

本文第一作者庄湛,香港城市大学和南方科技大学联合培养博士生,研究方向是迁移学习、扩散模型、大模型微调等。本文通讯作者魏颖,浙江大学「百人计划」研究员,博士生导师,研究方向包括持续学习、迁移学习、组合泛化以及在科学领域中的应用等。通讯作者张宇,南方科技大学副教授,研究方向包括深度学习、多任务学习、迁移学习、元学习以及在计算机视觉和自然语言处理方面的应用。
还在为 LoRA 训练不稳定、模型融合效果差、剪枝后性能大降而烦恼吗?来自香港城市大学、南方科技大学、浙江大学等机构的研究者们提出了一种简单的渐进式训练策略,CoTo,通过在训练早期随机失活一部分适配器,并逐渐提高其激活概率,有效缓解了层级不均衡问题,并显著增强了模型在多任务融合和剪枝等操作上的鲁棒性和有效性。该工作已被机器学习顶会 ICML 2025 接收。

- 论文标题:Come Together, But Not Right Now: A Progressive Strategy to Boost Low-Rank Adaptation
- 论文链接:https://openreview.net/forum?id=Zha2m39ZoM
- 代码仓库:https://github.com/zwebzone/coto
- 官网海报:https://icml.cc/virtual/2025/poster/44836
常规 LoRA 训练的隐藏缺陷
参数高效微调技术已成为预训练大模型在下游任务应用的关键技术。然而,尽管 LoRA 如此成功,它依然面临着一些棘手的问题:
1. 「惰性训练」(Lazy Training):LoRA 的优化过程常常会陷入初始化点附近的次优解,限制了模型的泛化能力。
2. 层级不平衡:在训练中,梯度更新往往集中位于模型的顶层适配器,导致底层适配器训练不足,整体性能受限。
3. 下游操作困难:上述问题使得多个 LoRA 模型的融合和剪枝等下游操作变得非常困难,效果常常不尽人意。
CoTo 策略:何不让 LoRA 「渐入佳境」?
为了解决这些挑战,研究者们提出了 CoTo,其核心思想非常简洁直观:在训练初期,不必让每一层的训练 「一拥而上」,而是让 LoRA 适配器 「循序渐进」 地参与训练。具体来说,CoTo 采用了一种渐进式的激活策略:
- 训练初期:以一个较高的概率随机 「失活」 一部分 LoRA 适配器。这迫使模型在更新时不能过分依赖某几层,从而让梯度更均匀地流向所有层级,鼓励模型探索更广阔的参数空间。
- 训练中后期:线性地提高适配器的激活概率,直到所有适配器都完全参与训练,回归到标准的微调模式。
这种 「先抑后扬」 的策略带来了诸多好处:它不仅促进了层级间的均衡优化,还显著提升了不同随机种子训练出的模型之间的线性模式连通性 (Linear Mode Connectivity, LMC) 和 Dropout 稳定性,为模型融合与剪枝打下了坚实的基础。

图 1:CoTo 渐进式激活示意图。训练初期(t <3T>
实验结果
CoTo 最令人兴奋的贡献在于它极大地提升了 LoRA 模型的融合和剪枝能力,且 CoTo 本身也能在单任务的泛化性能和训练效率上带来提升。
更有效的模型融合
- 线性插值准确率:在常识推理与图像分类任务中,对两个独立训练的 LoRA 模型进行线性插值时,标准 LoRA 的性能在融合点 (λ=0.5) 会急剧下降。相比之下,CoTo 模型展现了优越的线性模式连通性 (LMC),在整个插值路径上均能保持平滑且高效的性能过渡。
- 多任务 LoRA 融合:在 GLUE 数据集上,无论是基于 LLaMA-2 (7B, 13B) 还是 DeBERTa-v3 模型,通过 CoTo 训练的 LoRA 模块在进行多任务合并时,其准确率均稳定超越了使用常规训练方法融合的基线模型。

图 2:常识推理任务的线性插值准确率。
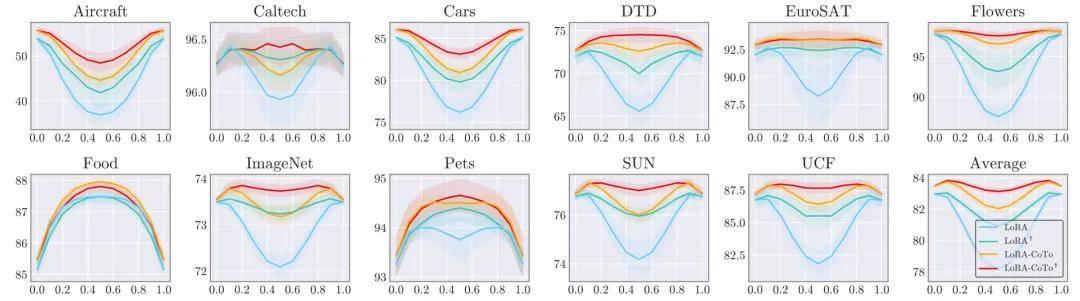
图 3:图像分类任务的线性插值准确率。
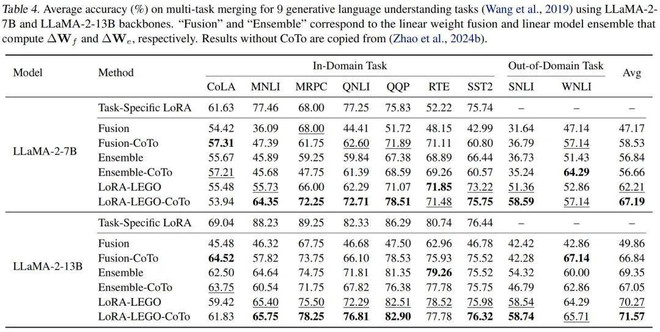
图 4:使用 LLaMA-2-7B 和 LLaMA-2-13 模型进行多任务 LoRA 融合的准确率。
更鲁棒的模型剪枝
CoTo 的训练方式天然地增强了模型的剪枝容错能力。如下图所示,无论是在移除交替层、底层、中层还是高层适配器的结构化剪枝中,还是在不同稀疏度的非结构化剪枝中,CoTo-LoRA 的性能都全面超越了标准 LoRA。

图 5:结构化剪枝对比(左)和非结构化剪枝对比(右)。
性能与效率双提升
- 性能更强:在涵盖视觉(11 个图像分类任务)、语言(8 个常识推理任务)和数学推理等多个领域的基准测试中,CoTo 都能稳定地提升包括 LoRA、DoRA、HiRA 在内的多种 LoRA 变体的性能。
- 训练更快:由于在训练早期跳过了部分适配器的计算,CoTo 还能降低训练开销。例如,在 HiRA 上应用 CoTo,可以实现超 24% 的训练加速!
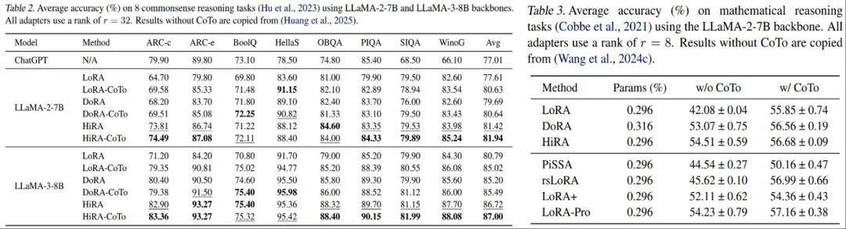
图 6:在常识推理和数学推理上,基于不同 LoRA 变体和训练策略的性能提升。
消融实验
为了验证 CoTo 各个设计选择的合理性并探究其性能提升的根源,研究团队在训练阶段比例、激活概率曲线、嵌套 Dropout 策略、学习率和 LoRA rank 等多个方面进行了一系列严谨的消融实验。这些实验不仅证明了 CoTo 设计的合理性,也为我们提供了关于如何有效正则化 LoRA 的深刻见解。
令人欣喜的是,CoTo 的代码实现十分简洁,用户只需对现有 LoRA 训练流程做三步改动即可利用这一策略,感兴趣的读者可以访问代码仓库,亲自体验 CoTo 的效果!
总结
CoTo 通过一个简单而巧妙的渐进式训练策略,有效解决了 LoRA 训练中的层级不平衡和 「懒惰」 优化问题。它不仅提升了模型的单任务泛化能力,更重要的是,它极大地增强了 LoRA 适配器的可组合性与鲁棒性,让模型融合与剪枝等下游操作变得更加简单高效。CoTo 无需修改模型架构,可以作为即插即用的模块与各类 LoRA 方法无缝集成。文章中还提供了渐进优化和合作博弈两个角度深入分析了 CoTo 带来的优势。我们相信,这项工作将为参数高效微调领域的研究与应用带来新的启发。

















喝点红酒
还睡觉睡觉