
优先级不是拍脑袋决定的,它背后有一套可推演、可落地的逻辑体系。本文将从实际业务场景出发,拆解常见的优先级误区,并构建一套兼顾战略目标与用户价值的需求排序模型,帮助你在纷繁复杂的项目中做出更清晰、更有底气的决策。

作为产品经理常常会遇到这样的情况:需求很多,不知道应该先做哪些。在这里分享一下我的思考。
目标
以终为始。
在每年年终总结的时候,我们都需要总结当年做的事情,也就是业绩。而业绩是越大越好。
此时,在人力资源一定的情况,我们的目标是把资源放到价值更高的事情,期望有最大的ROI。这个点非常重要重要。
那么什么才是价值更高的事情?
我们的工作有很多看不见的核心,公司有核心战略,业务有核心战略,在我看来就是有2个核心,一是公司核心,二是业务核心,这些就是价值更高的事情。
场景
下面罗列出我认为非常高频出现的需要优先处理的需求的场景,也就是当这些需求出现的时候,其他需求需要让道。

总结出以下影响需求优先级的点。

我的模型RTT
概述
- R:ROI,也就是投资回报率
- T:time,指的是时效性
- T:time,指的是等待时长
RTT=【(价值*核心度)/成本】*【(时效性+等待时长)/2】
参数
1、价值:商业价值、增效价值。——理想的是以元为单位/小时为单位。其他价值也可以写上。
如果是单场活动,请描述此场活动产生的价值。如果是重复的活动,请填写年活动场次。
如果是持续的效率提升,请描述一个月将产生多少的价值。将计算一年产生的价值。
所有的价值将转换为元。
这里价值还是比较灵活一点,要点是尽可能描述出这个功能未来一年产生的价值,因为以年去汇总价值会比较合理,例如年报就是以年汇总的。
2、核心度:公司战略、业务战略——公司战略最优先,其次业务战略优先。
3、时效性:必须在某个时间点上线。保证赶时间的车能够早点到达终点,不然这趟车就没有意义了。——算是紧急需求。
4、成本:人天。
5、等待时间,随着等待的时间拉长,会明显降低业务的耐心,应该适当处理。——例如:延缓一个月时ROI*1.5,延缓1.5个月时ROI*1.75,延缓2个月时ROI*2。
指导思想
ROI导向,也就是价值/成本。
更重要的是服务于公司战略、业务战略,也就是为什么价值需要乘以核心度。
另外,ROI会根据时效性和等待时长有增幅。就像玩游戏的时候可以随着时间叠层数,然后增加伤害。这个对应的场景是有些需求当等待的时间太长时,会引起业务声量的放大,可能会出现不和谐的声音或者向上反馈引起插入需求。
为了降低时间参数对于公式的极大影响,于是除以2。
实际的量化操作
比较理想的情况下,业务把每个需求的价值都写得一清二楚,但是操作起来比较繁琐,需要等待一个不错的时机来试行这个事情。
我暂时对这个模型进行了简化。对几个参数都放在了一样重要的地位,把它们处于同一尺度范围内,也就是下面的4,至于为什么是4,主要是因为我把普通的需求看成是1,然后认为极高价值的需求是4是一个还算合理的逻辑,否则普通需求没有出头之日。另外4的话也有利于以0.5作为差值将各个情况区分开来,看起来还是合理的,也就这么设置了。
1、价值分为以下几个维度:

2、核心度:
3、成本:

4、时效性:

5、等待时长:
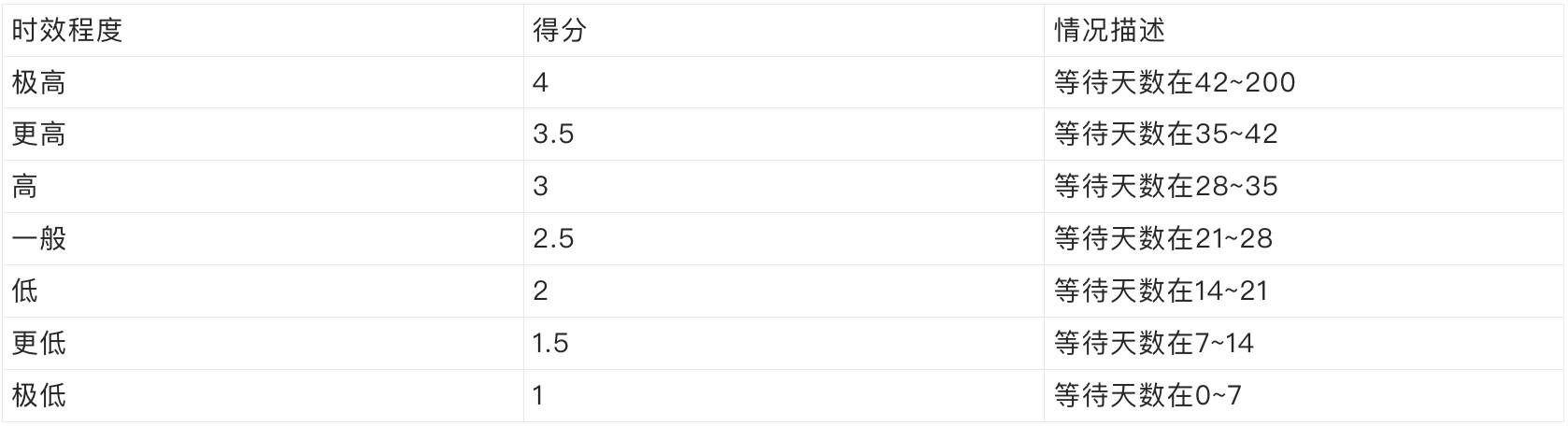
实际的操作结果
整体来说,需求优先级判断比较准确。虽然加入了主观经验的判断,但不影响使用。当然模型并不完美,如果有机会能够让业务参与到价值评估中来,那会是更好的一件事。
巨大优势在于仅凭产品经理一人就可以将需求比较好地排好优先级,劣势在于如果评估错误会带来错误的优先级。实际操作上看其实问题不大。
我在使用这个需求优先级模型的同时,会结合实际的情况对优先级进行灵活安排,需要插入的需求可以插入,所以一般的需求会走这个模型,如果有特别的需求就会人为介入调整优先级。总体来说,能够满足当前需求。
我参考的模型—WSJF
概要认识
规模化敏捷框架SAFe(Scaled Agile Frame work)采用一种定量计算法来评估需求的优先级,即“加权最短作业优先法”(Weighted Shortest Job First,简称WSJF)。其计算公式如下:
WSJF = Cost of Delay (CoD) / Job Duration (or Job Size)
翻译为:
加权最短作业优先分数 = 延迟成本 / 工作持续时间(或工作规模)
这个公式可以进一步拆解为三个维度的和与一个维度的比,以便于更实际地进行估算:
WSJF = (用户-业务价值 + 时间紧迫性 + 风险降低与机会促成价值) / 工作规模(或持续时间)
公式的组成部分详解
分子:延迟成本 (Cost of Delay – CoD)
CoD = 用户业务价值 + 时间紧迫性 + 风险降低/机会促成价值
成本延迟是指因推迟完成某项工作而造成的所有经济损失。它由三个部分组成:
1、用户/业务价值 (User-Business Value)
- 是什么:这项工作完成后,能为用户和公司带来多少直接价值?
- 示例:能增加多少收入?能节省多少成本?能提升多少用户满意度或市场份额?
- 提问:“如果立即完成这个功能,相比晚六个月完成,我们能多赚多少钱?”
2、时间紧迫性 (Time Criticality)
- 是什么:这项工作的价值随时间衰减的速度有多快?是否有硬性的截止日期?
- 示例:季节性功能(如圣诞节促销)、合规性要求、市场窗口期、依赖于其他项目的关键路径。
- 提问:“下个月完成和三个月后完成,价值差异有多大?”
3、风险降低与机会促成价值 (Risk Reduction and/or Opportunity Enablement Value)
- 是什么:这项工作能在多大程度上降低未来风险(如技术债务、安全漏洞)或为未来创造更多机会(如学习新知识、开辟新市场)?
- 示例:重构陈旧代码以减少未来的故障;开发一个基础平台以支持后续多个产品的快速上线;进行一项关键实验以验证市场假设。
- 提问:“完成这个工作后,能让我们未来的决策更清晰、风险更小吗?”
分母:工作持续时间/规模 (Job Duration/Size)
- 是什么:完成这项工作所需的相对努力量。在敏捷中,这通常用人天来估算。
- 有的资料说“规模”是大概的时间,难以预估出精准的人天,这个我倒是不太同意。我认为操作起来难度并不是很高,难点在于预估出来的人天是否精准,这个可以在实践中不断调优。
如何使用 WSJF
1、选择基准:挑选一个中等规模、大家熟悉的工作项作为基准,设定其所有分数为1。
2、相对估算:
- 估算分子(CoD):对每个工作项,分别估算其三个部分(用户价值、时间紧迫性、风险/机会)相对于基准的分数。然后将三个分数相加,得到该工作的总CoD。例如:一项工作的用户价值是基准的3倍,时间紧迫性是2倍,风险/机会是1倍,则总CoD=3+2+1=6。
- 估算分母(规模):估算每个工作项的规模相对于基准的分数。例如:一项工作的规模大约是基准的2倍,则分数为2。
3、计算WSJF分数:用每个工作的总 CoD 除以其规模分数。接上例:WSJF = 6 / 2 = 3.0。
排序:按照WSJF分数从高到低对所有工作项进行排序。分数最高的,优先级最高。
案例
假设我们有三个功能需要排序:功能A、功能B、功能C。我们以功能B为基准(所有项设为1)。
分析:
- 功能B:WSJF=3.0,分数最高。虽然它的绝对价值不是最大,但它“短小精悍”,能快速交付不错的价值。
- 功能A:WSJF=2.0。价值很高(CoD=10),但规模也较大(5),导致单位收益略低。
- 功能C:WSJF=1.0。它的延迟成本最高(CoD=13),但它的规模实在太大了(13)。如果先做它,团队会在很长一段时间内无法交付任何其他价值,而在这段时间里,因为延迟功能A和B所造成的损失可能远大于功能C带来的收益。它应该被拆分或延后。
这个例子完美体现了WSJF的精髓:避免被“大项目”拖住脚步,优先实现“高价值、低成本”的快赢项目。
优势与局限性
优势:
- 最大化投资回报率:通过优先处理高CoD和低规模的工作,能最快地释放价值。
- 透明化决策:使优先级决策过程对所有人透明且可追溯。
局限性与注意事项
- 估算的准确性:WSJF严重依赖估算的准确性。如果估算偏差很大,结果也会失真。它适用于相对估算,而非绝对计算。
- 不适用于所有场景:对于一些基础性、法规性或战略性的工作,即使WSJF分数低,也可能必须执行。WSJF是一个重要的输入,而非唯一的决策标准。
- 偏向小型任务:可能会过度偏向小型任务,而忽略了对生态系统至关重要的长期战略投资。确保“风险降低/机会促成”项被充分评估可以缓解这一问题。
我参考的模型—KANO
概要认识
KANO模型是一种对用户需求进行分类和优先排序的工具。它通过分析用户对产品功能满意度的评价,揭示了产品与用户功能满意之间的非线性关系。
核心
核心在于设立问卷,根据问卷来获得量化数据。
KANO问卷的核心在于,针对每一个需要评估的功能点,都必须提出一正一反两个问题:
- 正向问题:如果产品具备某项功能,您的感觉是?
- 反向问题:如果产品不具备某项功能,您的感觉是?
这种设计是为了捕捉用户对功能“存在”和“缺失”时的不同情绪反应,从而精准地对该功能进行分类。
详细评估逻辑
设立问卷
① 功能描述:清晰、无歧义地描述要评估的功能。
② 正向问题:“如果我们的产品具备【功能描述】,您的评价是?”
③ 反向问题:“如果我们的产品不具备【功能描述】,您的评价是?”
④ 选项:每个问题都使用统一的5级满意度选项:
根据问卷答案归属到需求类型
用户完成问卷后,我们需要根据每个用户对同一功能的正反两个问题的答案组合,来确定该功能对于该用户属于哪类需求。
我们使用下面的 KANO评价对照表来进行分类。

KANO评价对照表中的字母是每种需求类型的英文缩写,理解它们有助于更好地记忆和运用这个模型。

计算Better-Worse系数
Better-Worse系数是量化分析的重要指标,可以帮助评估功能对用户满意度。
Better系数(满意度提升指数):
Better = (A + O) / (A + O + M + I)
正向驱动作用:该系数越接近1,表示功能对用户满意度的提升作用越显著。例如,若某功能的Better系数为0.8,说明其存在能直接刺激80%的用户产生正向反馈。
Worse系数(不满意度系数):
Worse = -1 * (O + M) / (A + O + M + I)
负向惩罚效应:该系数越接近-1,表明功能缺失时用户不满情绪越强烈。例如支付功能的Worse系数若为-0.9,说明若取消该功能,90%的用户会产生负面评价。


第一象限为期望属性,Better值高,Worse值绝对值高。该象限的功能应优先满足;
第二象限为魅力属性,Better值高,Worse值绝对值低。该象限的功能应优先满足;
第三象限为无差异属性,Better值低,Worse值绝对值低。该象限的功能通常不提供;
第四象限为必备属性,Better值低,Worse值绝对值高。该象限的功能一定需要满足。
其他
为什么排除 R (Reverse) – 反向型需求?
R型需求的性质:用户不喜欢这个功能,甚至希望没有它。提供该功能会降低他们的满意度,不提供他们反而觉得正常或开心。
与系数计算的冲突:
Better系数(提供功能带来的满意度提升):对于R型需求,提供功能只会带来下降的满意度(负面效果),根本谈不上“提升”。计算一个“负面效果”的“提升指数”在逻辑上是矛盾的。
Worse系数(不提供功能带来的满意度下降):对于R型需求,不提供功能用户并不会不满意,甚至可能更满意(正面效果或无效)。计算一个“正面效果”的“不满意度”同样逻辑不通。
结论:Better-Worse系数是为“提供会加分,不提供会减分”的常规功能设计的度量尺。而R型需求是“提供会减分,不提供可能加分”的异常功能,这把尺子无法测量它。对于R型需求,正确的做法是直接注意到它,并避免开发该功能。
为什么排除 Q (Questionable) – 可疑结果?
Q型结果的性质:这不是一种需求类型,而是指用户的回答在逻辑上自相矛盾、无效。例如:
用户对正向问题选“我很喜欢”,对反向问题也选“我很喜欢”。既喜欢有这个功能,又喜欢没有这个功能?这不合逻辑。
用户对正向问题选“我很不喜欢”,对反向问题也选“我很不喜欢”。既不喜欢有这个功能,也不喜欢没有这个功能?同样不合逻辑。
与系数计算的冲突:Q型结果代表的是无效数据或噪音数据。在进行任何严肃的数据分析时,第一步都是数据清洗,即剔除这些明显不真实、不可靠的答卷。将无效数据纳入计算会污染最终结果,导致系数失真,失去指导意义。
结论:Q不是需求,是“垃圾数据”。计算前必须被清理掉,因此自然不会参与计算。
优劣势
优势
在验证自己的想法时可以找业务团队做这样的问卷调查。例如:你觉得某个功能很有价值,那么此时就可以发起这样的一个问卷。这很容易让我认为这很适合汽车,汽车的功能非常分明,功能貌似也没有这么多,例如可以调研如果让用户加5000选择座椅通风加热用户的态度。
劣势
需要通过调研,让用户回答问题来得知这个需求应该归类于哪一个类别。
系统需求比较凌乱,分散,如果各个点都这样处理,业务估计会疯,每次提需求都要填写一遍问卷,对每个需求存在和缺失的时候的不同情绪反应。
另外,问卷的真实性也难以把控。
也忽略了期望实现时间、技术实现的可行性、开发成本等因素。
也有说需要和其他模型搭配使用的,这也是一个合理的使用方法。
我参考的模型——RICE
RICE是什么?
RICE是一个首字母缩写词,代表评估一个创意、功能或项目的优先级的四个关键因素:
- Reach(覆盖范围)
- Impact(影响力)
- Confidence(信心度)
- Effort(投入精力)
通过将前三个因素相乘,再除以第四个因素,得到一个最终的RICE分数。分数越高,意味着该项目的优先级越高。
核心计算公式:
RICE Score = (Reach × Impact × Confidence) / Effort
RICE四个维度的详细解读
1. Reach(覆盖范围)
定义:在特定时间段内,受该项目影响的用户(或客户)数量。
核心问题:“这个功能会影响到多少人?”
如何衡量:
通常以一个时间周期为单位,如“每季度”或“每年”。
根据项目性质,可以选择不同的指标:
面向用户的新功能:可能使用“受影响的活跃用户数”。
转化功能:可能使用“预计会看到新登录页的访问者数量”。
内部工具:可能使用“每周使用该工具的团队成员数量”。
要点:尽量使用实际数据(如 analytics数据)进行估算,避免猜测。它是一个数量而非百分比。
2. Impact(影响力)
定义:项目对每个个体用户(在Reach范围内)所能产生的积极影响程度。
核心问题:“这个功能对每个用户有多大价值?”
如何衡量:
由于影响力难以精确量化,RICE模型建议使用一种分级估算的方法:
- 3=巨大影响(Massiveimpact)
- 2=高影响(Highimpact)
- 1=中等影响(Mediumimpact)
- 0.5=低影响(Lowimpact)
- 0.25=极小影响(Minimalimpact)
要点:这是一个估算值,用于相对比较。例如,一个核心功能的优化可能被评为“3”,而一个界面微调可能只有“0.5”。
3. Confidence(信心度)
定义:你对Reach、Impact这2个估算值的确信程度,用于降低不确定性带来的风险。
核心问题:“我们对这个功能估算有多大把握?”
如何衡量:
使用百分比形式,但通常也转换为一个系数:
- 100%=高信心(Highconfidence)->系数为1
- 80%=中信心(Mediumconfidence)->系数为0.8
- 50%=低信心(Lowconfidence)->系数为0.5
系数为0.25(或更低),通常这类项目需要先做研究再评估。
要点:如果你对某个项目的估算缺乏数据支持,全是假设,那么就应该给它一个很低的Confidence值,从而降低其总分,避免高估一个不确定的项目。
4. Effort(投入精力)
定义:完成整个项目所需的所有“人天”投入(通常是整个产品/开发团队的工作量)。
核心问题:“完成这个项目需要多少工作量?”
如何衡量:
以“人-月”(person-months)或“人-周”(person-weeks)为单位。
例如,一个项目需要1个开发人员全职工作2个月,就是 2人月。如果2个开发人员一起工作1个月,也是2人月。我个人比较倾向于人天的计算,一个月/周也不知道算多少天,按天就没有这个误解。
应包含整个项目周期的投入:设计、开发、测试、部署等。
要点:Effort是分母。这意味着,在其他因素相同的情况下,需要投入越多精力的项目,其优先级分数越低。这有助于青睐那些“高性价比”的快赢项目。
如何使用RICE模型
假设你是某内容平台的产品经理,正在评估两个新功能:
功能A:推出一个“文章自动目录”功能,帮助读者快速导航长文章。
功能B:开发一个“创作者收入数据分析面板”。
步骤一:为每个功能估算四个维度
功能A:文章自动目录
- Reach(覆盖范围):每月有1000万篇长文被阅读。我们预计80%的读者会看到这个目录。所以Reach=8,000,000/季度(假设按季度算)。
- Impact(影响力):这个功能能显著提升阅读体验,但不是革命性的。评为2(高影响)。
- Confidence(信心度):我们有充分的A/B测试数据证明用户喜欢此类功能。评为100%(系数为1)。
- Effort(投入精力):需要前端和后端开发,预计2个开发人员工作1个月。Effort=2人月。
功能B:创作者收入面板
- Reach(覆盖范围):知乎每月有10万活跃创作者。预计所有创作者都会使用。Reach=100,000/季度。
- Impact(影响力):对创作者来说,清晰了解收入至关重要,能极大提升创作动力。评为3(巨大影响)。
- Confidence(信心度):我们不确定创作者具体会如何使用这些数据,估算基于假设。评为80%(中信心,系数0.8)。
- Effort(投入精力):涉及复杂的财务数据整合和可视化,安全要求高。预计需要3个开发人员工作3个月。Effort=9人月。
步骤二:计算RICE分数
- 功能A的分数=(8,000,000×2×1)/2=8,000,000
- 功能B的分数=(100,000×3×0.8)/9=(240,000)/9≈26,666
步骤三:比较并决策
功能A的分数(8,000,000)远高于功能B(26,666)。尽管功能B对单个用户的影响更大,但功能A能以相对较小的成本影响到海量用户,性价比极高。因此,根据RICE模型,应优先开发“文章自动目录”功能。
RICE模型的优劣势
优势:
- 综合性:考虑了影响的广度(Reach)和深度(Impact),同时平衡了成本(Effort)和风险(Confidence)。
- 客观性:减少了个人偏好和“谁嗓门大谁赢”的情况,使决策过程更加数据驱动。
- 凸显性价比:通过将Effort作为分母,天然地倾向于那些“小投入、大回报”的项目。
- 透明性:整个计算过程是透明的,团队可以讨论和挑战每个维度的估算值,从而达成共识。
劣势:
- 垃圾进,垃圾出(Garbagein,garbageout):如果估算值本身很随意,结果也毫无意义。需要尽力基于数据和经验进行估算。
- 可能忽略战略价值:RICE是战术工具,一个对公司战略至关重要的项目(如合规性要求)可能分数很低,但仍必须做。此时不应盲从分数。
- 估算工作量:对Effort的准确估算本身就是一个挑战,需要技术团队的深入参与。
- 比较范围:最好在同类项目之间比较(如都是产品功能优化),而不是对比一个营销活动和一个底层架构重构项目。
本文由@Bruce 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。















