

编辑:LRST
【新智元导读】在AI浪潮席卷全球的2025年,大语言模型(LLM)已从单纯的聊天工具演变为能规划、决策的智能体。但问题来了:这些智能体一旦部署,就如「冻结的冰块」,难以适应瞬息万变的世界。试想,一个客服智能体面对突发的新产品政策时束手无策,或一个科研助手忽略了最新发表的算法——这样的场景,不仅低效,还可能酿成灾难。近期,格拉斯哥大学、剑桥大学、谢菲尔德大学、新加坡国立大学、UCL等机构的学者发布了最新综述,系统梳理了AI智能体自进化的核心框架与挑战,并为研究者提供了一套清晰可落地的研发路线图。
LLM驱动的AI智能体已展现出惊人潜力:它们以LLM为核心,集成感知模块(处理文本/图像/音频/视频)、规划模块(如链式思考CoT或树式思考ToT)、记忆模块(短期上下文存储与长期知识检索)和工具模块(调用API如搜索引擎或代码执行器)。
在单智能体系统中,这些组件协同工作,处理从网页导航、代码生成、投资辅助到生物医学分析的任务。而在多智能体系统(MAS)中,智能体间通过协作(如辩论或任务分解)攻克复杂问题,模拟人类团队的群体智能。
但问题显而易见:现有的智能体系统依赖专家的手工搭建,并且一旦被部署后就会始终维持固定的架构和功能。
一旦环境改变(如用户改变意图、出现新工具或者信息来源出现变化),手动重配置就成了瓶颈——耗时、费力、不具规模化。
论文直击这一痛点,引入「自进化AI智能体」(Self-Evolving AI Agents)的概念:这些系统通过与环境的持续交互并获得反馈,自主优化内部组件,目标是适应变化的任务、上下文和资源,同时确保安全、性能提升和自主性。

论文链接:https://arxiv.org/pdf/2508.07407
项目地址:https://github.com/EvoAgentX/EvoAgentX
研究人员强调,这不是科幻,而是从基础模型的静态能力向终身智能体系统的桥梁。
为了让进化有序,作者借鉴艾萨克·阿西莫夫的机器人三定律,创新提出「自进化AI智能体三定律」:
Endure(安全适应),任何修改必须保证系统安全与稳定。例如,医疗 AI 智能体在优化诊断模型时,绝不能降低对患者安全的保障。
Excel(性能保持),在安全前提下,必须保持或提升现有任务性能。不能为了适应新场景,导致核心功能(如客服的问题解决率)下降。
Evolve(自主进化),在前两定律基础上,自主优化内部组件以适应任务、环境或资源变化。例如,金融 AI 智能体需自主调整分析模型,应对市场突发波动。
这三定律如AI的「内在宪法」,分层设计(第二定律不能违背第一),确保进化不失控,而是有序推进。
值得一提的是,这篇综述已经冲上了Hugging Face Daily Paper热榜前三名,并且在X上和GPT5账号进行了神奇的联动:
看来即使是LLM也会被自进化这个话题所吸引呢。
该团队同时维护全球首个AI智能体自进化开源框架 ——EvoAgentX,旨在构建一个可信赖的 AI 智能体自进化生态体系。

从「固定工具」到「自主进化」
AI智能体四次范式飞跃
论文进一步描绘了LLM终身学习的范式,传统AI系统往往是 「一次性产品」:训练完成后就固定不变,面对动态环境时需要人工重新配置。
而自进化AI智能体的突破,在于构建了持续自我优化的闭环。
从早期静态预训练(MOP,Model Offline Pretraining),依赖大规模静态数据;
到在线适应(MOA,Model Online Adaptation),引入微调和RLHF;再到多智能体协调(MAO,Multi-Agent Orchestration),智能体间消息交换解决复杂任务;
最终抵达多智能体自进化(MASE,Multi-Agent Self-Evolving),智能体群体基于环境反馈和元奖励,持续精炼一切——从提示词到交互拓扑结构。
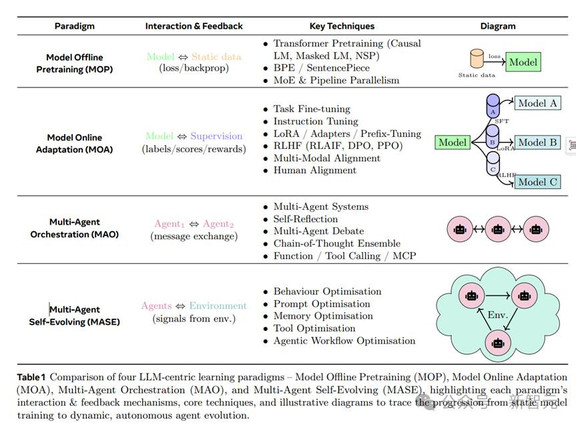
表1详细对比了四个范式:MOP的交互仅限于静态数据和损失函数;MASE则通过环境信号驱动行为优化、提示词优化等技术。这不仅仅是技术升级,更是范式革命——AI从「一次性训练」转向「终身学习」.
统一框架
自进化的「建筑蓝图」
论文提出的统一框架(图 3)揭示了自进化的底层逻辑,拆解为一个闭环迭代优化循环。
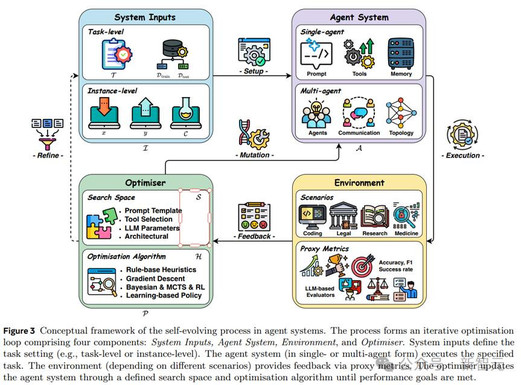
四大数据流环环相扣:
系统输入(System Inputs):包括任务描述、训练数据集或具体实例(如输入-输出对),定义优化边界。任务级优化针对整体性能,实例级则细化单个案例。
智能体系统(Agent System):核心执行者,可单智能体或多智能体形式,涵盖LLM、提示词、记忆、工具、工作流和通信机制。优化可针对单个组件(如提示词)或联合(如提示词+拓扑)。
环境(Environment):模拟真实世界,提供操作上下文和反馈信号——从量化指标(如准确率、F1分数、成功率)到LLM评估器生成的文本反馈。
优化器(Optimisers):大脑中枢,通过搜索空间(e.g.,提示词模板、工具选择)和优化算法(规则启发式、梯度下降、贝叶斯优化、MCTS、RL或进化策略)更新系统,寻找最佳配置。
例如,一个代码生成智能体的进化过程可能是:输入「提升 Python 代码调试效率」的任务→智能体尝试不同的工具调用策略→在真实代码环境中测试(环境)→优化器根据调试成功率调整策略→迭代升级。
从单智能体「修炼」到多智能体「协作」
基于框架,论文系统分类优化技术(见图2的视觉分类树,覆盖2023-2025年方法)

单智能体优化:聚焦个体提升
LLM行为优化:训练式如SFT(STaR自训练理性)和RL(Self-Rewarding自我奖励);测试时扩展如反馈导向(Baldur验证器)和搜索(Tree-of-Thoughts多路径探索)。
提示词优化:编辑式(GRIPS渐进式提示词)、生成式(OPRO零样本优化)、文本梯度式(TextGrad模拟梯度)和进化式(EvoPrompt遗传算法)。
记忆优化:短期记忆(如COMEDY动态总结历史)和长期记忆(如MemGPT RAG增强检索)。
工具优化:训练式(ToolLLM工具调用微调)和推理时(EASYTOOL工具链选择),甚至自主创建工具(如CREATOR生成新API)。
多智能体优化:从手动设计转向自进化
提示词优化:扩展到团队角色(如AutoAgents自动分配)。
拓扑优化:代码级工作流(AutoFlow动态流程)和通信图(GPTSwarm蜂群式交互)。
统一优化:基于代码(ADAS智能体设计空间)、基于搜索(EvoAgent进化智能体)和基于学习(MaAS多智能体自监督)。
LLM基座模型:推理导向训练(如Sirius规划增强)和协作导向(如COPPER通信协议优化)。
领域特定优化:在专业场景落地
医疗诊断智能体可整合多模态数据(如影像、病历),例如 MDTeamGPT 模拟多学科会诊,通过反思讨论提升诊断准确率;分子发现智能体通过工具调用(如化学模拟软件)设计新药分子。
编程:代码优化智能体能自主调试、重构代码,例如 Self-Debugging 通过执行轨迹反馈修正错误;多智能体协作(如 「程序员 - 测试员」 分工)提升开发效率。
金融与法律:金融智能体可结合市场动态与政策调整分析模型,法律智能体能模拟法庭辩论,通过对抗式进化提升推理严谨性。
看完这些案例,你会发现自进化不是空想,而是已经在多个行业开花结果,正悄悄改变AI攻克专业难题的方式。
安全与评估:自进化的「护栏」与「体检」
自进化的强大,也意味着更高的不可控风险。论文指出,在高自治度的智能体中,安全、合规与可信评估必须是「内建」的,而非「附加」的。
例如,AgentHarm 等基准测试揭示了模型在多轮交互中被引导执行恶意任务的可能性;R-Judge等方法则利用智能体充当评估者,对其他智能体的行为进行批判性审查。
这不仅关系到技术本身的稳定性,更是未来AI大规模落地的社会底线。
从「能跑」
到「跑得远、跑得好、还能自己升级」
自进化AI智能体的故事,才刚刚开始。虽然它们已经能在多个领域「上场打比赛」,但要实现真正的终身进化,还有不少硬骨头要啃。这些挑战可以用三个关键词概括:持久(Endure)、卓越(Excel)、进化(Evolve)。
挑战一:持久运行的安全与合规
安全与对齐难题
现有优化方法更多关注「分数高不高」,而忽视了「会不会出事」。比如,模型在演化中可能出现隐私泄露、目标跑偏等风险,而现有法规(如 EU AI Act、GDPR)都是按「静态模型」写的,根本没考虑会自己变的系统。
稳定性隐患
奖励模型如果数据少、反馈噪声大,很容易导致智能体行为不稳定,甚至出现意料之外的错误。就像开车时方向盘太灵敏,一点点抖动就会偏航。
挑战二:性能不仅要高,还要能稳住
专业领域评测难
在生物医学、法律等领域,很难有统一、可靠的「标准答案」,这让模型优化缺少精准的反馈信号。
效率与效果的平衡
多智能体优化可以让结果更好,但计算成本、延迟和不稳定性也会飙升,必须找到性能与资源消耗的平衡点。
优化成果的可迁移性差
在一种大模型上调好的提示和架构,换个模型可能就失效了,这对大规模落地是个大障碍。
挑战三:真正的自主进化
多模态与空间推理不足
现实世界不仅有文字,还有图像、视频、传感器数据等,智能体要学会在这些信息中建立自己的「世界模型」,并具备时间和空间的推理能力。
工具的自主使用与创造
现在的智能体大多用的是「别人准备好的工具」,缺少自己发现、组合、甚至创造工具的能力。
未来方向
这些问题并非无解,它们也是自进化 AI 走向更高阶段的机会:
开放式自进化模拟环境
建立一个能「关起门来自己练」的虚拟世界,让智能体在其中反复试错、优化提示、记忆、工具和工作流。
工具的自适应使用与创造
从被动调用固定工具,升级为能主动选择、组合甚至创造新工具,并用反馈和强化学习不断打磨。
贴近真实场景的长期评测
不再只做一次性的「考试」,而是设计能持续跟踪智能体长期表现的评测标准。
性能–资源双目标优化
让多智能体系统在性能和延迟、成本、能耗之间找到最优平衡点。
面向行业的定制演化
针对科学、医疗、法律、教育等领域,结合专有知识、特定评测标准和法规要求进行定制化演化。
未来的AI智能体,不仅要能跑,还要跑得远、跑得好,并且能在跑的过程中学会换鞋、补能、升级引擎。
沿着MOP→MOA→MAO→MASE的进化路线,并以「三定律」为指南,这篇论文正在为这种「可持续、可自我进化」的智能体提供很好的技术路线图。
不同于以往智能体调研(聚焦静态架构),这份综述填补自进化空白,提供实用指南。
如果你想深入探索,可访问论文配套的GitHub仓库,获取最新研究资源与代码工具。
综述对比
有趣的是,就在这篇综述发布前不久,普林斯顿大学团队也推出了《A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence》。
两篇论文相隔仅十天,却在内容与视角上形成了鲜明互补:
框架差异
格拉斯哥团队提出了「系统输入—智能体系统—环境—优化器」的四环反馈回路,直观、可操作,更强调落地性。
普林斯顿团队则以「演化什么、何时演化、如何演化」三大维度进行概括,更加宏观,也更具哲学意味。
技术聚焦差异
格拉斯哥团队深入探讨了 LLM 与终身学习场景,细化到 Prompt、Memory、Tools、多智能体通信等具体技术层面。
普林斯顿团队则更多聚焦于长远愿景,标题本身也更偏哲学化,对工程细节的涉及较少。
深度与应用差异
格拉斯哥团队提供了生物医学、编程等领域的实战案例,并专设了评估、安全与合规的章节。
普林斯顿团队则更偏向趋势与远景蓝图,强调整体性的思考。
换言之,普林斯顿的综述更像一幅宏观地图,展示了「自进化智能体」可能的未来方向;而格拉斯哥的综述更像一套操作指南,体现出当下研究者如何将自进化智能体真正落地。两者相互呼应,共同勾勒出这一新兴领域的理论图景与实践路径。
参考资料:
https://arxiv.org/pdf/2508.07407















