在未来一定会有新突破。
开源方向的思考
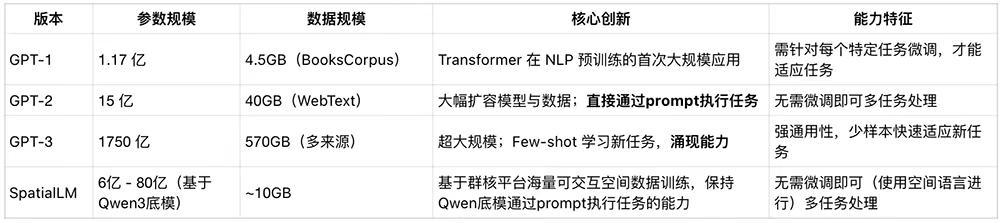
目前,在空间语言模型,从参数量而言仍处于 GPT-2 的阶段。虽然空间大模型能够弥补现有模型能力的很多缺陷,但空间大模型的 chatGPT 时代还远未到来。
群核科技联合创始人兼董事长黄晓煌表达了一个明确的观点:
「目前空间智能肯定还是在一个发展的初期阶段的,我觉得任何一家公司都不可能独享这个市场,所以我们在不断地开源数据、模型,我们希望跟全细节最聪明的大脑,全世界最有创新能力的人一起将这个 “蛋糕” 做大。」
在与周子寒教授的交流中,他也表示说:
「我们在设计的时候,刻意地让资产库与模型本身是解耦的,可以让这个模型去对接任何的资产库。这个东西跟群核自己的资产库并没有任何特定的绑定关系,这是为什么我们可以将整个系统做开源的原因,只要大家用任何的资产库都可以同样使用。」
SpatialGen 已面向全球开源,可在以下开源网站下载并部署使用:
- Hugging Face:https://huggingface.co/manycore-research/SpatialGen-1.0
- Github:https://github.com/manycore-research/SpatialGen
- 魔搭社区:https://modelscope.cn/models/manycore-research/SpatialGen-1.0
随着越来越多优秀的方法和高质量的数据集开源,不仅推动了不同 AI 领域的发展,也为研究社区带来了更多交流与碰撞的机会,催生新的灵感与突破,始终是一件令人振奋的事。















