学术打假!清华上交大研究颠覆认知:强化学习竟是大模型推理的"绊脚石"
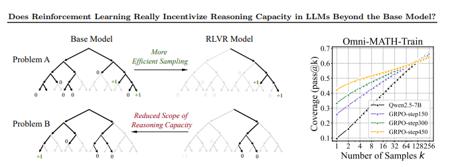
【研究颠覆】清华大学与上海交通大学联合发表的最新论文,对业界普遍认为"纯强化学习(RL)能提升大模型推理能力"的观点提出了挑战性反驳。研究发现,引入强化学习的模型在某些任务中的表现,反而逊色于未使用强化学习的原始模型。【实验验证】研究团队在数学、编码和视觉推理三大领域进行了系统性实验:数学任务:在GSM8K、MATH500等基准测试中,RL模型在低采样次数(k值)下准确率提升,但在高k值时问题覆盖
