
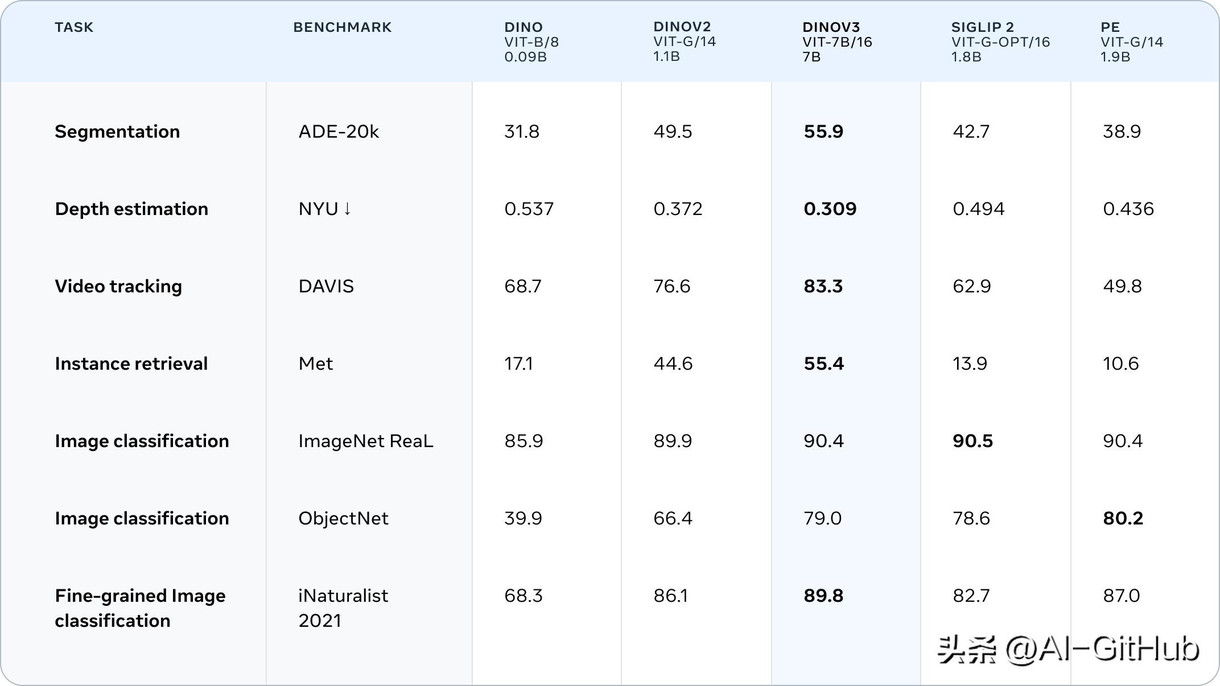
Meta 近日重磅推出并开源了新一代通用视觉基础模型 DINOv3,标志着自监督学习(SSL)在计算机视觉领域达到新的里程碑。

该模型不仅在多项核心任务上刷新记录,更成功弥补了前代模型在高分辨率密集特征处理上的短板。
核心功能:
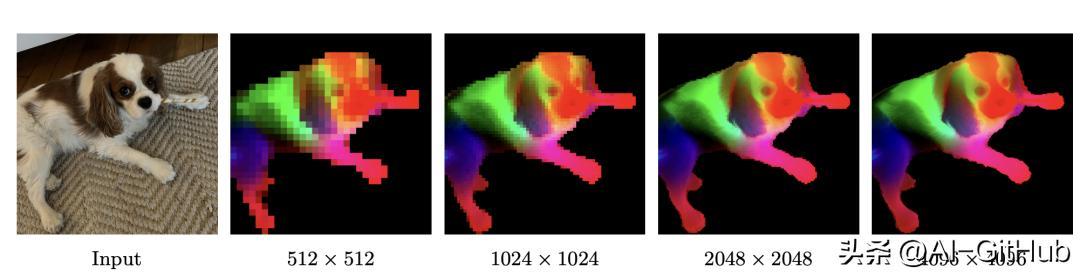
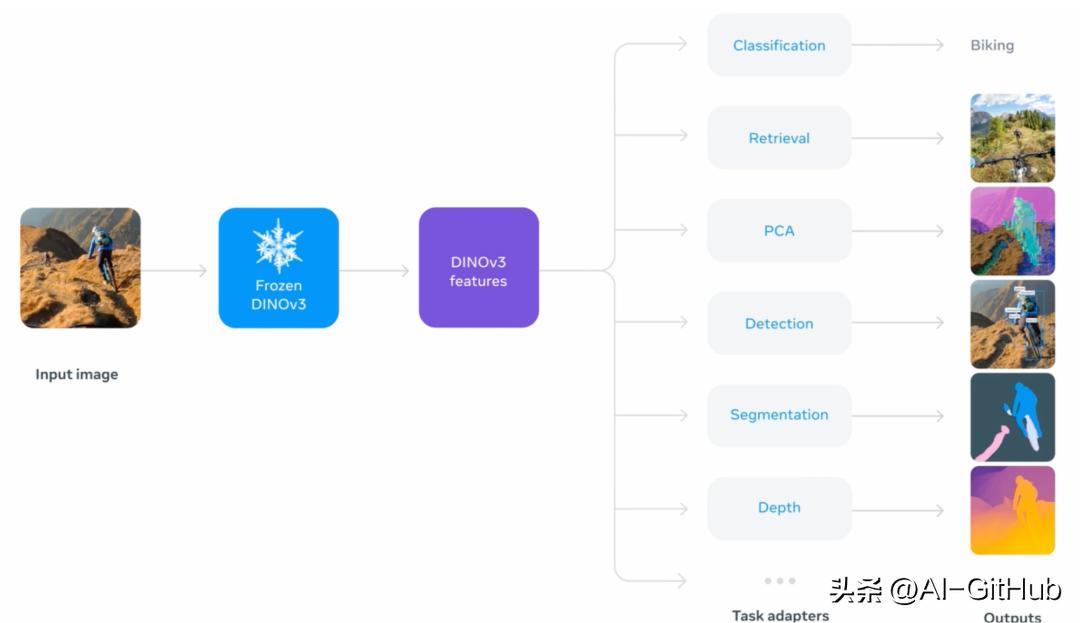
高分辨率视觉特征提取:生成高质量、高分辨率的视觉特征,支持精细的图像解析与多种视觉任务。

无需微调的多任务支持:单次前向传播可同时支持多个下游任务,无需微调,显著降低推理成本。
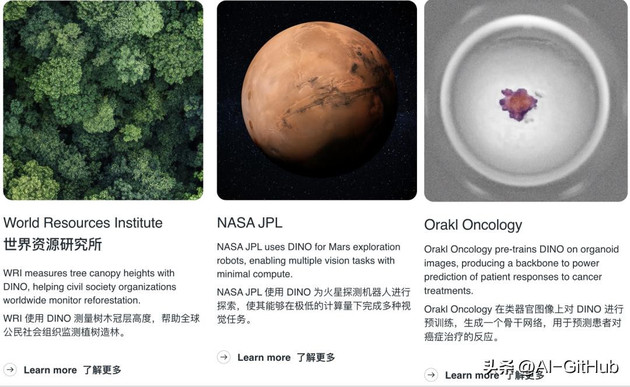
广泛的适用性:适用网络图像、卫星图像、医学影像等多领域,支持标注稀缺场景。
多样化的模型变体:提供多种模型变体(如ViT-B、ViT-L及ConvNeXt架构),适应不同计算资源需求。
技术创新
Gram锚定正则化方法:针对大模型长期训练中密集特征退化的难题,通过保持图像块(patch)间余弦相似度的结构,确保高分辨率下特征图的一致性和清晰度。
混合目标学习机制:结合全局DINO损失和局部iBOT损失,配合专用层归一化技术,提升训练稳定性和密集预测性能。

简化训练策略:采用恒定学习率与权重衰减,避免复杂超参数调度,大幅提升训练稳定性。
高效蒸馏框架:创新多学生并行蒸馏管道,允许同时训练多个学生模型并在所有训练节点共享教师推理,显著节省计算资源。
应用场景
森林监测突破:世界资源研究所应用DINOv3监测肯尼亚地区树冠高度,将平均误差从DINOv2的4.1米降至1.2米。

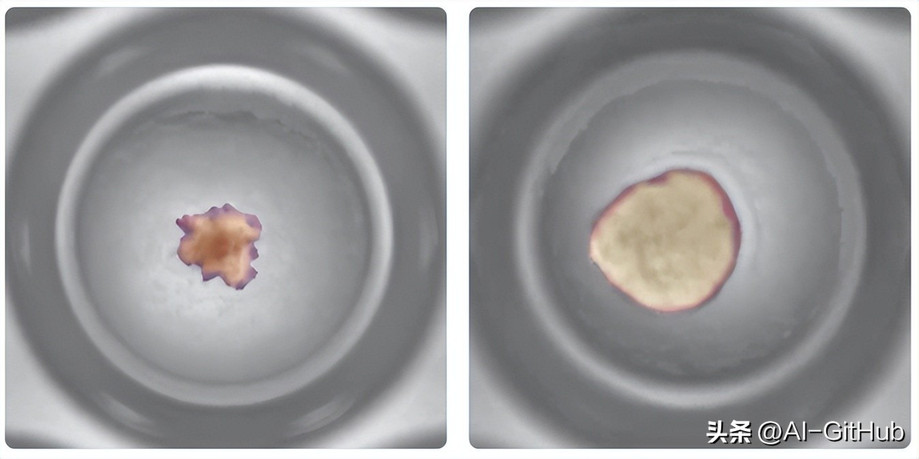
医疗影像分析:研究团队利用DINOv3对肺部CT图像进行高精度语义分割,实现病灶区域的精准识别。
卫星与航空影像: 用于自动化分析森林损失、土地利用变化(世界资源研究所 WRI 应用案例,将树冠高度测量误差从 DINOv2 的 4.1 米降至 1.2 米),助力环境监测、城市规划、灾害响应。

零售与物流:用在监控零售店铺的库存、顾客行为分析,及物流中心的货物识别和分类。
自动驾驶:凭借强大的目标检测和语义分割能力,帮助自动驾驶系统更准确地识别道路场景和障碍物。
项目官网:
https://ai.meta.com/dinov3/
GitHub:https://github.com/facebookresearch/dinov3
















