

今天凌晨,微软研究院开源了创新音频模型VibeVoice-1.5B。
不仅一次性合成90分钟超长语音(此前行业极限仅60分钟),更支持4人自然对话、3200倍音频压缩,彻底打破传统TTS(文本转语音)技术的天花板。
技术架构
VibeVoice首创了双语音tokenizer模块,声学tokenizer与语义tokenizer,两者各有分工又相互配合,为后续的建模提供高效压缩且语义与声学对齐”的混合特征。
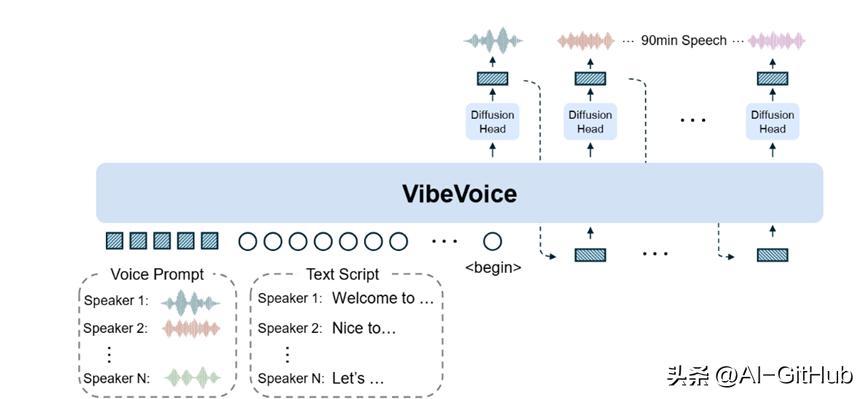
声学tokenizer承担保留声音特征并实现极致压缩的核心任务,其架构采用基于变分自编码器的对称编码-解码结构,这种设计既解决了数据多样性丢失,又通过层级化的下采样实现超高压缩率。
在模型训练与优化方面,VibeVoice采用课程学习策略将大语言模型的输入序列长度从初始的4096个token逐步增加到65536个token,对应24千赫兹采样率下90分钟的音频长度,避免模型因为一开始就处理超长序列而出现训练失败。
应用场景:
1.有声书与播客
超长内容一键生成:传统制作需多人录制、后期剪辑,而VibeVoice可基于脚本自动生成90分钟连贯语音,成本降低70%。
多语言无缝切换:支持中英文混合播报(如科技资讯中的术语实时翻译),背景音乐与语音动态平衡。
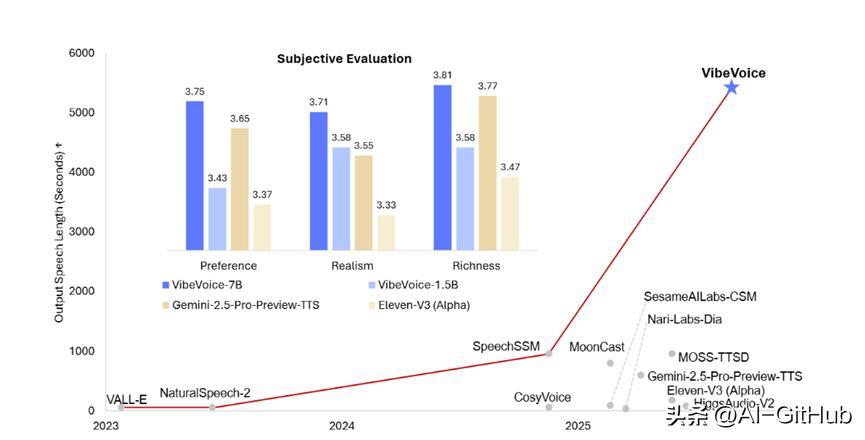
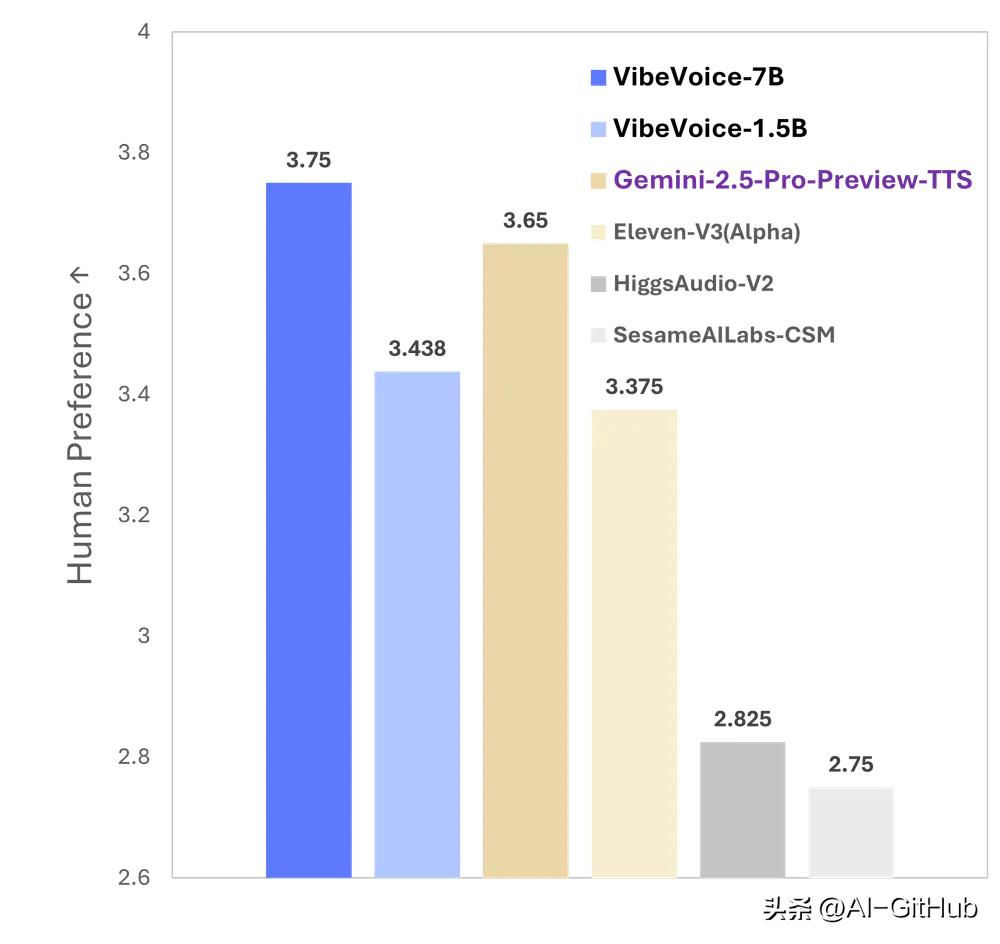
2.虚拟数字人与智能助手:情感化交互:AI助手可模拟“温柔提醒”“焦急警告”等情绪,告别机械式回复。测试显示,其语音真实感评分达3.75(满分5),超越Gemini、ElevenLabs等竞品。
3. 多语言翻译与跨文化传播
结合翻译技术,实现自然语音级多语言转换。例如,中文演讲可实时转化为带英式口音的英文音频,保留原说话人语调特征。
开源地址:
https://huggingface.co/microsoft/VibeVoice-1.5B
#AI开源项目推荐##github##微软开源#TTS语音模型
















