研究称,流行的人工智能基准 LMArena 据称有利于大型供应商 178 0 Salesforce AI Research发布多项创新,旨在解决企业AI系统在强大智能与稳定执行力之间的差距,即“锯齿状智能”。核心目标是构建更智能、可信、适用于企业应用的AI代理,并向“企业通用智能”(EGI)迈进。研究重点在于量化和解决AI性能不一致性,推出了SIMPLE数据集作为公开基准。更重要的是,Salesforce推出了CRMArena,一个模拟真实CRM场景的基准测试框架,用于全面
AI与经济双重夹击:人工智能正开始严重影响美国就业市场 107 0 美国劳工统计局最新数据显示,美国年轻大学毕业生进入职场后面临的期望与现实之间的差距已降至历史最低水平,表明新毕业生就业形势严峻。《大西洋月刊》分析指出,这一转变或由多重因素叠加所致,其中生成式人工智能的崛起被认为是关键因素之一。哈佛大学经济学家戴维·戴明警告称,生成式人工智能擅长信息整合、报告撰写和演示制作,而这些恰恰是年轻大学毕业生在办公室中的主要工作内容,暗示AI正在逐步取代初级岗位。然而,
Meta智能眼镜隐私政策更新:默认启用语音录制引隐私担忧 192 0 Meta已更新其针对雷朋Meta智能眼镜的美国隐私政策,关键变化是默认启用自动语音录制功能。用户语音录音现在将被用于训练Meta AI和其他Meta产品。此次更新取消了用户完全禁用语音录制的选项,用户仅能通过配套应用手动删除单个互动录音,或完全关闭语音控制功能。这意味着,除非用户彻底禁用语音控制,否则Meta AI摄像头将默认保持开启状态。Meta声称此举旨在提升Meta AI的易用性和产品功能,
AI基准测试平台LMArena陷争议:研究指责其偏袒OpenAI、谷歌和Meta 67 0 人工智能领域知名的公共基准测试平台LMArena近日遭遇信任危机。一项新的研究指出,该平台的排名系统存在偏袒OpenAI、谷歌和Meta等大型供应商的结构性问题,其不透明的流程和头部企业的固有优势可能导致排名失真。然而,LMArena运营团队已公开否认这些指控。LMArena通过向用户展示不同大型语言模型(LLM)的回复对比,并由用户投票选出更优者,最终形成广泛被行业引用的模型性能排行榜。企业常
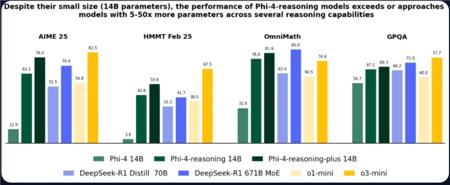
小身材,大智慧!微软Phi-4系列推理模型发布,性能直逼GPT-4o 163 0 微软正积极扩展其Phi系列紧凑型语言模型,最新发布了三款专为高级推理任务设计的新变体:Phi-4-reasoning、Phi-4-reasoning-plus 和 Phi-4-mini-reasoning。这些模型旨在通过结构化推理和内部反思处理复杂的问答,同时保持轻量级特性,使其能够在包括移动设备在内的低端硬件上高效运行,延续了微软Phi系列在资源受限设备上实现强大AI功能的愿景。Phi-4-r
Anthropic推出“Integrations”连接应用,Claude新增“高级研究”深挖信息 156 0 Anthropic周四发布重大更新,为旗下AI聊天机器人Claude引入全新的应用连接方式“Integrations”,并扩展了“深度研究”功能至“Advanced Research”,使Claude能够搜索网络、企业账户等更广泛的数据源。“Integrations”和“Advanced Research”目前面向Claude Max、Team和Enterprise计划用户开放Beta测试,Pro