
编辑:KingHZ
【新智元导读】Meta超级智能团队成员毕树超,回溯70年AI进化:从AlexNet掀起深度学习革命,到Transformer与Scaling Law驱动大模型爆发,再到强化学习+预训练通向AGI。他相信智能并非人类都独有,AGI曙光已现!
加入Meta超级智能实验室后,毕树超首次发声:大多数人可能低估了AI的影响!
十年前,他非常怀疑AGI,但在过去十年中,他逐渐接受了AGI,日渐笃定,甚至宣称:2025,AGI已来。

上个月,他在哥伦比亚大学和哈佛大学就人工智能发表了两次演讲。
许多参加的人都后来联系他,声称这次演讲改变了他们的AI观念。

在题为《推进硅基智能前沿:过去、开放问题与未来》的演讲中,毕树超系统阐述了过去15年的技术进展、当前待解难题以及未来发展趋势
目前,他在Meta从事强化学习/后训练/智能体研究。之前,他在OpenAI领导多模态研究;他还是YouTube Shorts的主要负责人。
他本科从浙江大学数学专业毕业,之后在加州大学伯克利分校获得统计学硕士和数学博士学位。

AGI曙光
最近,David Silver等人发表了《Welcome to the Era of Experience》。

他们的核心观点是:高质量的人类数据非常稀缺。
尽管人类文明已有几千年,但真正积累的高质量数据并不多,而且大部分文本快消耗殆尽。
所以问题是:如何生成更多的数据?

答案可能在于人类本身。人类的数据来源于人脑的思考,以及从真实环境中获得的反馈和奖励。
算力正在变得越来越廉价,计算机与环境的交互或许可自动生成新的知识与数据。这种方式将可能比人类自身产生数据的速度更快。
这也是为什么毕树超如此看好通用人工智能(AGI)和超人工智能(Artificial Superintelligence,ASI)的原因。

他分享了个人对AGI研究的心路历程。
一开始对通用人工智能持怀疑态度,因为这个领域存在大量炒作。
对他个人来说,最大的障碍是他曾坚定地相信:人脑是特别的,人类智能是独一无二的。
毕竟,目前许多技术,从数学角度来看,只不过改进了Tensor运算和梯度优化,本质上并不复杂。他不禁怀疑:人类真的那么难以复制吗?
但随着对AI理解的加深,他开始意识到:模拟人脑的方式不止一种。如果能够用计算机模仿人类的学习方式,那为什么不这样做呢?
这就是他如今更加相信AGI的原因:
一方面,也许大脑并不是独一无二的,它只是生物进化的结果。虽然复杂,但归根结底它也不过是一台「生物计算机」,并不比硅基计算机更神秘。
另一方面,也许真正关键的因素不是结构的复杂程度,而是系统是否具备足够的规模。
AI双城记
在哥伦比亚大学,他追溯了人工智能(AI)的思想根源。

这一切都始于1948-1950年左右。

当时,Alan Turing提出了一个问题:机器能思考吗?
图灵提出,人工智能不应试图模仿成人的大脑(包含复杂的经验和偏见),而应设计一个简单的模型,尽量减少人为预设的结构,让模型通过数据自主学习。
毕树超对观众说:「这正是机器学习的核心。你构建一个几乎不含人类先验知识的系统,让它从数据中学习。」
他重点讲了自监督学习和强化学习。
他回顾了自监督学习、深度网络以及像Transformer这样的里程碑式架构的兴起。
他展示了计算能力和数据规模的提升(而非人工编码的知识)如何带来性能的飞跃。
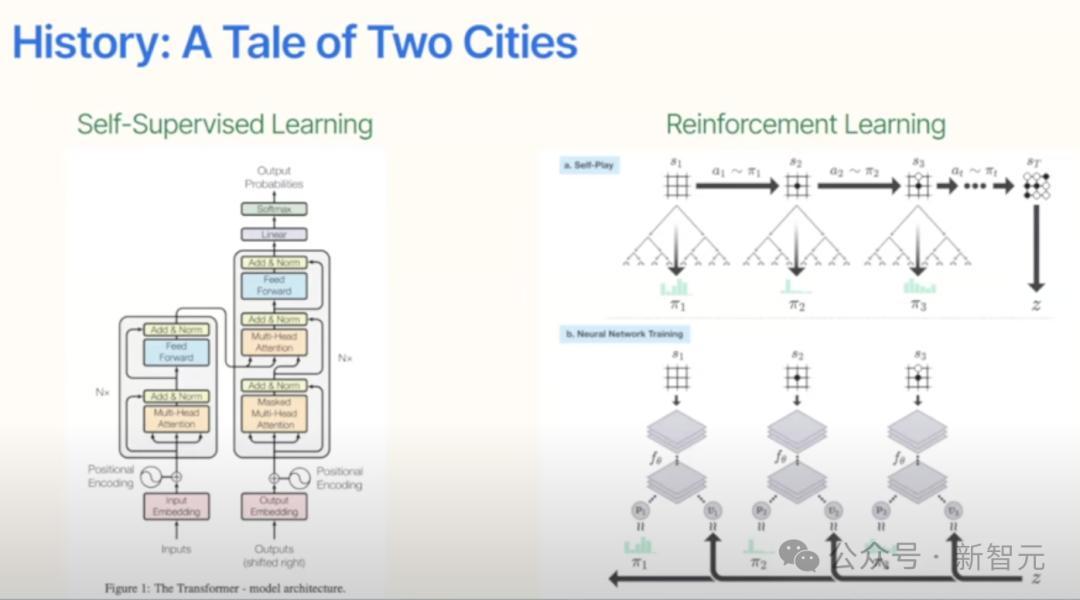
自监督学习
2012年,出现了AlexNet。
基本上可以说,这是第一个大规模深度学习模型,使用了GPU和大量数据。
AlexNet错误率令人惊叹,性能之好史无前例。
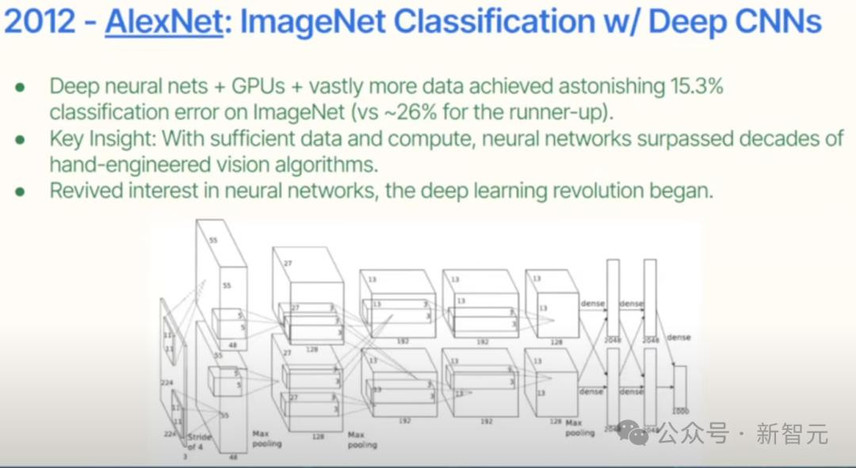
从中,大家得到了一个启示:只要有足够的数据和计算能力,神经网络就会超越人类过去几十年手工设计的视觉算法。
在当时,对于从事视觉研究的研究人员来说,是一场灾难,几十年付诸东流。
这重新唤起了人们对神经网络的兴趣,深度学习革命开始了。
大多数人认为2012年标志着深度学习革命的开始。
然后到了2013年,谷歌发表了Word2Vec。
简单来说,「Word2Vec」用一个嵌入向量,来表示单词。
从此,单词可以进行算术运算,比如「king-man=queen-woman」。
向量运算竟然能捕捉语义关系!更关键的是,这些词嵌入在下游任务中表现惊人。
这引发了另外两个趋势:
(1)Word2Vec演变到一切皆可向量化(everything2Vec)。
(2)强化了计算+数据的优势,这种结合远比归纳偏差表现要好。

这回应了图灵的设想:我们不想模拟成人的大脑,这意味着我们不希望在模型中加入人类的归纳偏差。
2014年,生成模型GAN出现了。

GAN在生成领域石破天惊,但与自监督学习关系不大
2015年,深度学习「加速器」Adam优化器已经诞生了,开始流行。
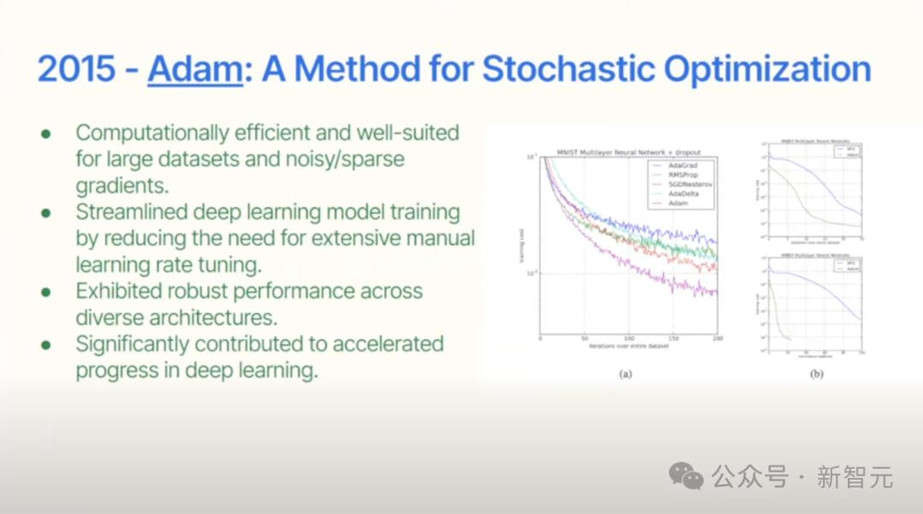
它标准化了训练流程,终于不用再手工调参了!特别适合处理海量数据和稀疏梯度,直到今天大多数优化器都是Adam的变种。
同年的ResNet更是神来之笔!
当时深层网络训练就像走钢丝——梯度要么消失要么爆炸。而ResNet的「跳跃连接」(skip connection)就像给神经网络装了电梯:浅层特征可以直接跨层传输。

残差连接让优化变得非常容易:右图(a)没有残差连接时崎岖不平,(b)引入残差后如瓷碗一般平滑。
如果采用这种结构,可以确保学习起来容易得多。而且这种技巧几乎适用于所有网络架构。这就是为什么现在几乎所有网络都采用这种结构。
不过当年,很多数学背景的人都质疑过深度学习中的这类技巧。

豁然开朗
演讲的前一天,毕树超和物理教授聊天才意识到:在低维空间建立的统计直觉,在万亿参数的高维空间根本不适用!
原因是大家都生活在低维空间中,低维度的直觉难以推广到高维空间。
毕树超花了好几年才克服了这些错误的直观。
他之所以困惑一大原因在于深度神经网络需要的是非凸优化(non-convex optimization)。
当处理非凸优化时,首先担心是陷入随机的局部最小值。如果最好的结果不过是随机的局部最小值,怎么能信任结果呢?然后,有很多关于这个的研究。

让他重拾信心的第一个发现是:在高维空间里,陷入局部最优其实非常难。在三维世界看二维曲面时,局部极小值确实像深坑难爬出来。但在十亿维空间里,有无数个逃生通道!
第二个发现更妙:就算被困住,这些「局部极小值」其实离全局最优根本不远!
所以现在没人再纠结非凸优化问题了。
那再说个更颠覆的现象——过参数不会带来过拟合。
在传统的统计分析领域中,如果参数数量大于数据点数量,那是一场灾难。从理论上讲,这会导致过拟合。
但深度学习模型参数动不动就是样本量的百倍!

作为数学统计双背景的人,这曾让他困惑不已、夜不能寐...
直到发现:即便用随机标签训练,网络也会优先学习真实模式,
这就是著名的「双下降现象」:当过参数化模型达到插值点后,会进入广阔的零损失解空间,并自动选择泛化性最优的解。
现在,终于可以说:过参数化不是bug,是feature!
ChatGPT前传
2014年,出现了第一篇关于注意力机制的论文。
从2014年到2016年,当时的主要挑战是,这些模型很难并行训练,以及梯度消失。

LSTM有所帮助,但也没有完全解决问题。
然后,Transformer就出现了。
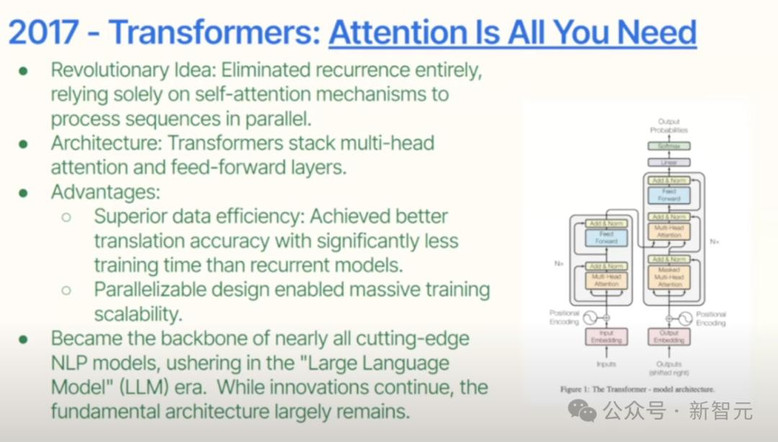
这是过去十年中最重要的论文之一。它完全消除了递归,完全依赖于自注意力。
Transformer是一个转折点,优雅地解决了之前的局限性。
毕树超盛赞:「这是过去十年最重要的架构。它高度可并行化、数据效率高,并且扩展性极佳。」
2018年,出现了GPT-1。2019年,出现了GPT-2。2020年,出现了GPT-3。
毕树超认为GenAI的本质通用性(generalizable)。
以前,只要有数据,每个领域都可以构建一个专门的模型。这并不具备可扩展性。而GPT系列模型非常通用,可以通过零样本或少样本学习完成任务。

2020年,Scaling Law论文揭示惊人规律:算力、参数量、数据量每增加10倍,损失函数就线性下降!
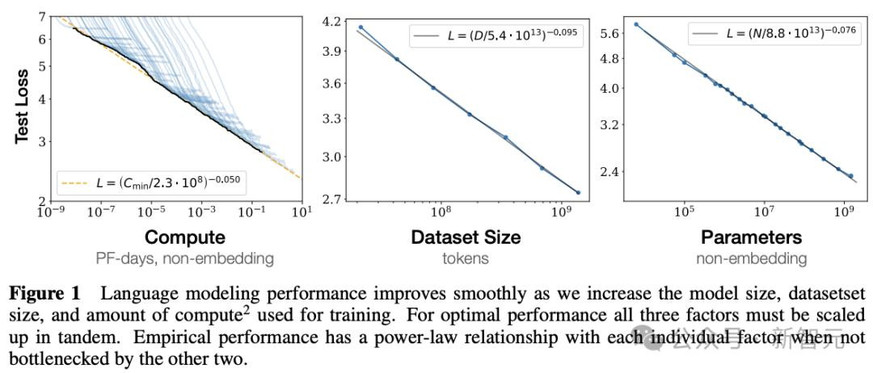
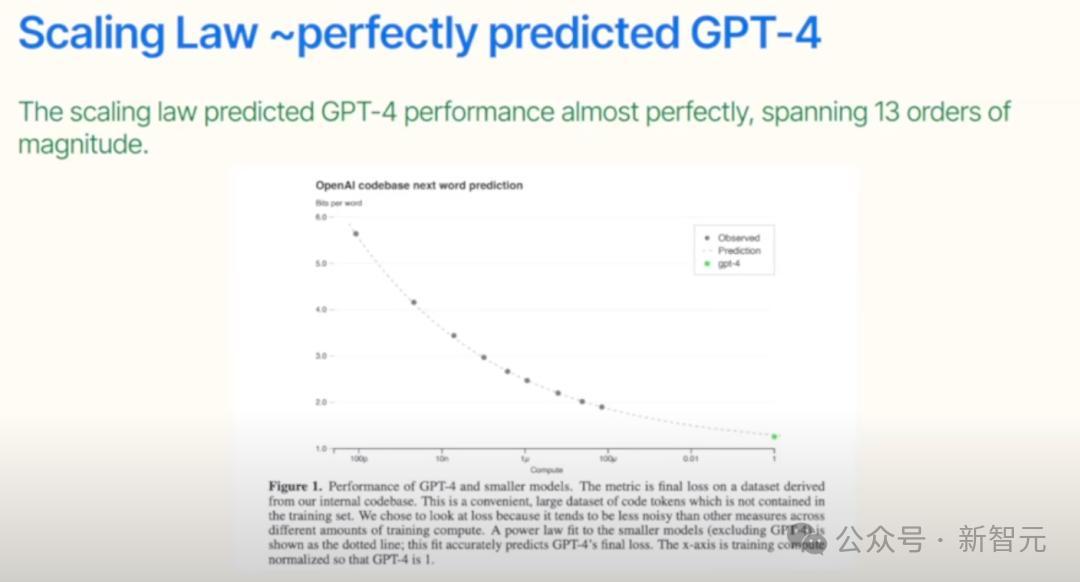
这个定律精准预测了GPT-4的性能。虽然它终将触及天花板,但在此之前,10万亿美元级的算力投入都将持续获得回报!
这也是《The Bitter Lesson》这篇雄文的核心:70年AI史就是「算力碾压人类精巧设计的算法」的历史!

当然,作为数学系毕业生的毕树超总在追问scaling的源头——或许答案藏在数据分布的本征结构中。
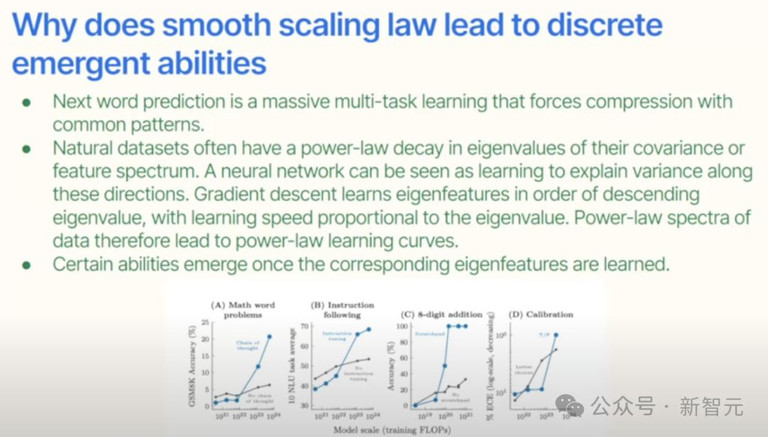
Scaling Law如何让模型顿悟?
看看数据分布:顶尖医生解决罕见病,普通医生处理常见病;
算术书籍浩如烟海,代数几何专著却凤毛麟角。
智能的分布恰如幂律曲线!
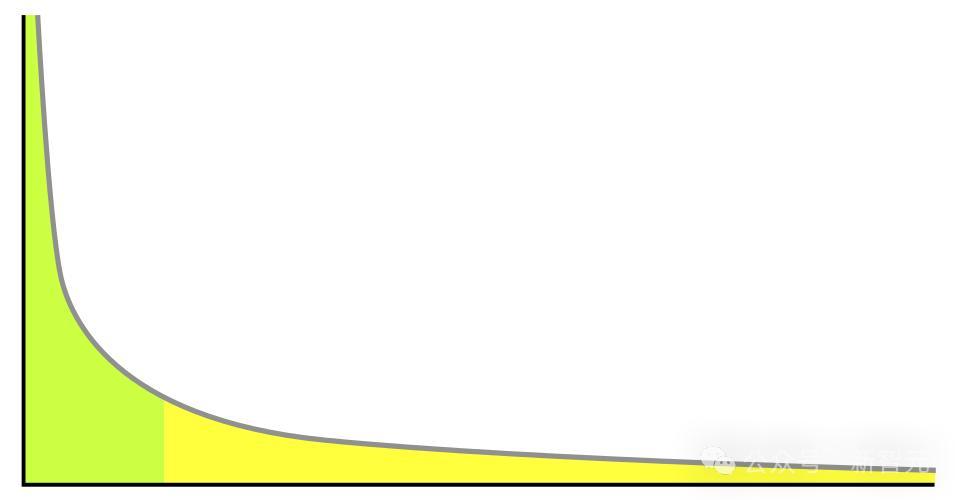
Scaling law的本质或许在此:每挖掘高一个数量级的「智能稀有度」,就需要十倍算力投入!
这解释了为何模型总先学通用模式。
三年前,全网争论的「能力涌现」,其实只是幂律数据遇到对数坐标的视觉把戏!
当算力突破临界点,AI「突然」学会微积分不过是捕获了数据长尾中的高阶模式!
这只是一个视角问题。它并不是突然出现的,它实际上只是反映了底层数据。
Ilya有一句名言:「模型只是想学习。」
Transformer架构终于让AI回归本能:吃数据,吐智能!。

过去十年,我们逐渐打破了很多对机器学习的误解。如今,主流观点是:预测本身的压缩,其实等同于理解,甚至是智能的体现。
从信息论的角度来看,Shannon把「信息」定义为「不可预测性」。「智能」可以理解为:让这个世界变得越来越不让你感到惊讶的能力。
从这个意义上看,大语言模型在预测下一个词时,其实是在压缩语言中的各种模式。这正是人类理解世界的方式之一。
从认知科学的角度,人类的学习过程本质上也是压缩过程。物理定律、数学公理等方式把世界的观察总结成最小的一组规则。
因此,从信息到学习,从预测到理解,「压缩」是背后共同的核心逻辑。
强化学习
整个深度强化学习从2015年开始。
当时,出现了DQN网络。它可以玩多种雅达利游戏,玩得比人类好多了。

这些模型发现了很多人类想不到的策略,因此人们称之为「外星智能」(alien intelligence)。
真正的核爆点在围棋上。AlphaGo的表现让人们第一次意识到:「这些模型真的有智能。」
AlphaGo起初是从人类棋谱中训练起来的,它结合了深度神经网络、、自我博弈(self-play)和蒙特卡洛树搜索(Monte Carlo Tree Search),最终击败了世界冠军。
到了2017年,AlphaGo Zero出现了。模型进一步升级,完全不再依赖人类数据,所有训练都来自自我对弈,堪称「AI界周伯通」!

2018年,AlphaZero再进一步。
2019年,强化学习扩展到了电子游戏,比如《星际争霸》。
但这股热潮很快退却了,因为人们发现:AI虽然能「打游戏」,却在现实中没有太大用处。
直到强化学习与预训练模型结合,这一切才真正发生了变化,开启了「预训练与强化学习结合的新时代」。
低算力RL
比如2022年的InstructGPT,它让大语言模型不仅仅是「自动补全工具」,而是能够理解和执行人类指令。

而2022年发布的ChatGPT,更是通过强化学习(特别是人类反馈强化学习,RLHF)进一步提升了交互能力。
当时,这个项目只是John Schulman等人的一个低调研究预览。谁曾想,它如今每周有超过5亿用户使用,彻底改变了人们获取信息的方式。

但仔细一想,这跟之前提到的「游戏里的强化学习」到底有什么不同呢?
强化学习+预训练模型,可以应用到现实中更广泛、更有价值的场景中。
关于当前AI模型的训练方式,强化学习所占的计算资源比例其实非常小,就像蛋糕上点缀的樱桃。
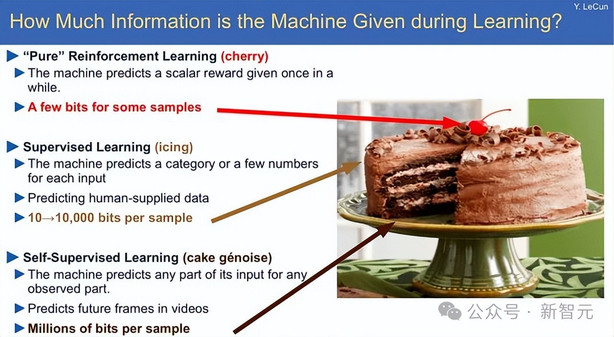
但未来如果要构建真正的AGI乃至ASI,强化学习必须发挥更大的作用,尤其是在适应未知环境方面。
高算力RL
在过去六七十年的AI发展中,有两类技术最能随着算力增长而不断进步:
- 「学习」:也就是预训练;
- 「搜索」:通过策略探索获得新解。
而「搜索」这一方向,目前还远远不够好。
这也是为什么我们要进入AI发展的「第二阶段范式」:让预训练与高计算量强化学习真正结合起来。
从2014年的o系列模型开始,这种趋势已经出现。
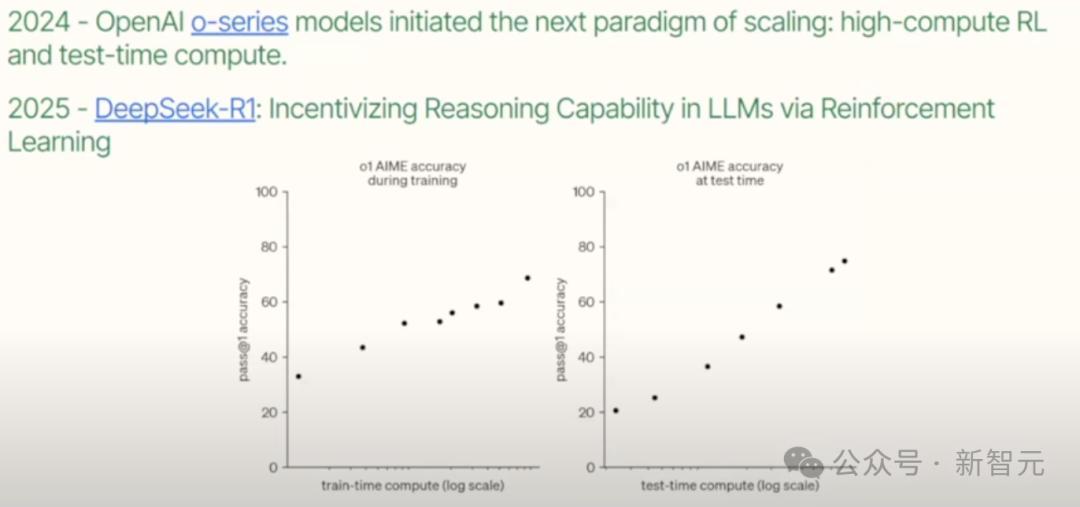
在数学基准上AIME中的表现,开源的DeepSeek R1已经超过o1。

这并不是一件简单的事,它代表了全新的计算范式:「高算力RL」。
这种范式然显著增强了模型的「个体学习」能力。
虽然问题还有很多值得探索,但毕树超在演讲中表示:「每隔几个月,我们就看到一些曾经被认为不可能的事情成为现实。这应该让我们重新审视所有我们仍然认为不可能的事情。 」
也许很多我们以为的不可能,其实只是知识的局限。
















