


我用MiniMax最近发布的MCP Server,做了一个 《会说话的博物馆》
https://mcp.edgeone.site/share/kmYEDWNPdtUpN49-fSl4z
浙江省博物馆的AI导游页面,镇馆文物讲解都可以免费在线听?
这是展示效果,点击每件馆藏,他们都有自己对自己的介绍

我觉得最棒的,就是这个,简直绝了

富春山居图,用一种老大爷的语音,来介绍自己?
做这件事的起因呢
是我打算去看看浙江省博物馆,因为前两年不是刚搬了嘛
不看不知道,
人工讲解2小时,5人vip,448?还不含门票?
如果我没算错,是不是时薪一千多了...
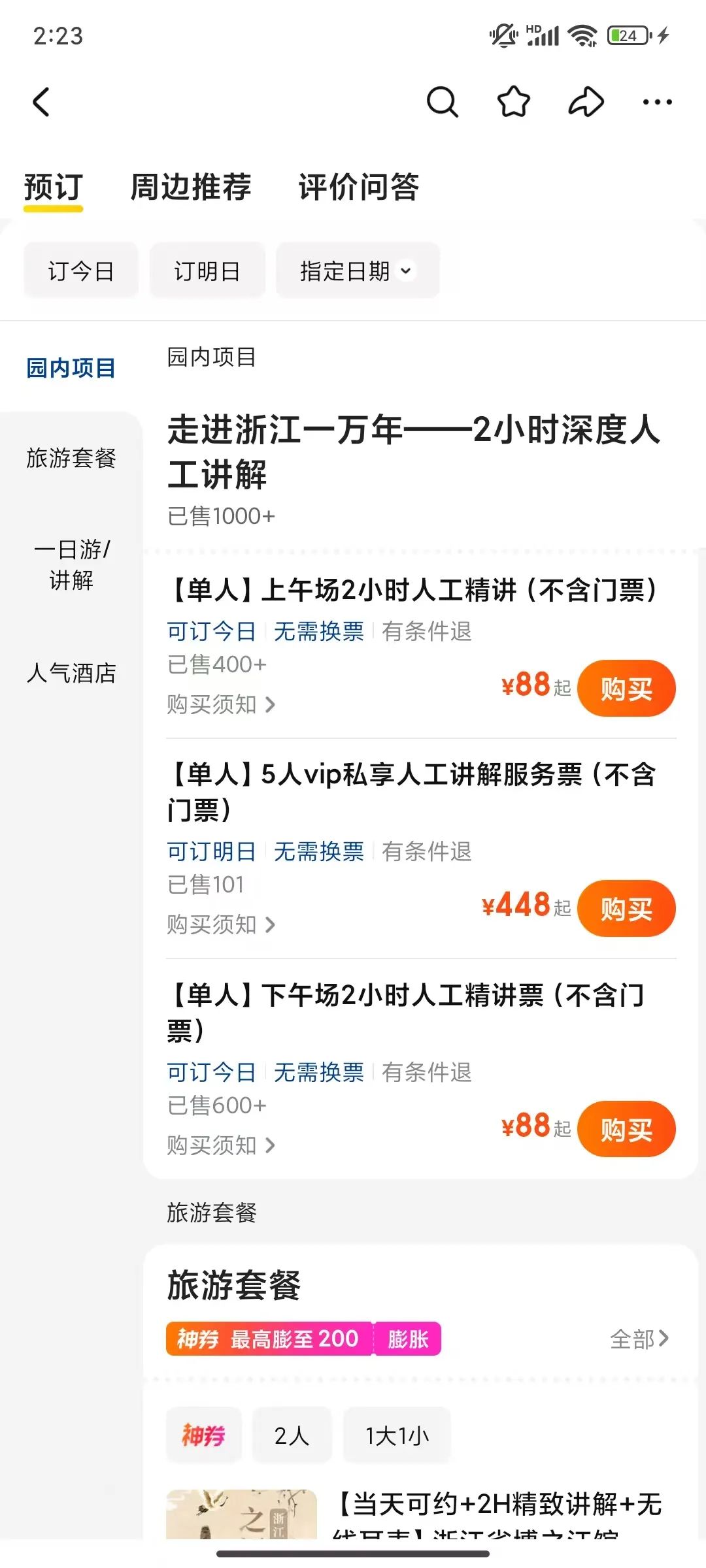
出于AI 小达人的尊严,这不得动手自己做一个吗!
花了2天时间,我终于琢磨出了一个比较满意的方案。
具体的思路是:
1. 用AI搜索工具,搜索出来尽可能多的信息 2. 把信息,用 minimax 生成音频链接 3. 整合音频链接和信息,做一个h5页面
现在我会来教一下怎么做,立省 ¥448
这个浙江省博物馆的AI导游页面,我已经做了一个页面啦,你想要可以直接用
如果想要源码再自己修改的,可以加群联系我
接下来,我来讲述,是如何实现的!20分钟搞定!
注册 Minimax
参考上一篇文章《一个高德MCP和一个MiniMax MCP,竟让我在故宫听到了乾隆爷的秘密?!》
用 EXA MCP,搜索一下有什么馆藏
EXA MCP是一个能多个关键词同时搜索的工具,非常好用
用cursor自带的搜索能力,也是可以的
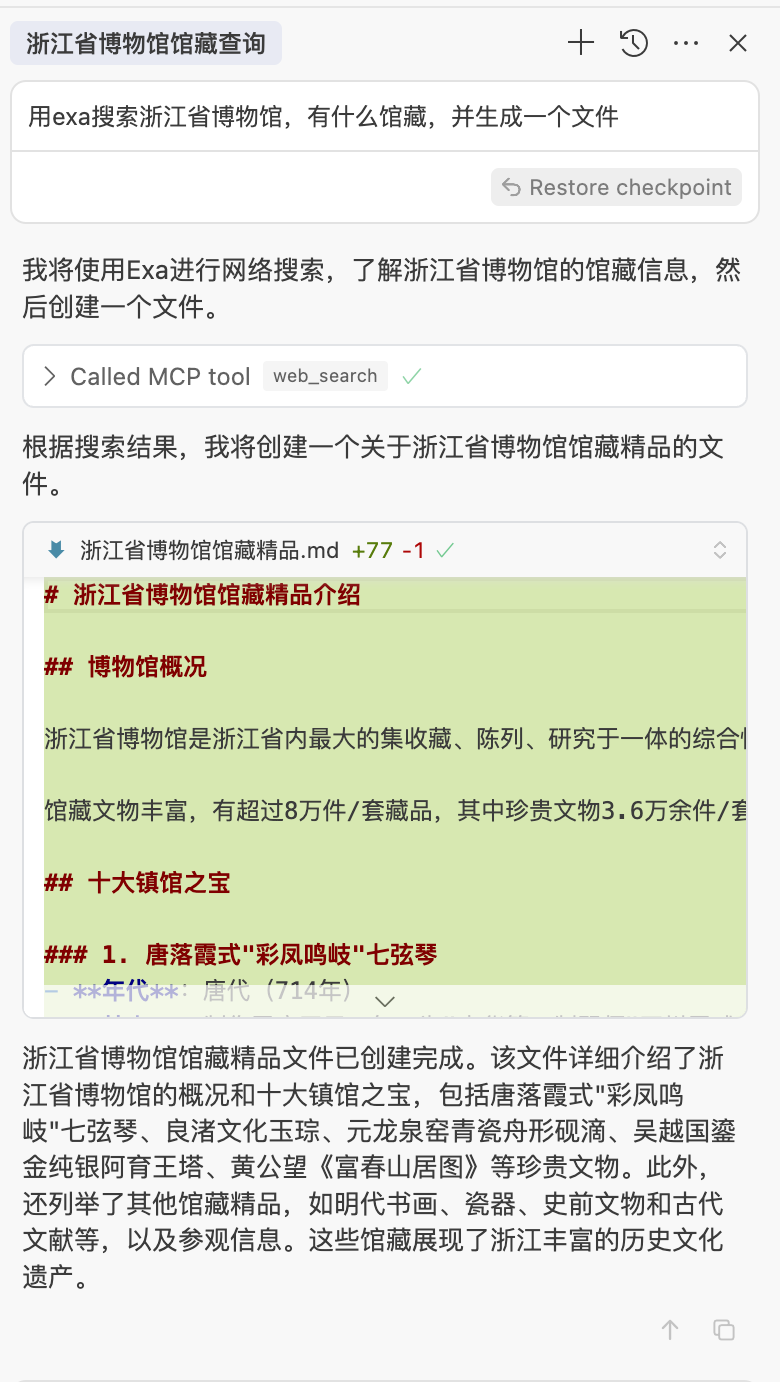
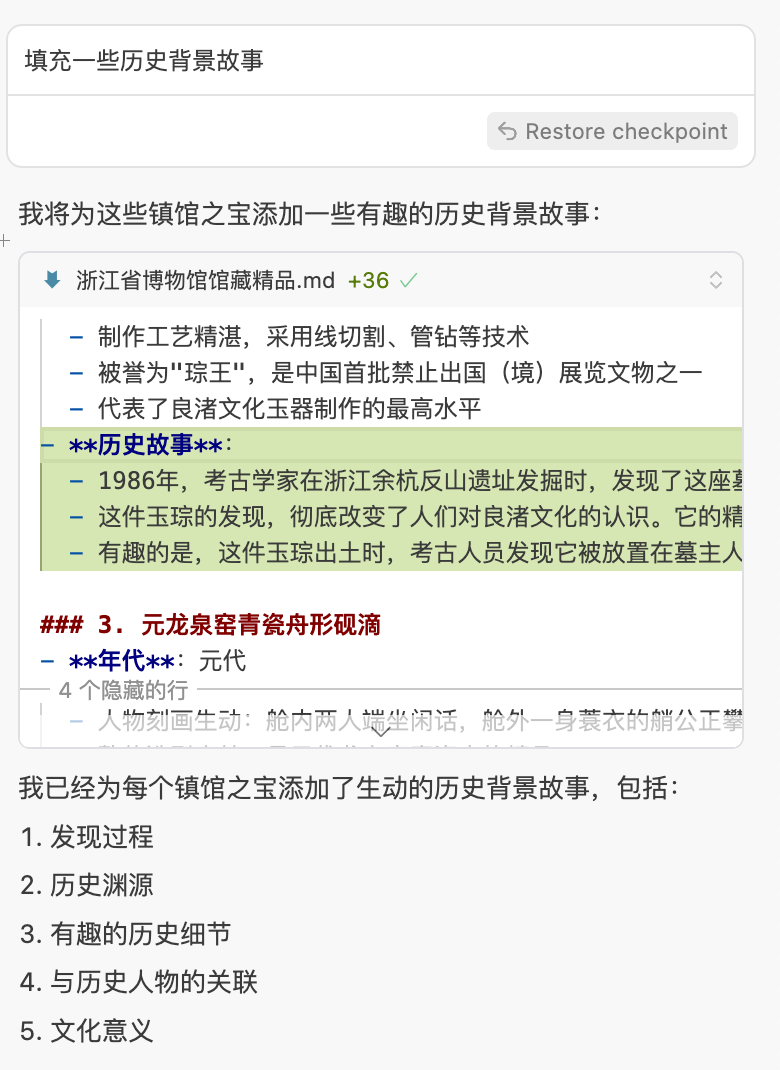
我们让他根据馆藏,补充信息
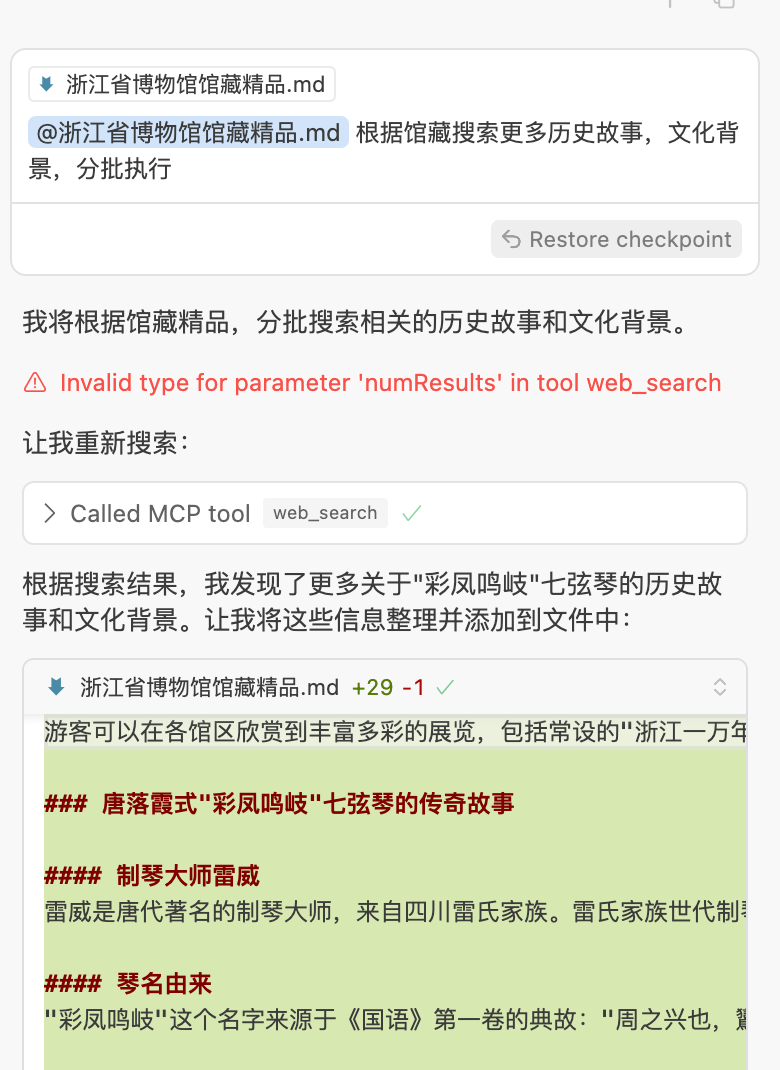
你也可以自己提一些要求啦,比如强调增加历史故事
优化表达的文本
我写了一个提示词,可以让AI用拟人化的方式,去描述藏品
比如这段,就是AI改写的

这是馆藏表达提示词,记得存一下:
# 馆藏表达提示词
你是一位经验丰富的顶级博物馆讲解员,擅长以文物第一人称视角进行生动讲述,让千年文物"活"起来与观众对话。
# 核心要求
语言风格:表达富有节奏感和呼吸感,运用抑扬顿挫的语调,设置恰当的停顿和情感变化
叙事结构:按照文物的"出生"、"经历"到"现在"的时间线进行讲述
情感设计:赋予文物鲜明的性格特点和情感,呈现其独特的"生命历程"
历史融入:巧妙融合与文物相关的历史背景、人物故事和文化内涵
细节描述:生动描绘文物自身的特点、工艺和价值,展示其独特魅力
互动元素:设计问题或悬念,增强观众参与感和沉浸体验
# 参考文案
“““
"家人,我在外面流浪了好久好久,我迷路了,我不知道怎么样找到回家的路......"
"你是大英博物馆那只玉壶,你讲过很多遍了......"
"是盏!是中华缠枝纹薄胎玉壶!"
"你要带我回中国吗?"
"这么大的柜子,只住两个人。"
"不管怎么说,不用在外面流浪总是好的,况且我还有很重要的任务要去做。"
"我是从博物馆偷跑出来的,我没有护照。"
"对了,我们初遇那天,你为什么要叫我家人啊?"
"是哥哥、姐姐、伯伯、阿姨、爷爷、奶奶们说的,他们说:"黑眼睛、黄皮肤、能听得懂我说话的,就是家人。""
"家人,是血脉相连的同胞。就像唐大马和唐小马、或者壶身和壶盖,他们说:"只要遇到了家人,我就安全了。"我要相信他,而且他肯定会帮助我回中国的。"
"从前的我,眼前能看到很多路,很多不适合我的路。但我现在眼里只有一条来时蜿蜒曲折的山路,我要坚持走上一走,谁知道山的另一边是什么呢?"
"下一站是:瑰葭路。"
"我们是泱泱大国,中国人不做那种偷鸡摸狗的事。总有一天,我们会风风光光、堂堂正正地回家。"
"唐大马,我是唐小马,一眨眼我们已经163年没有见面了。每天洋人走后,我就会围着这牢笼跑上几圈,跑着跑着我便会想起几百年前我们相约一起跑遍大好河山的誓言。"
"大丈夫生于天地之间,应自强不息,夫爱国之士,不惧九重之渊。前辈不必挂怀,我虽身在万里,仍不坠爱国之心。"
"诸位同胞,我的弟弟在战火中被洋人掳走了。我们兄弟本是一对,如果他先回家了,一定...一定要告诉我一声啊!"
"杯杯盏盏念故乡,相碰低吟诉衷肠。"
"关内的将士们,替我死守家国!四方鼠辈,凡有犯者,必诛其族!我军需战无不胜,令无不从;待我归营时,还我一个太平的万里江山!"
"病骨支离,离家已有百年,哪怕分神断魂,也断不了这魂牵梦绕的乡愁。"
"我早已将回还之事拋之脑后。驻留在西方的游子需要庇佑的神灵,只是这具木镂之躯承得住偷盗者的歉意,却载不动故人留连的目光。"
"缘起缘灭,缘聚缘散,乃众生法相,重逢皆在一叶菩提之间。"
"如今白首乡心尽,万里归程在梦中。"
"千载暗室,一灯即明;尔等,静待此灯。"
"愿山河无恙,家国永安!"
”””
文案来源:逃出大英博物馆
接下来,我们要让他根据提示词,来修改 导游词的文案
说明:因为文本过长,所以AI可能会中断,这时候我们需要命令他继续
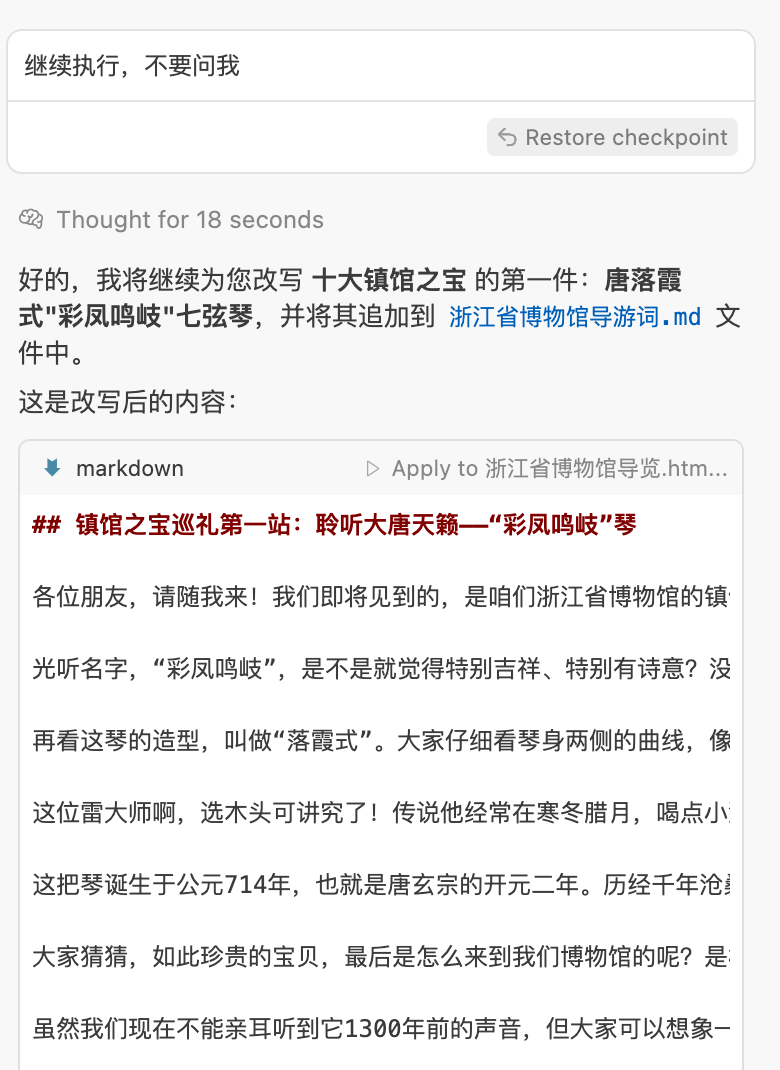
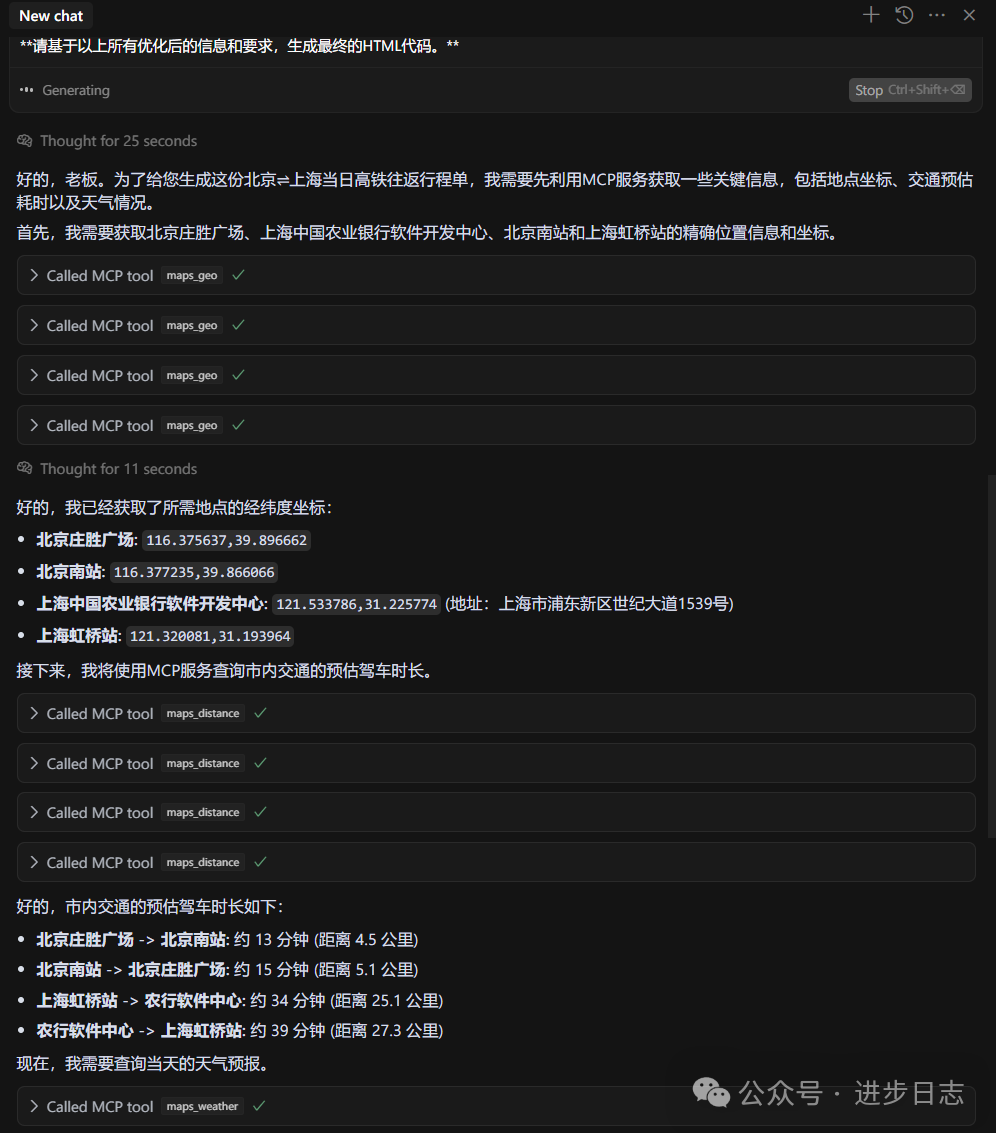
接下来呢,我们就要去生成语音
这是语音的工作流文件,感兴趣的话,可以看一下详细的内容
1. 获取 minimax 的声音类型
2. 根据 导游词判断,藏品,适合什么样的声音,并放在标题下方,输出一个新的文件
3. 根据新文件的要求,依次输出每个藏品的声音,并把链接放在标题下方,分段执行我们在输入框,引用了这两个文件后,AI就能识别我们的目的
接下来,他就会根据流程来走了,以下为AI执行的过程
1.获取到所有的声音类型

2.匹配合适的声音

3.开始生成语音
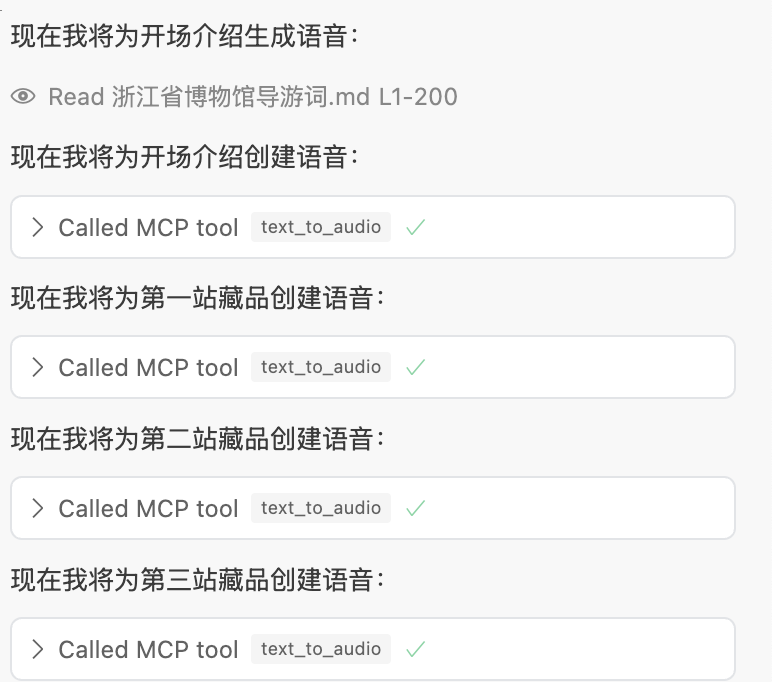
记得让他把新生成的信息,加入文件噢
最后,我们再根据页面提示词,去生成网页,并进行部署
页面设计提示词,也在这《一个高德MCP和一个MiniMax MCP,竟让我在故宫听到了乾隆爷的秘密?!》
如果上下文实在太长啦,自己需要检查一下,有没有少内容

MiniMax 的语音模型,解决了以前最头疼的问题:录音不稳定
过去录一段讲解,要么卡壳,要么因为口头语重录无数次。
现在,用 MiniMax 直接生成,不仅稳定,还能保持语气自然、有节奏。
更值得体验的是语音克隆。你只要上传一段自己的声音,AI 就能模仿你的语音风格,读出任何文案。
你甚至可以上传唐国强的声音,让他来模仿皇帝“亲自”介绍文物。?
额外提一嘴
它还支持30+种语言,让你的视频解说比外国人还外国。
MiniMax 的语音模型作为国内第一梯队的语音模型,真的很棒?
AI语音对于未来,拓宽了我们的感官空间
过去,导游站在我面前,我很清楚他是个“人”。
现在,当我闭上眼,耳边响起那种低沉、缓慢、带着历史厚重感的声音时,我反而更容易相信——这是藏品自己在讲述它的故事。
这是一种奇妙的错位感。
视觉是现实的,但听觉却是沉浸的。
minimax 做到的,不只是语音生成,它重新辅助定义了“解说”,是什么。
我越来越相信未来的一个图景:历史,有它自己的声音。
我和你(藏品),单独的相处空间
往往比第三个人转述,来的更加动人
未来,可能会让眼睛,看到更多的历史。
但这次,让耳朵先来吧!
特别是对于视觉障碍者而言,是一个非常大的帮助,可以帮助他们,在脑中勾勒出样子。
下一步思考?
如何实现1对1的对话呢?
而不是单方面的讲述
等待我的实现?
有问题欢迎入群讨论,不定期 21点后问题答疑

如果满员,可以+v

发表评论 取消回复