
AI-GitHub
行业佼佼者
0
粉丝
57
文章
9.88K
总浏览
0
平均评分
关于我
AI领域资深专家
#大语言模型
#机器学习
#深度学习
#自然语言处理
热门文章
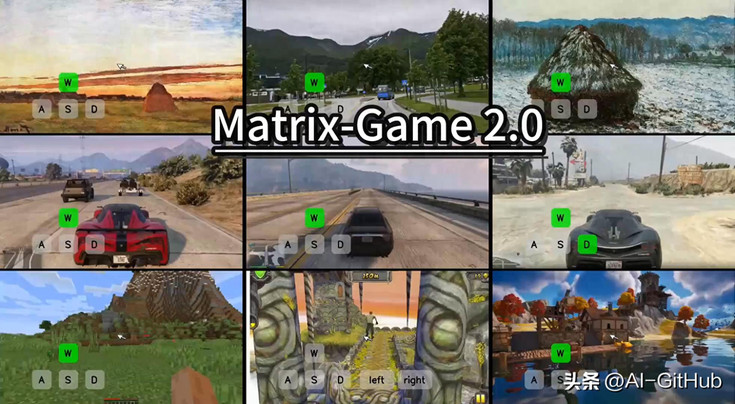

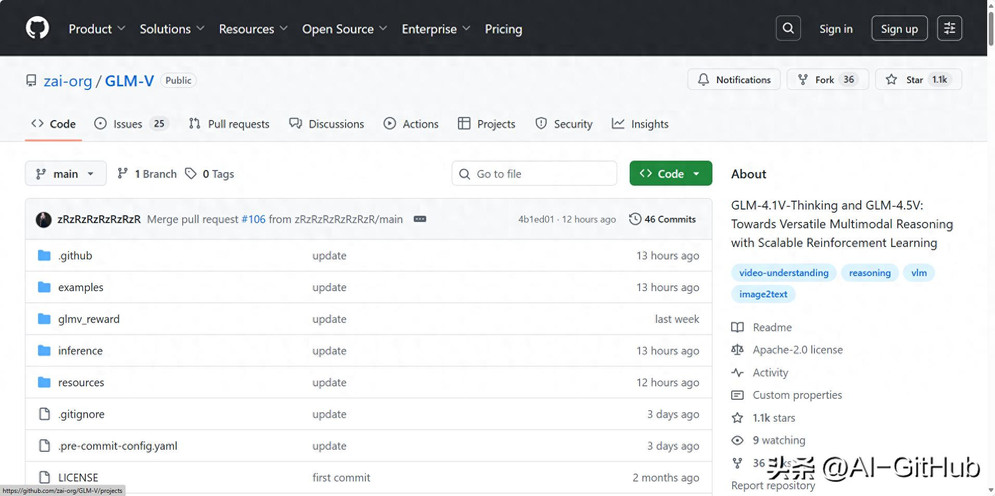

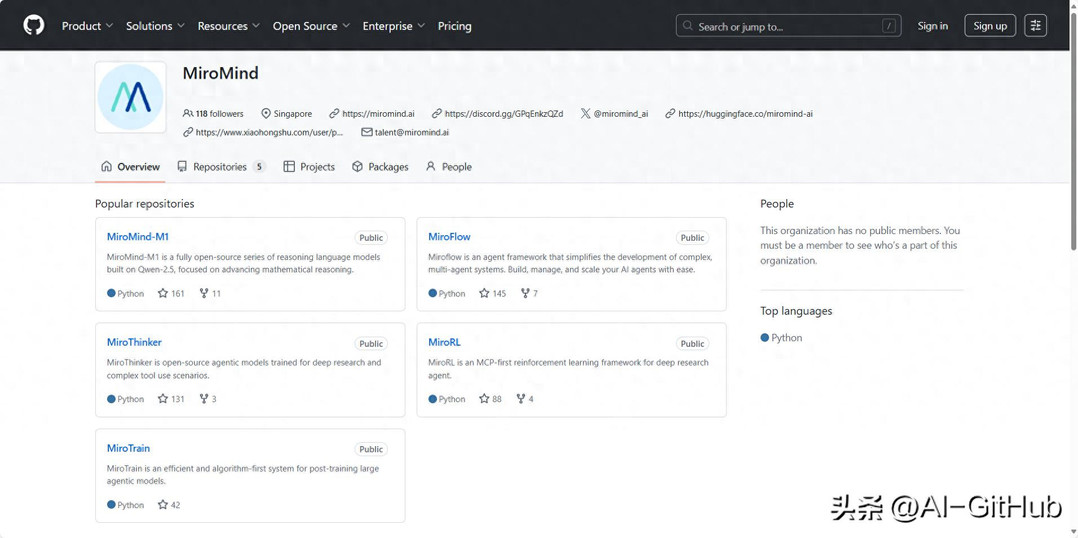
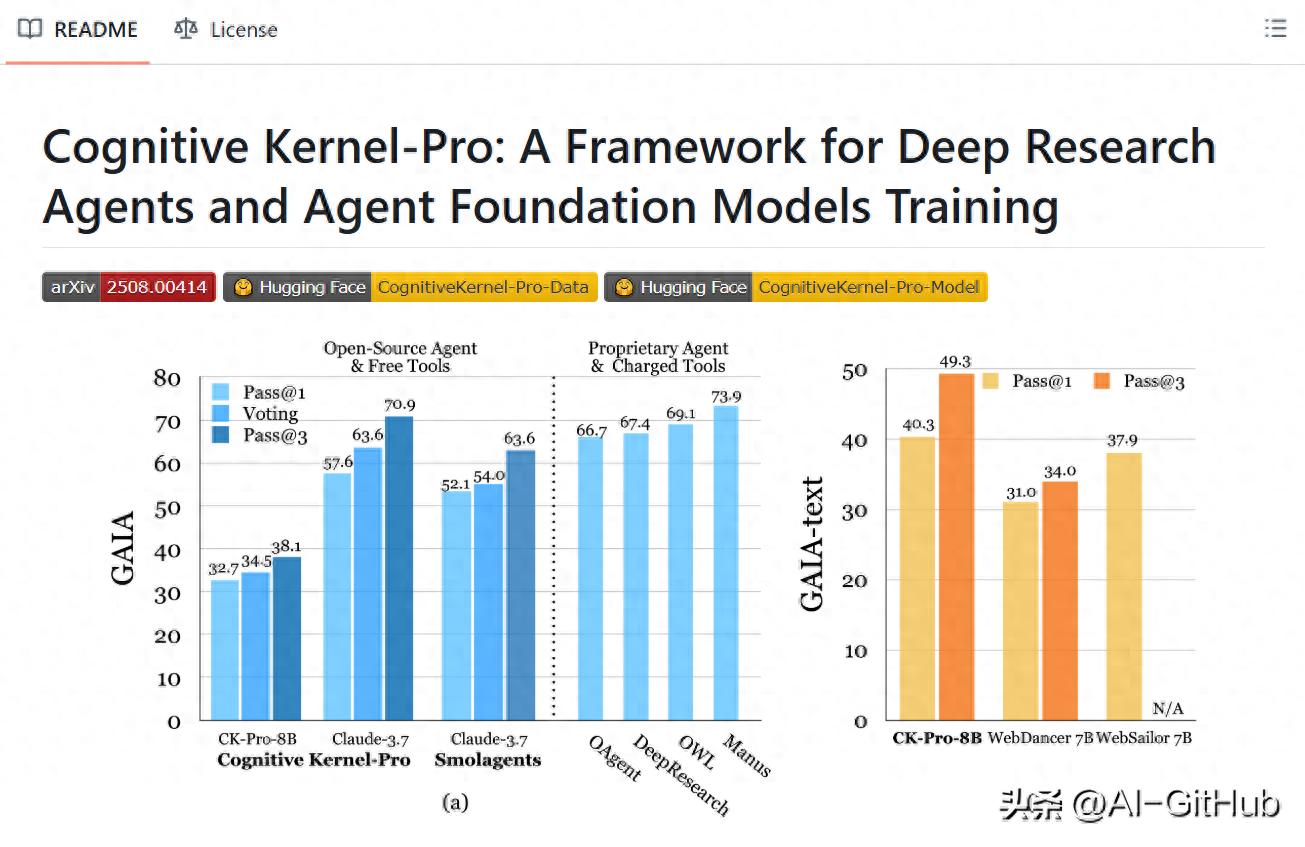


行业佼佼者
0
粉丝
57
文章
9.88K
总浏览
0
平均评分
AI领域资深专家



