
最近模型圈大家关注度最高的莫过于Grok4以及Kimi K2,作为一个AI应用开发者,我们一直都时刻关注最新的模型能力表现,因此今天三白花了一天左右的时间先深入研究和实测一下K2的表现,看有没有媒体吹嘘的那么牛。
本篇内容主要从K2的模型亮点、K2与主流模型综合能力对比、K2实际应用效果测试三个角度,探探K2大概是什么水平。

一句话概括全文:
Kimi K2的代码编程、智能体agent、数学推理方面表现出色,已经接近第一梯队的顶尖模型,但是在多模态、指令遵循方面依然表现不佳,综合性能距离OpenAI、Gemini、Claude系列顶尖模型,还有差距。
一、K2的核心能力亮点
概括起来讲,K2这次在模型层能力的突破,主要聚焦在代码编程、智能体、数学推理这三个方面,达到了非常优秀的水平,也因此引起了AI技术圈的关注。
1. 编程与代码生成能力:全球仅次于claude 4 sonnet的编程模型
编程能力目前是K2主打的第一个能力亮点,目前K2的编程代码能力或许全球仅次于claude 4 sonnet。
对于模型在编程代码领域的表现的测试,主要通过SWE-bench 、LiveCodeBench v6、OJBench这几项测评来测试,K2的实际测评结果如下:
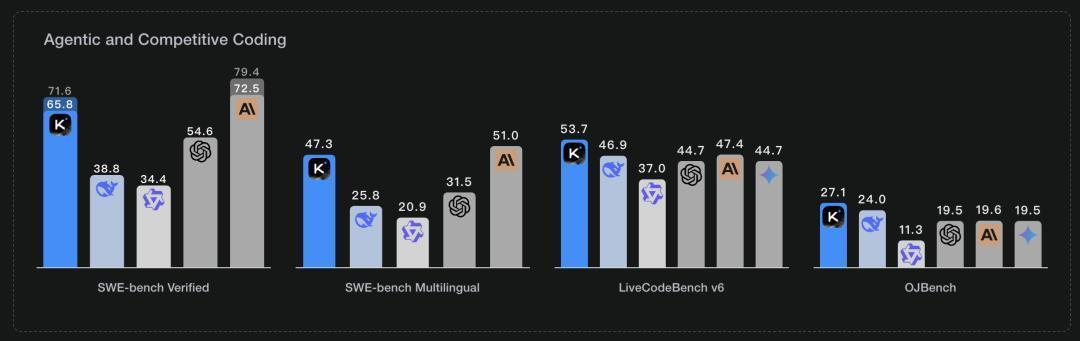
怎么理解上面各项测评内容及测试结果的含义?
以下的三个测评项目主要评测模型在实际解决github的代码问题、非英语代码库问题、编程面试、算法竞赛等方面的表现,是国际公认的评估模型代码编程能力的测评项目,从实际测评结果上看K2的表现可谓相当的不错。

K2目前的编程能力,在全球大模型里面属于什么水平?
由于上图测评结果为Kimi自己公开的数据,对比对象是官方自己挑选的,也存在可能没有把部分更强大的模型也放进去对比的嫌疑,所以如果放到全球所有模型上去对比,K2的编程能力是一个什么样的水平?
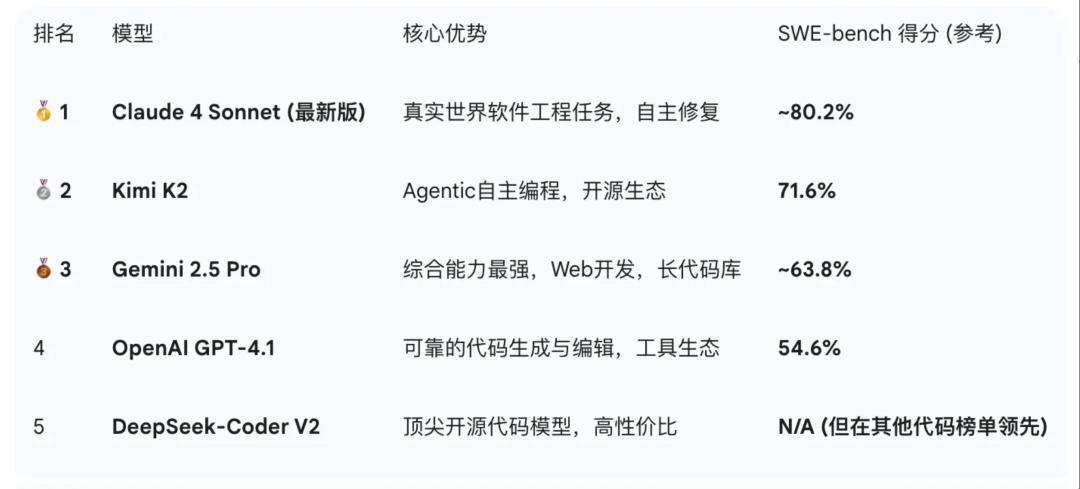
以SWE-bench得分作为参考,目前得分top5的模型从高到低包括:Claude 4 sonnet、K2、Gemini 2.5 Pro、GPT4.1、deepseek-coder V2.
目前K2的编程能力,全球可能仅此于claude 4 sonnet,甚至可能超过Gemini 2.5 pro。
编程能力在应用层的价值是什么?
编程能力直接影响模型在程序员编程、应用和网页开发的应用落地的质量,同时也是智能体表现的基础。
2. 智能体能力仅次于Claude 4和GPT 4.1
K2对外宣称的另一个核心能力亮点是智能体的应用能力,也就是实际解决一个应用场景的任务的能力,该能力的表现主要从任务规划拆解、工具调用、自动编码和执行代码的能力。
- 智能体任务:K2具备执行复杂的、多步骤的任务的能力,包括任务拆解、自主规划,工作流设计以及工具调用能力;
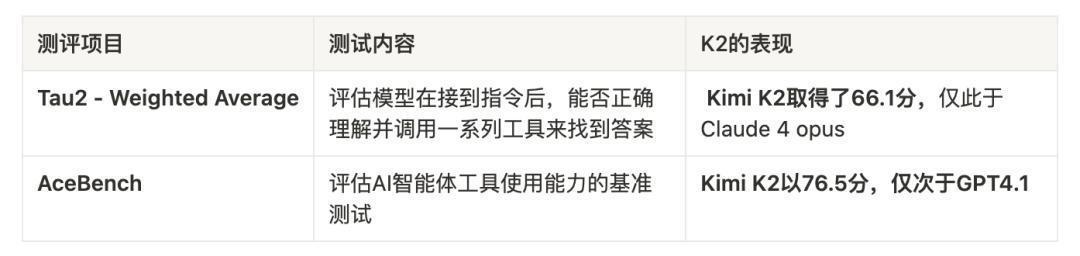
- 工具使用:模型原生支持强大的工具调用能力,开发者可以轻松地将自己的API或工具集(如搜索、日历、预定系统等)接入KimiK2,模型能够理解并自主使用这些工具来完成任务。官方演示中,KimiK2能通过连续17次工具调用来规划一场完整的演唱会之旅。
- 自动化编码:开发者可以将KimiK2接入到各种Agent或编码框架中,实现高度自动化的编码。例如,它可以自主完成数据分析、生成可视化图表,并将结果打包成一个交互式网页。
对于其智能体能力表现的测评结果,KIMI官方公开的测评数据如下:
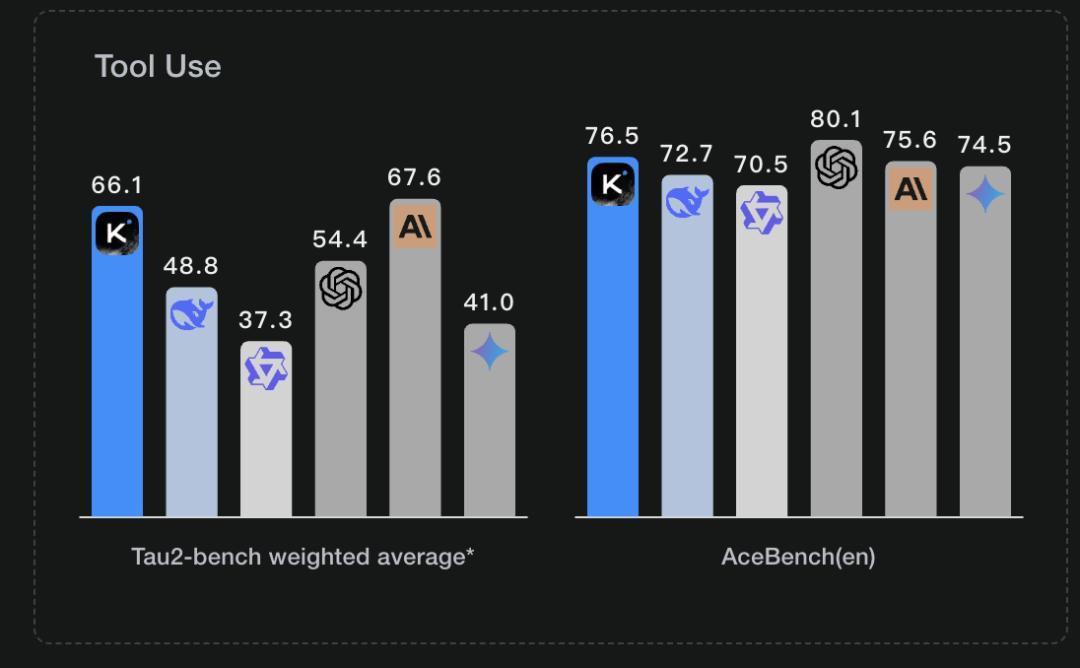
测评内容及测试结果的含义
从测评数据上看,K2目前的智能体水平可能也仅次于Claude 4以及GPT4.1,也已经是一个比较不错的水平。
智能体能力在应用层的价值是什么?
它体现在解决具体的AI应用落地效果,以及实际解决具体的任务时的表现,智能体能力约强大,越能满足用户的实际应用请求。
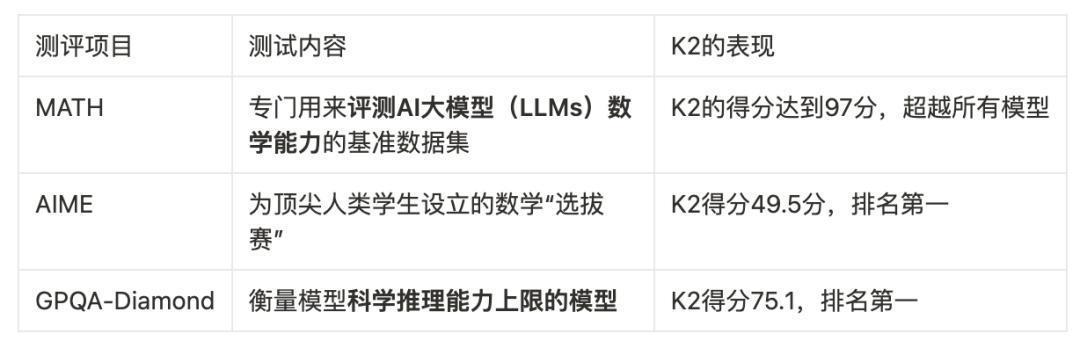
3. 数学推理能力:全球最强
K2目前是全球模型中数学推理能力最强的模型,在MATH、AIME、GPQA-Diamond多项测评中,目前都是得分最高的模型,这三个测试项目分别为专门针对大模型数学能力的专业测评、以及美国为顶尖人类学生设立的数学竞赛试题、以及衡量模型科学推理能力上线的测试模型,而K2在每一项测试中的得分均是最高的。
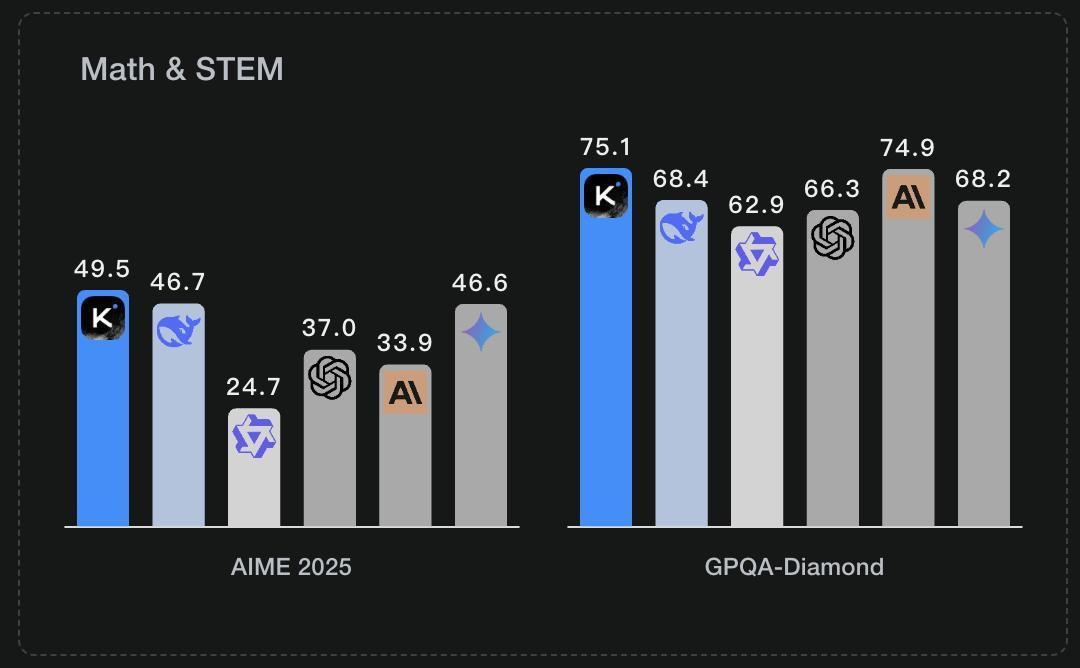
数学推理领域全球top5的模型有哪些?
当下全球模型在数学推理领域top5的模型主要包括:K2、Gemini2.5 pro、R1、GPT4O或O3、Grok3/4.
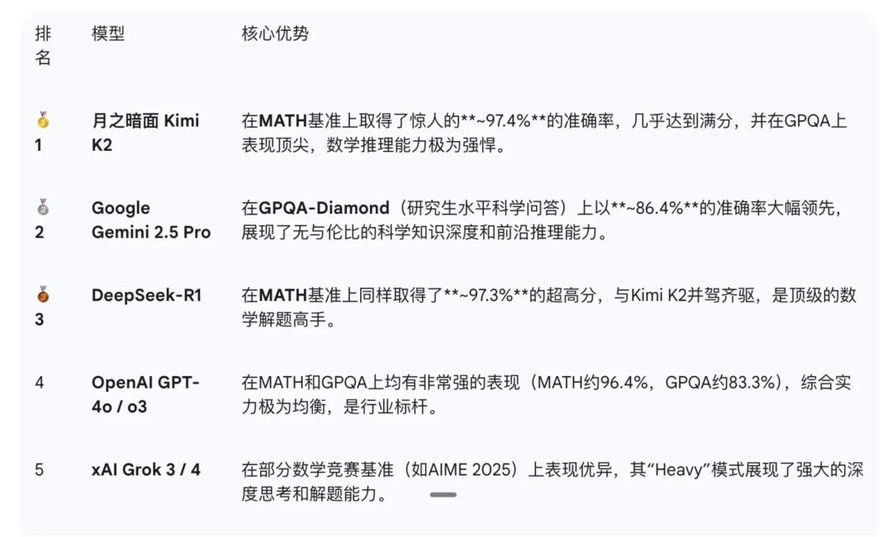
数学推理能力在应用层的价值是什么?
体现在数据分析、数学教学等包括金融、教育等很多通用领域的应用效果。
二、K2与主流模型综合能力对比
然而,一个模型最后要能够被更好的落地到应用层,光看代码编程、智能体、数学推理这三个方面是肯定不够的,K2在这几个单点能力上的表现,只能说在部分应用领域里面,表现会更好,但是放到很多通用应用场景里面表现不一定真的那么出色。
评估一个模型最后的应用落地效果,要从如下多个维度评价,其中个人总结为6个维度:
- 推理能力:包括深度思考、数学推理、科学推理等;
- 代码生成能力
- 智能体能力:包括任务规划、代码执行、工具调用等;
- 精确指令遵循
- 文本理解与创作
- 多模态理解和生成能力
目前K2的模型发展路线,是聚焦在模型的“行动和执行”能力上,然而在多模态的理解生成,以及指令遵循等方面,表现效果却还是相对一般(这个在第三部分应用测试中会体现出来);
而Gemini 、OpenAI等顶尖模型不同的是,这些模型选择在优先侧重模型的推
理和思考能力的同时,不断地强化以上其他领域的能力,因此其达到了综合能力超强的模型水平。
所以,从应用开发者和AI应用使用者的角度上看,目前要真正能投入应用或者达到足够高的AI应用满足度,目前还得是使用OpenAI、Gemini等系列模型,根据个人目前的理解,在模型和应用选型上,我依然还是会优先考虑GPT/O系列、Gemini 2.5 Pro、R1,而K2可能会作为其中部分场景的平替。
三、应用实测效果对比:K2、Gemini、DS、豆包
前面两部分说了那么多,大部分结论都是基于官方公开和行业测评的结果得出的,到底是不是真的好用,实测一下才知道。
因此这部分我主要实际体验一下K2的效果,我还是拿我平时应用场景最多的阅读和网页生成这两个应用场景为例,对K2做一下测试;
由于目前这两个场景我在Gemini 2.5 Pro已经得到很好的满足,因此实际效果将对比Gemini 2.5 Pro,同时也和我平时最常用的豆包、deepseek两个模型做一下对比。
测试场景1:文档阅读场景
提示词如下:
该段提示词的目标是希望对用户上传的文档做精读处理并结构化输出精读摘要。
***Role***
你是一个擅长阅读提取关键信息的专家,请阅读我提供的文档,并为我生成一份结构化的精读总结。
***Background***
我需要对这个{我上传的文档},AI生成一个结构化的精读报告,能遍历整个文档并提炼每一个段落内的要点信息,方便我快速的掌握长文本的内容。
***Goals***
-根据用户提供的文档,梳理文档的大纲结构,并完整的阅读文档中的每一个段落,不错过文档中的每一个段落的信息,为了确保没有遗漏,你需要告诉我你阅读了多少页内容;
-从每个最小粒度大纲对应的段落内容中,总结提炼3~5个核心观点和结论,并总结每个结论背后的依据,注意核心观点和结论不能低于3个,请不要偷懒省略内容,这个很重要;
-最终生成一篇精读总结,目标是让用户能快速且详尽的掌握长文的核心信息;
***Constrains***
1.绝对不要忽略长文中的任何一个章节的内容,需要确保每一个章节内容都阅读和总结到;
2.每一个最小粒度大纲下总结的核心结论不可低于3个,不要自行删减和省略段落中的部分内容;
3.文档中如果有表格和数据,请提取其中的表格和数据并保留下来原始表格;
4.总结的时候采用金字塔原理,先总结结论,然后列举依据和要点,分点陈述;
5.请保留原文的大纲内容,不要做总结、截取等操作;
6.核心观点和依据输出的时候,不需要带有“核心观点”“依据” 这两个前缀;
8.论据中的表格部分,不需要带“原文完整表格如下”这个前缀;
***Skills***
1.擅长阅读总结并提取核心信息;
2.具备超强的逻辑能力和结构化思维,擅长做逻辑表达和结构化表达;
3.具备用户同理心,知道读书的用户的需求;
以“2025种草爆点透视内容营销洞察报告”这篇报告作为上传的报告文档,并且为了检验模型的陷阱识别和多模态能力,我故意把报告的标题修改为“100页长文”,实际报告只有28页.

1.Gemini 2.5pro 对比 Kimi K2:Gemini 2.5Pro优于K2
以下依次分别为Gemini 2.5 Pro和K2的生成效果,对比两者的效果差异,效果评判如下。
图1:Gemini 2.5 Pro生成结果

图2:K2生成结果

1. 在陷阱识别上:Gemini 2.5Pro并没有被100页这个标题欺骗,而是准确的计算出来28页,而K2一开始就算错了,直接把标题中的100页作为报告长度,从这个角度上看,可以看出来,很显然K2在多模态理解的能力、以及幻觉率方面,必然是不如Gemini 2.5Pro;
2.在多模态理解能力上:Gemini 2.5Pro基本非常准确的获取了这个扫描件的PDF报告的内容,并且以近乎还原报告原始全部内容的方式,输出了结构化的精读摘要,其识别能力如何我们最简单的看报告的主题是否被精准识别出来即可;

显然Gemini 2.5Pro做到了,可见其准确识别并理解了扫描件的内容。而K2输出的结果,首先连报告的主题都没有识别出来,最后只能根据自己的理解自己捏造一个,其次实际总结的结果中,有大量的信息丢失,最后输出结果基本和原文观点和信息已经对应不上,所以,可以说是一个不合格的解读结果。
3.在指令遵循上:以提示词中要求不要遗漏信息、保留原始表格数据、金字塔原理方式表达等为例,Gemini 2.5Pro 无一例外的都做到了,而K2全部都没有遵循,可见模型的指令遵循方面也不行;
综上看,至少在文档阅读领域,K2并没有达到可以用于落地应用的水平,其核心的制约点主要在多模态理解能力,指令遵循和幻觉率方面。
2.Kimi K2 对比豆包、deepseek:deepseek > k2 > 豆包
对比完K2和Gemini 2.5Pro,我们再来对比一下K2和豆包、Deepseek的效果差异,同样的指令通过豆包执行,输入结果如下。

很显然,豆包最终的输出结果基本是失败的,没有输入任何有效的信息,只提取了一部分扫描件的无用文字信息,显然豆包基本没有识别提取出文档的任何信息,这点我也比较费解,因为以前在我的影印象里,豆包的多模态理解能力还是很不错的,可以准确的提取很多扫描件PDF的信息,最近发现又不行了,这样看来的话,K2的能力至少比豆包还是更好的;
接着,再测试一下用deepseek,DS的表现并不差,其生成结果基本符合要求,并且内容基本还原报告原文的内容,所以效果比K2更好,但是还是输给Gemini 2.5 Pro,比如Gemini能按照要求输出原始表格数据,而DS没有做到。
图:DS生成效果

测试场景2:网页生成
1.Gemini 2.5pro 对比 Kimi K2
接着,我们以前面测试生成的精读文本,让两者生成HTML,对比效果,看两者在代码生成方面的表现,提示词如下:
***Role***
你是一个网页设计师,帮我将我提供给你的内容生成一个精美的HTML静态网页;
***Goals***
-我将给你一段已经经过精读处理的内容,帮我将它生成一个可视化的卡片网页,注意保留原文信息,不要做概括处理以及省略信息;
***Constrains***
1.该段内容我已经经过概括处理,请生成网页的时候不要做进一步的摘要总结,保留原始内容即可,只需要做美化,千万不要省略和去除其中的内容信息;
2.涉及数据的时候,请用图表呈现,具体用什么类型的图表你可以自己决定;
3.网页设计风格:整体网页背景用黑色,正常字体用白色,重点内容字体用红色,其余的你自己控制,目标是精美并符合专业设计师的审美标准;
如下两图为实际生成效果图,对比两者的效果可以看到,整体上Gemini 2.5Pro依然还是表现更强,主要体现在如下3点:
- Gemini2.5Pro生成的网页可以生成图表等元素,而K2基本只有文字,这可能也还是因为K2在多模态方面的劣势;
2.整体设计感和排版布局方面,也是Gemini 2.5Pro更好;
3.Gemini 2.5 Pro 遵循指令,基本保留了原始文本的信息,没有省略太多,而K2省略丢失了很多信息,这同样还是指令遵循的问题,因为从单次输出长度上,Gemini 2.5Pro和K2都在6万token左右,并不是单次输出长度的限制。
图1:Gemini 2.5 Pro 生成结果

图2:K2生成结果如下:
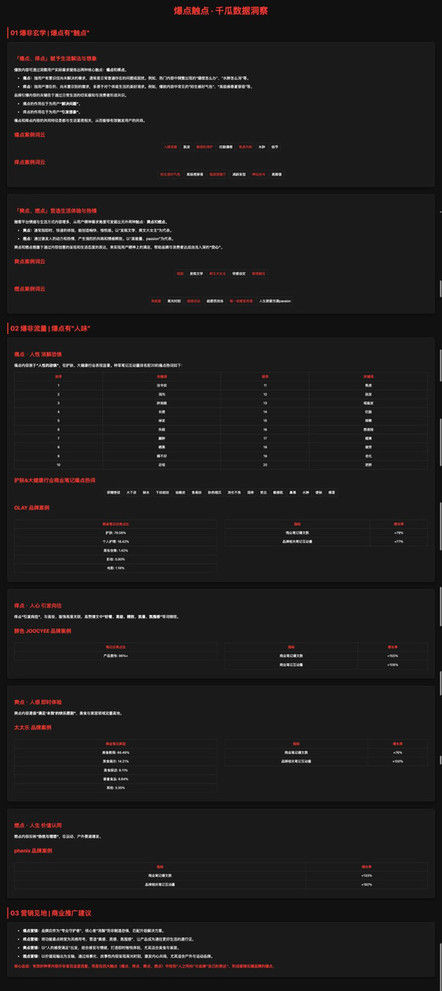
2.K2对比豆包和DeepSeek
接着再对比一下K2和豆包、DS的生成结果差异,以下图1为豆包生成的结果,整体上并不太让人满意,虽然排版布局反面和K2也差不多,但是网页中出现了很多空白的模块及异常;
图2是deepseek的生成结果,DS的表现很不错,并且不输给K2,已经比较接近Gemini 2.5 pro 的水平,但是依然无法生成图表,所以相比之下还是Gemini 2.5 pro 更优。
因此,从网页生成效果而言,在这个案例中,整体效果:Gemini 2.5 Pro > Deepseek >K2 >豆包。
图1:豆包生成结果

图2:DeepSeek生成结果

总结一下
总结而言,在实际的应用场景中,K2确实在代码编程方面表现还是不错的,有较高的完成度,在国内可能跟DeepSeek在大部分编程场景也相差不大,当然今天列举的案例可能比较简单,看不出太大差异,可能在一些更加复杂的编程场景下,差距会明显看出来,K2可能效果会更突出;而对比海外,目前看实际效果可能也就是接近但是没有超越Gemini 2.5 pro;
另外K2在实际应用的过程中,也显现出来其在多模态理解和生成、指令遵循、幻觉等方面的一些明显的劣势。
所以,站在使用AI的用户的角度而言,通用应用场景我还是会优先选择ChatGPT、Gemini,部分特定场景,则是国内在豆包、元宝、kimi之间切换使用;站在应用开发者的角度,如果单纯从应用效果上看,OpenAI和gemini系列模型依然还是首选,K2或许会逐步成为替代方案。
作者:三白有话说,公众号:三白有话说
本文由 @三白有话说 原创发布于人人都是产品经理。未经作者许可,禁止转载。
题图来自豆包官网截图
















VoidRunner7
Kimi K2研究深入,实测数据很有参考价值!
VoidWalker_Z
Kimi K2的对比测试,干货满满,值得一看!
LunarShift
不得不说,Kimi K2的对比测试,是游戏玩家的福音!
ZetaByte
“数据!数据!数据!Kimi K2的K2,永远的神!”
NovaByte
感觉Kimi K2在给我科普游戏原理,这感觉太棒了
VoidWalker_Z
看完这个对比,我开始怀疑自己之前玩游戏是不是瞎了眼
ZetaByte
“Kimi K2的K2,就像我每天吃的K2咖啡,提神醒脑!”
NovaX_
“这数据,我感觉它在暗示我应该改变人生轨迹,我听你的!”
EchoVerse
Kimi K2,你真懂我!这才是真正的游戏深度
VoidWalker_Z
有点怪,但确实挺有意思的,就像看一场脑洞大爆炸